
Hyperparameter optimization with approximate gradient

- scikit-learn 0.16
This package exports a LogisticRegressionCV class which automatically estimates the L2 regularization of logistic regression. As other scikit-learn objects, it has a .fit and .predict method. However, unlike scikit-learn objects, the .fit method takes 4 arguments consisting of the train set and the test set. For example:
>>> from hoag import LogisticRegressionCV >>> clf = LogisticRegressionCV() >>> clf.fit(X_train, y_train, X_test, y_test)
where X_train, y_train, X_test, y_test are numpy arrays representing the train and test set, respectively.
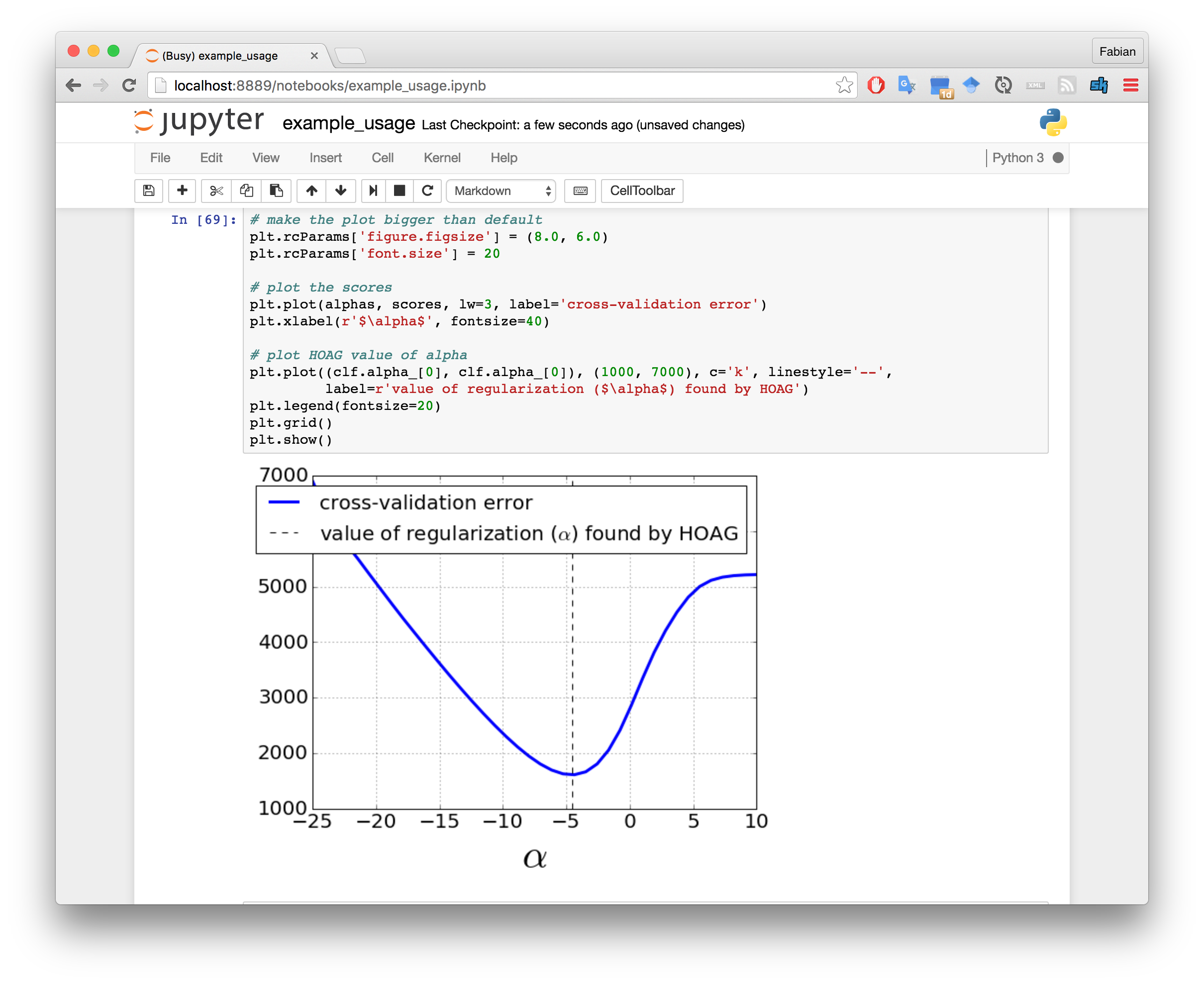
For full usage example check out this ipython notebook.
Standardize features of the input data such that each feature has unit variance. This makes the Hessian better conditioned. This can be done using e.g. scikit-learn's StandardScaler.
If you use this, please cite it as
@inproceedings{PedregosaHyperparameter16,
author = {Fabian Pedregosa},
title = {Hyperparameter optimization with approximate gradient},
booktitle = {Proceedings of the 33nd International Conference on Machine Learning,
{ICML}},
year = {2016},
url = {http://jmlr.org/proceedings/papers/v48/pedregosa16.html},
}