Releases: ultralytics/yolov3
v9.6.0 - YOLOv5 v6.0 release compatibility update for YOLOv3
This release merges the most recent updates to YOLOv5 🚀 from the October 12th, 2021 YOLOv5 v6.0 release into this Ultralytics YOLOv3 repository. This is part of Ultralytics YOLOv3 maintenance and takes place on every major YOLOv5 release. Full details on the YOLOv5 v6.0 release are below.
https://github.com/ultralytics/yolov5/releases/tag/v6.0
This YOLOv5 v6.0 release incorporates many new features and bug fixes (465 PRs from 73 contributors) since our last release v5.0 in April, brings architecture tweaks, and also introduces new P5 and P6 'Nano' models: YOLOv5n and YOLOv5n6. Nano models maintain the YOLOv5s depth multiple of 0.33 but reduce the YOLOv5s width multiple from 0.50 to 0.25, resulting in ~75% fewer parameters, from 7.5M to 1.9M, ideal for mobile and CPU solutions.
Example usage:
python detect.py --weights yolov5n.pt --img 640 # Nano P5 model trained at --img 640 (28.4 [email protected]:0.95) python detect.py --weights yolov5n6.pt --img 1280 # Nano P6 model trained at --img 1280 (34.0 mAP0.5:0.95)Important Updates
Roboflow Integration ⭐ NEW: Train YOLOv5 models directly on any Roboflow dataset with our new integration! (ultralytics/yolov5#4975 by @Jacobsolawetz)
YOLOv5n 'Nano' models ⭐ NEW: New smaller YOLOv5n (1.9M params) model below YOLOv5s (7.5M params), exports to 2.1 MB INT8 size, ideal for ultralight mobile solutions. (ultralytics/yolov5#5027 by @glenn-jocher)
TensorFlow and Keras Export: TensorFlow, Keras, TFLite, TF.js model export now fully integrated using
python export.py --include saved_model pb tflite tfjs(ultralytics/yolov5#1127 by @zldrobit)OpenCV DNN: YOLOv5 ONNX models are now compatible with both OpenCV DNN and ONNX Runtime (ultralytics/yolov5#4833 by @SamFC10).
Model Architecture: Updated backbones are slightly smaller, faster and more accurate.
- Replacement of
Focus()with an equivalentConv(k=6, s=2, p=2)layer (ultralytics/yolov5#4825 by @thomasbi1) for improved exportability- New
SPPF()replacement forSPP()layer for reduced ops (ultralytics/yolov5#4420 by @glenn-jocher)- Reduction in P3 backbone layer
C3()repeats from 9 to 6 for improved speeds- Reorder places
SPPF()at end of backbone- Reintroduction of shortcut in the last
C3()backbone layer- Updated hyperparameters with increased mixup and copy-paste augmentation
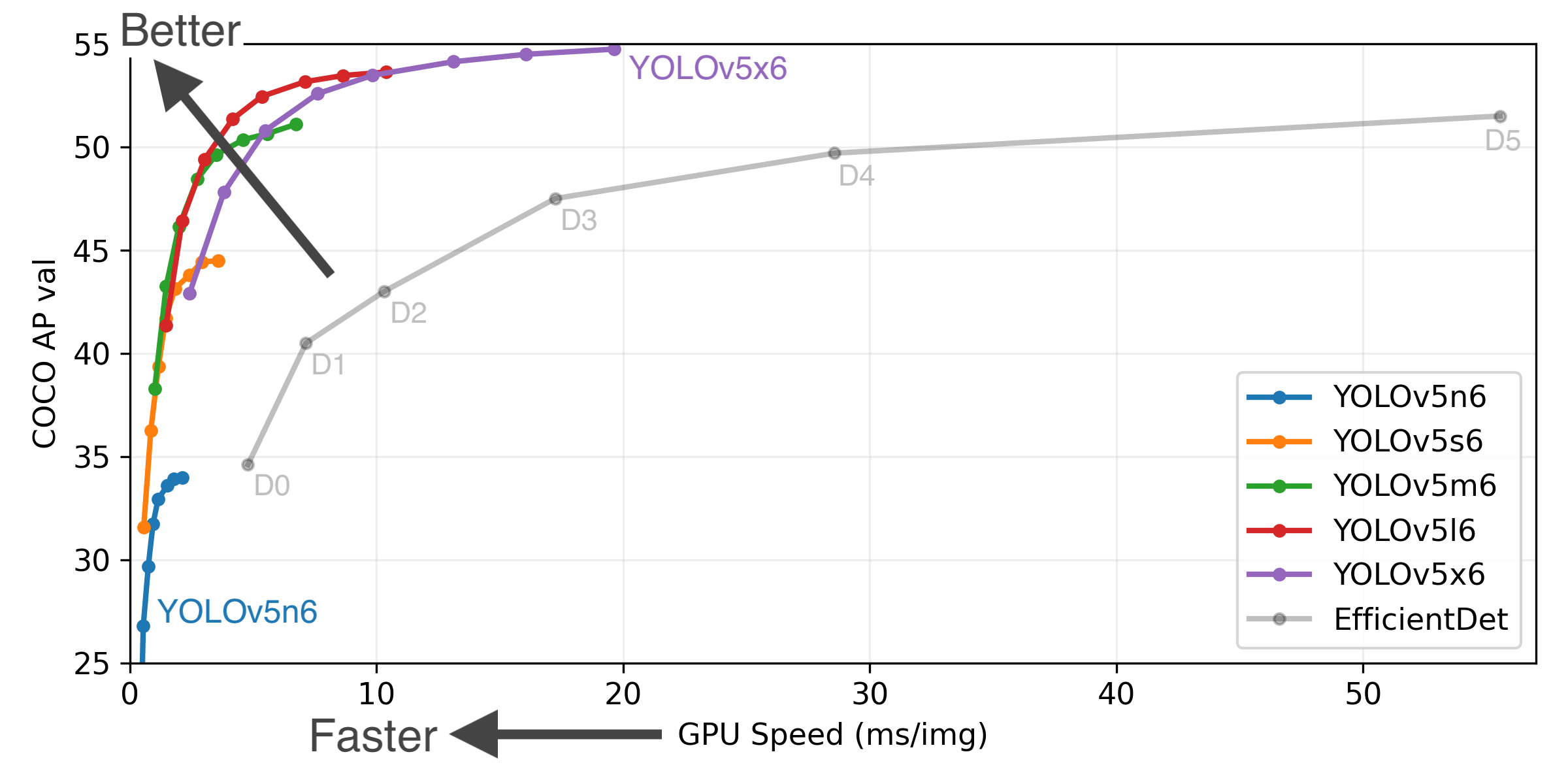
New Results
YOLOv5-P5 640 Figure (click to expand)
Figure Notes (click to expand)
- COCO AP val denotes [email protected]:0.95 metric measured on the 5000-image COCO val2017 dataset over various inference sizes from 256 to 1536.
- GPU Speed measures average inference time per image on COCO val2017 dataset using a AWS p3.2xlarge V100 instance at batch-size 32.
- EfficientDet data from google/automl at batch size 8.
- Reproduce by
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.ptmAP improves from +0.3% to +1.1% across all models, and ~5% FLOPs reduction produces slight speed improvements and a reduced CUDA memory footprint. Example YOLOv5l before and after metrics:
YOLOv5l
Largesize
(pixels)mAPval
0.5:0.95mAPval
0.5Speed
CPU b1
(ms)Speed
V100 b1
(ms)Speed
V100 b32
(ms)params
(M)FLOPs
@640 (B)v5.0 (previous) 640 48.2 66.9 457.9 11.6 2.8 47.0 115.4 v6.0 (this release) 640 48.8 67.2 424.5 10.9 2.7 46.5 109.1 Pretrained Checkpoints
Model size
(pixels)mAPval
0.5:0.95mAPval
0.5Speed
CPU b1
(ms)Speed
V100 b1
(ms)Speed
V100 b32
(ms)params
(M)FLOPs
@640 (B)YOLOv5n 640 28.4 46.0 45 6.3 0.6 1.9 4.5 YOLOv5s 640 37.2 56.0 98 6.4 0.9 7.2 16.5 YOLOv5m 640 45.2 63.9 224 8.2 1.7 21.2 49.0 YOLOv5l 640 48.8 67.2 430 10.1 2.7 46.5 109.1 YOLOv5x 640 50.7 68.9 766 12.1 4.8 86.7 205.7 YOLOv5n6 1280 34.0 50.7 153 8.1 2.1 3.2 4.6 YOLOv5s6 1280 44.5 63.0 385 8.2 3.6 16.8 12.6 YOLOv5m6 1280 51.0 69.0 887 11.1 6.8 35.7 50.0 YOLOv5l6 1280 53.6 71.6 1784 15.8 10.5 76.8 111.4 YOLOv5x6
+ TTA1280
153654.7
55.472.4
72.33136
-26.2
-19.4
-140.7
-209.8
-Table Notes (click to expand)
- All checkpoints are trained to 300 epochs with default settings. Nano models use hyp.scratch-low.yaml hyperparameters, all others use hyp.scratch-high.yaml.
- mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65- Speed averaged over COCO val images using a AWS p3.2xlarge instance. NMS times (~1 ms/img) not included.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45- TTA Test Time Augmentation includes reflection and scale augmentations.
Reproduce bypython val.py --data coco.yaml --img 1536 --iou 0.7 --augmentChangelog
Changes between previous release and this release: ultralytics/yolov5@v5.0...v6.0
Changes since this release: ultralytics/yolov5@v6.0...HEADNew Features and Bug Fixes (465)
- YOLOv5 v5.0 Release patch 1 by @glenn-jocher in ultralytics/yolov5#2764
- Flask REST API Example by @robmarkcole in ultralytics/yolov5#2732
- ONNX Simplifier by @glenn-jocher in ultralytics/yolov5#2815
- YouTube Bug Fix by @glenn-jocher in ultralytics/yolov5#2818
- PyTorch Hub cv2 .save() .show() bug fix by @glenn-jocher in ultralytics/yolov5#2831
- Create FUNDING.yml by @glenn-jocher in ultralytics/yolov5#2832
- Update FUNDING.yml by @glenn-jocher in ultralytics/yolov5#2833
- Fix ONNX dynamic axes export support with onnx simplifier, make onnx simplifier optional by @timstokman in ultralytics/yolov5#2856
- Update increment_path() to handle file paths by @glenn-jocher in ultralytics/yolov5#2867
- Detection cropping+saving feature addition for detect.py and PyTorch Hub by @Ab-Abdurrahman in ultralytics/yolov5#2827
- Implement yaml.safe_load() by @glenn-jocher in ultralytics/yolov5#2876
- Cleanup load_image() by @JoshSong in ultralytics/yolov5#2871
- bug fix: switched rows and cols for correct detections in confusion matrix by @MichHeilig in ultralytics/yolov5#2883
- VisDrone2019-DET Dataset Auto-Download by @glenn-jocher in ultralytics/yolov5#2882
- Uppercase model filenames enabled by @r-blmnr in ultralytics/yolov5#2890
- ACON activation function by @glenn-jocher in ultralytics/yolov5#2893
- Explicit opt function arguments by @fcakyon in ultralytics/yolov5#2817
- Update yolo.py by @glenn-jocher in ultralytics/yolov5#2899
- Update google_utils.py by @glenn-jocher in ultralytics/yolov5#2900
- Add detect.py --hide-conf --hide-labels --line-thickness options by @Ashafix in ultralytics/yolov5#2658
- Default optimize_for_mobile() on TorchScript models by @glenn-jocher in ultralytics/yolov5#290...
Contributors
Assets 6
v9.5.0 - YOLOv5 v5.0 release compatibility update for YOLOv3
This YOLOv3 release merges the most recent updates to YOLOv5 featured in the April 11th, 2021 YOLOv5 v5.0 release into this repository. This is part of routine Ultralytics maintenance and takes place on every major YOLOv5 release. Full details on the YOLOv5 v5.0 release is below.

https://github.com/ultralytics/yolov5/releases/tag/v5.0
This release implements YOLOv5-P6 models and retrained YOLOv5-P5 models:
- YOLOv5-P5 models (same architecture as v4.0 release): 3 output layers P3, P4, P5 at strides 8, 16, 32, trained at
--img 640- YOLOv5-P6 models: 4 output layers P3, P4, P5, P6 at strides 8, 16, 32, 64 trained at
--img 1280Example usage:
# Command Line python detect.py --weights yolov5m.pt --img 640 # P5 model at 640 python detect.py --weights yolov5m6.pt --img 640 # P6 model at 640 python detect.py --weights yolov5m6.pt --img 1280 # P6 model at 1280# PyTorch Hub model = torch.hub.load('ultralytics/yolov5', 'yolov5m6') # P6 model results = model(imgs, size=1280) # inference at 1280All model sizes YOLOv5s/m/l/x are now available in P5 and P6 architectures:
python detect.py --weights yolov5s.pt # P5 models yolov5m.pt yolov5l.pt yolov5x.pt yolov5s6.pt # P6 models yolov5m6.pt yolov5l6.pt yolov5x6.ptNotable Updates
- YouTube Inference: Direct inference from YouTube videos, i.e.
python detect.py --source 'https://youtu.be/NUsoVlDFqZg'. Live streaming videos and normal videos supported. (ultralytics/yolov5#2752)- AWS Integration: Amazon AWS integration and new AWS Quickstart Guide for simple EC2 instance YOLOv5 training and resuming of interrupted Spot instances. (ultralytics/yolov5#2185)
- Supervise.ly Integration: New integration with the Supervisely Ecosystem for training and deploying YOLOv5 models with Supervise.ly (ultralytics/yolov5#2518)
- Improved W&B Integration: Allows saving datasets and models directly to Weights & Biases. This allows for --resume directly from W&B (useful for temporary environments like Colab), as well as enhanced visualization tools. See this blog by @AyushExel for details. (ultralytics/yolov5#2125)
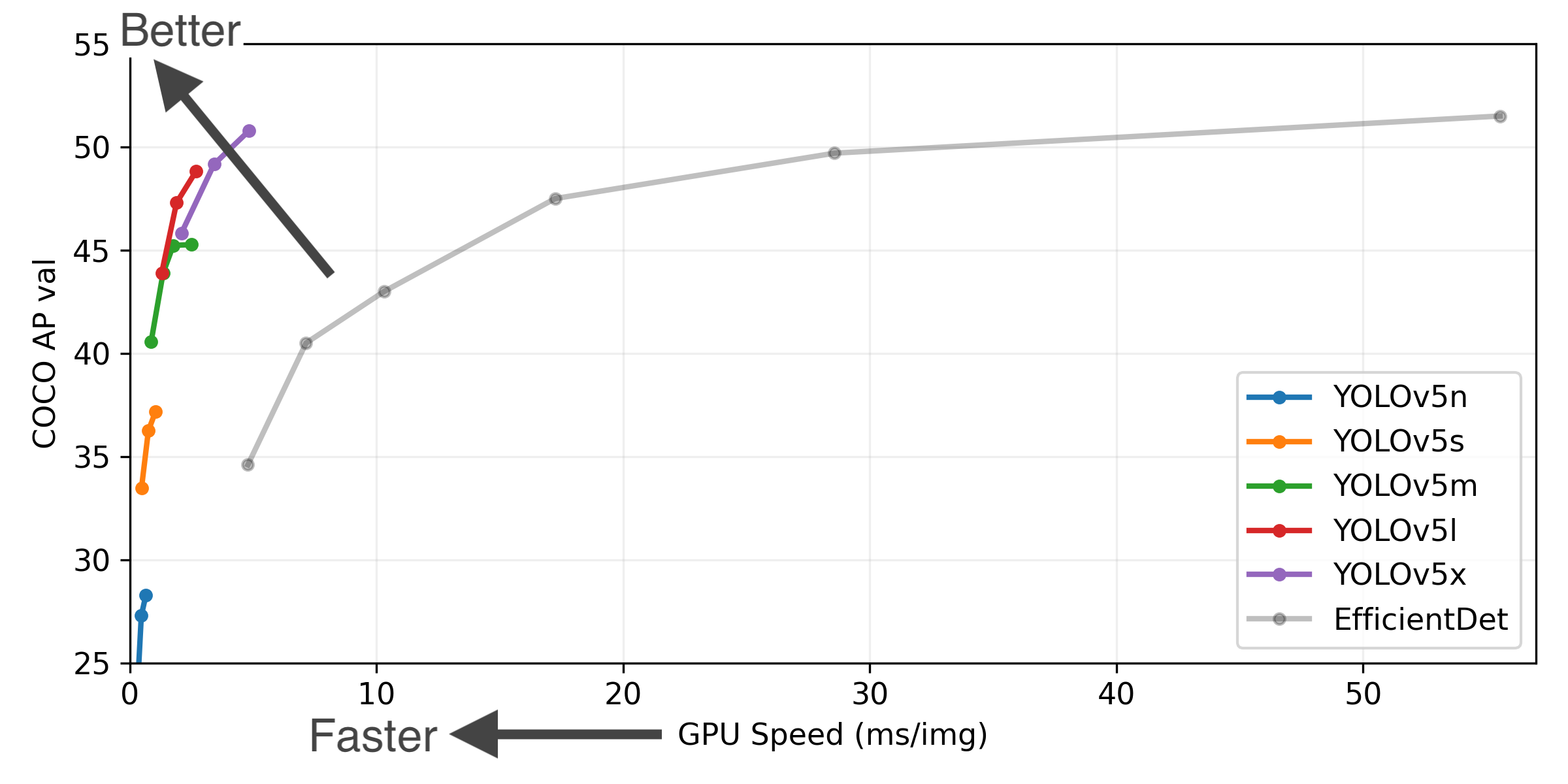
Updated Results
P6 models include an extra P6/64 output layer for detection of larger objects, and benefit the most from training at higher resolution. For this reason we trained all P5 models at 640, and all P6 models at 1280.
YOLOv5-P5 640 Figure (click to expand)
Figure Notes (click to expand)
- GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS.
- EfficientDet data from google/automl at batch size 8.
- April 11, 2021: v5.0 release: YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube integrations.
- January 5, 2021: v4.0 release: nn.SiLU() activations, Weights & Biases logging, PyTorch Hub integration.
- August 13, 2020: v3.0 release: nn.Hardswish() activations, data autodownload, native AMP.
- July 23, 2020: v2.0 release: improved model definition, training and mAP.
Pretrained Checkpoints
Model size
(pixels)mAPval
0.5:0.95mAPtest
0.5:0.95mAPval
0.5Speed
V100 (ms)params
(M)FLOPS
640 (B)YOLOv5s 640 36.7 36.7 55.4 2.0 7.3 17.0 YOLOv5m 640 44.5 44.5 63.3 2.7 21.4 51.3 YOLOv5l 640 48.2 48.2 66.9 3.8 47.0 115.4 YOLOv5x 640 50.4 50.4 68.8 6.1 87.7 218.8 YOLOv5s6 1280 43.3 43.3 61.9 4.3 12.7 17.4 YOLOv5m6 1280 50.5 50.5 68.7 8.4 35.9 52.4 YOLOv5l6 1280 53.4 53.4 71.1 12.3 77.2 117.7 YOLOv5x6 1280 54.4 54.4 72.0 22.4 141.8 222.9 YOLOv5x6 TTA 1280 55.0 55.0 72.0 70.8 - - Table Notes (click to expand)
- APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
- AP values are for single-model single-scale unless otherwise noted. Reproduce mAP by
python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65- SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes FP16 inference, postprocessing and NMS. Reproduce speed by
python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45- All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
- Test Time Augmentation (TTA) includes reflection and scale augmentation. Reproduce TTA by
python test.py --data coco.yaml --img 1536 --iou 0.7 --augmentChangelog
Changes between previous release and this release: ultralytics/yolov5@v4.0...v5.0
Changes since this release: ultralytics/yolov5@v5.0...HEADClick a section below to expand details:
Implemented Enhancements (26)
- Return predictions as json #2703
- Single channel image training? #2609
- Images in MPO Format are considered corrupted #2446
- Improve Validation Visualization #2384
- Add ASFF (three fuse feature layers) int the Head for V5(s,m,l,x) #2348
- Dear author, can you provide a visualization scheme for YOLOV5 feature graphs during detect.py? Thank you! #2259
- Dataloader #2201
- Update Train Custom Data wiki page #2187
- Multi-class NMS #2162
- 💡Idea: Mosaic cropping using segmentation labels #2151
- Improving Confusion Matrix Interpretability: FP and FN vectors should be switched to align with Predicted and True axis #2071
- Interpreting model YoloV5 by Grad-cam #2065
- Output optimal confidence threshold based on PR curve #2048
- is it valuable that add --cache-images option to detect.py? #2004
- I want to change the anchor box to anchor circles, where do you think the change to be made ? #1987
- Support for imgaug #1954
- Any plan for Knowledge Distillation? #1762
- Is there a wasy to run detections on a video/webcam/rtrsp, etc EVERY x SECONDS? #1742
- Can yolov5 support rotated target detection? #1728
- Deploying yolov5 to TorchServe (GPU compatible) #1681
- Why diffrent colors of bboxs? #1638
- Yet ano...

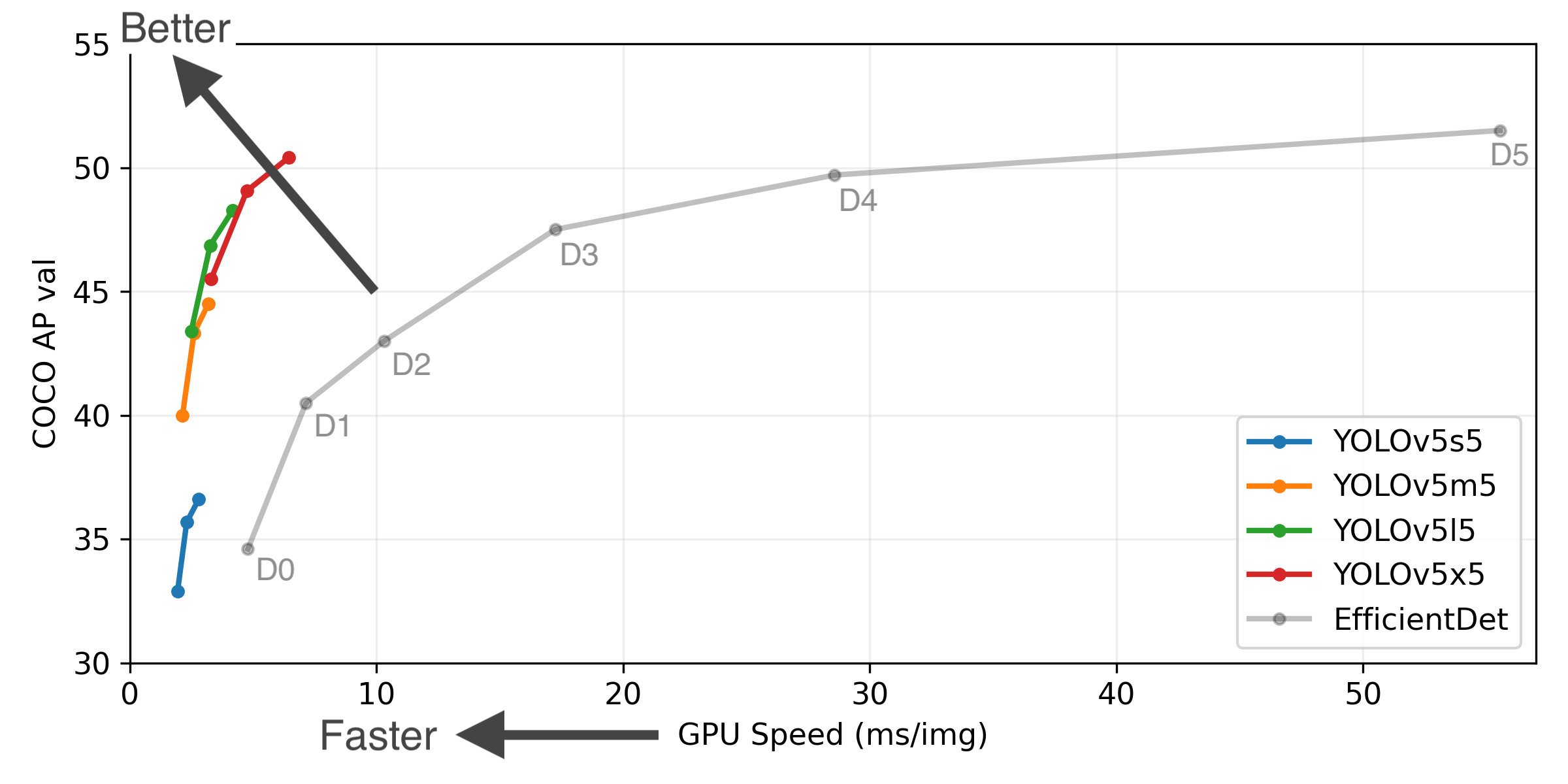
v9.1 - YOLOv5 Forward Compatibility Updates
This release is a minor update implementing numerous bug fixes, feature additions and performance improvements from https://github.com/ultralytics/yolov5 to this repo. Models remain unchanged from v9.0 release.
Branch Notice
The ultralytics/yolov3 repository is now divided into two branches:
- Master branch: Forward-compatible with all YOLOv5 models and methods (recommended).
$ git clone https://github.com/ultralytics/yolov3 # master branch (default)- Archive branch: Backwards-compatible with original darknet *.cfg models (
⚠️ no longer maintained).
$ git clone -b archive https://github.com/ultralytics/yolov3 # archive branch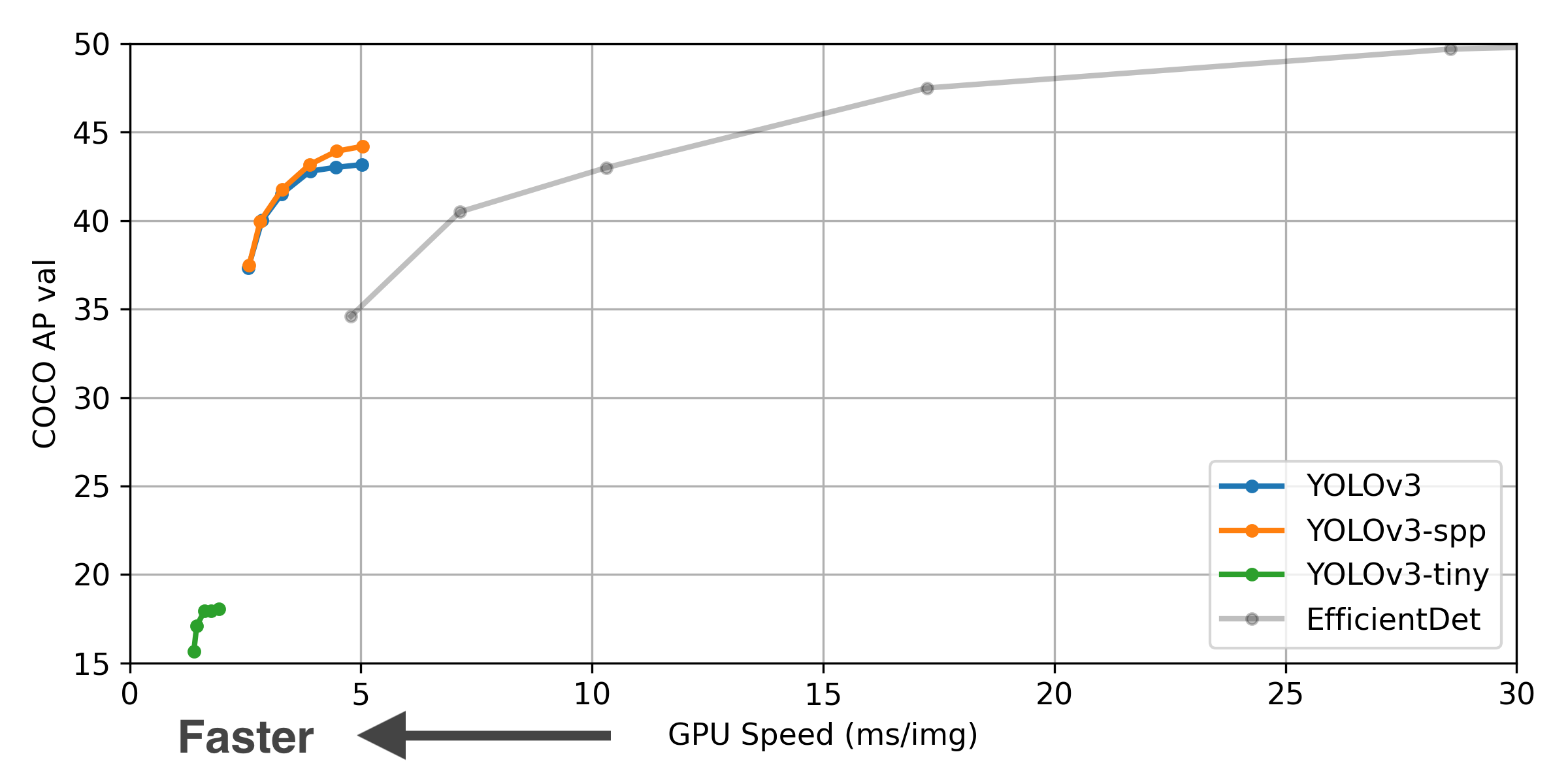
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
Pretrained Checkpoints
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 43.3 | 43.3 | 63.0 | 4.8ms | 208 | 61.9M | 156.4B | |
| YOLOv3-SPP | 44.3 | 44.3 | 64.6 | 4.9ms | 204 | 63.0M | 157.0B | |
| YOLOv3-tiny | 17.6 | 34.9 | 34.9 | 1.7ms | 588 | 8.9M | 13.3B |
** APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or TTA. Reproduce mAP by python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65
** SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes image preprocessing, FP16 inference, postprocessing and NMS. NMS is 1-2ms/img. Reproduce speed by python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
** Test Time Augmentation (TTA) runs at 3 image sizes. Reproduce TTA by python test.py --data coco.yaml --img 832 --iou 0.65 --augment
Requirements
Python 3.8 or later with all requirements.txt dependencies installed, including torch>=1.7. To install run:
$ pip install -r requirements.txtv9.0 - YOLOv5 Forward Compatibility Release
This release is a major update to the https://github.com/ultralytics/yolov3 repository that brings forward-compatibility with YOLOv5, and incorporates numerous bug fixes, feature additions and performance improvements from https://github.com/ultralytics/yolov5 to this repo.
Branch Notice
The ultralytics/yolov3 repository is now divided into two branches:
- Master branch: Forward-compatible with all YOLOv5 models and methods (recommended).
$ git clone https://github.com/ultralytics/yolov3 # master branch (default)- Archive branch: Backwards-compatible with original darknet *.cfg models (
⚠️ no longer maintained).
$ git clone -b archive https://github.com/ultralytics/yolov3 # archive branch
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
Pretrained Checkpoints
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 43.3 | 43.3 | 63.0 | 4.8ms | 208 | 61.9M | 156.4B | |
| YOLOv3-SPP | 44.3 | 44.3 | 64.6 | 4.9ms | 204 | 63.0M | 157.0B | |
| YOLOv3-tiny | 17.6 | 34.9 | 34.9 | 1.7ms | 588 | 8.9M | 13.3B |
** APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or TTA. Reproduce mAP by python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65
** SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes image preprocessing, FP16 inference, postprocessing and NMS. NMS is 1-2ms/img. Reproduce speed by python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
** Test Time Augmentation (TTA) runs at 3 image sizes. Reproduce TTA by python test.py --data coco.yaml --img 832 --iou 0.65 --augment
Requirements
Python 3.8 or later with all requirements.txt dependencies installed, including torch>=1.7. To install run:
$ pip install -r requirements.txtv8 - Final Darknet Compatible Release
This is the final release of the darknet-compatible version of the https://github.com/ultralytics/yolov3 repository. This release is backwards-compatible with darknet *.cfg files for model configuration.
All pytorch (*.pt) and darknet (*.weights) models/backbones available are attached to this release in the Assets section below.
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- Various
Added Functionality
- Various
Speed
https://cloud.google.com/deep-learning-vm/
Machine type: preemptible n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.14/hr), T4 ($0.11/hr), V100 ($0.74/hr) CUDA with Nvidia Apex FP16/32
HDD: 300 GB SSD
Dataset: COCO train 2014 (117,263 images)
Model: yolov3-spp.cfg
Command: python3 train.py --data coco2017.data --img 416 --batch 32
| GPU | n | --batch-size |
img/s | epoch time |
epoch cost |
|---|---|---|---|---|---|
| K80 | 1 | 32 x 2 | 11 | 175 min | $0.41 |
| T4 | 1 2 |
32 x 2 64 x 1 |
41 61 |
48 min 32 min |
$0.09 $0.11 |
| V100 | 1 2 |
32 x 2 64 x 1 |
122 178 |
16 min 11 min |
$0.21 $0.28 |
| 2080Ti | 1 2 |
32 x 2 64 x 1 |
81 140 |
24 min 14 min |
- - |
mAP
| Size | COCO mAP @0.5...0.95 |
COCO mAP @0.5 |
|
|---|---|---|---|
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
320 | 14.0 28.7 30.5 37.7 |
29.1 51.8 52.3 56.8 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
416 | 16.0 31.2 33.9 41.2 |
33.0 55.4 56.9 60.6 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
512 | 16.6 32.7 35.6 42.6 |
34.9 57.7 59.5 62.4 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
608 | 16.6 33.1 37.0 43.1 |
35.4 58.2 60.7 62.8 |
TODO
- NA
[email protected]:0.95 on COCO2014
This release requires PyTorch >= v1.4 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- Various
Added Functionality
- Improved training and test ground truth and prediction plotting. #1114
- Increased augmentation speed. #1110
- Improved Tensorboard integration.
- Auto class hyperparameter update based on dataset class count.
- Inference time augmentation option added now with
--augmentargument in test.py and detect.py. - Rectangular training with
--rectargument in train.py
Speed
https://cloud.google.com/deep-learning-vm/
Machine type: preemptible n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.14/hr), T4 ($0.11/hr), V100 ($0.74/hr) CUDA with Nvidia Apex FP16/32
HDD: 300 GB SSD
Dataset: COCO train 2014 (117,263 images)
Model: yolov3-spp.cfg
Command: python3 train.py --data coco2017.data --img 416 --batch 32
| GPU | n | --batch-size |
img/s | epoch time |
epoch cost |
|---|---|---|---|---|---|
| K80 | 1 | 32 x 2 | 11 | 175 min | $0.41 |
| T4 | 1 2 |
32 x 2 64 x 1 |
41 61 |
48 min 32 min |
$0.09 $0.11 |
| V100 | 1 2 |
32 x 2 64 x 1 |
122 178 |
16 min 11 min |
$0.21 $0.28 |
| 2080Ti | 1 2 |
32 x 2 64 x 1 |
81 140 |
24 min 14 min |
- - |
mAP
| Size | COCO mAP @0.5...0.95 |
COCO mAP @0.5 |
|
|---|---|---|---|
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
320 | 14.0 28.7 30.5 37.7 |
29.1 51.8 52.3 56.8 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
416 | 16.0 31.2 33.9 41.2 |
33.0 55.4 56.9 60.6 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
512 | 16.6 32.7 35.6 42.6 |
34.9 57.7 59.5 62.4 |
| YOLOv3-tiny YOLOv3 YOLOv3-SPP YOLOv3-SPP-ultralytics |
608 | 16.6 33.1 37.0 43.1 |
35.4 58.2 60.7 62.8 |
TODO (help and PR's welcome!)
- Add iOS App inference to photos and videos in Camera Roll, as well as 'Flexible', or at least rectangular inference. #224
Rectangular Inference, Conv2d + Batchnorm2d Layer Fusion
This release requires PyTorch >= v1.0.0 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- NMS now screens out nan and inf values which caused it to hang during some edge cases.
Added Functionality
- Rectangular Inference. detect.py now automatically processes images, videos and webcam feeds using rectangular inference, letterboxing to the minimum viable 32-multiple. This speeds up inference by up to 40% on HD video: #232
- Conv2d + Batchnorm2d Layer Fusion: detect.py now automatically fuses the Conv2d and Batchnorm2d layers in the model before running inference. This speeds up inference by about 5-10%. #224
- Hyperparameters all parameterized and grouped togethor in train.py now. Genetic Hyperparameter Evolution code added to train.py.
Performance
https://cloud.google.com/deep-learning-vm/
Machine type: n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.198/hr), P4 ($0.279/hr), T4 ($0.353/hr), P100 ($0.493/hr), V100 ($0.803/hr)
HDD: 100 GB SSD
Dataset: COCO train 2014
| GPUs | batch_size |
batch time | epoch time | epoch cost |
|---|---|---|---|---|
| (images) | (s/batch) | |||
| 1 K80 | 16 | 1.43s | 175min | $0.58 |
| 1 P4 | 8 | 0.51s | 125min | $0.58 |
| 1 T4 | 16 | 0.78s | 94min | $0.55 |
| 1 P100 | 16 | 0.39s | 48min | $0.39 |
| 2 P100 | 32 | 0.48s | 29min | $0.47 |
| 4 P100 | 64 | 0.65s | 20min | $0.65 |
| 1 V100 | 16 | 0.25s | 31min | $0.41 |
| 2 V100 | 32 | 0.29s | 18min | $0.48 |
| 4 V100 | 64 | 0.41s | 13min | $0.70 |
| 8 V100 | 128 | 0.49s | 7min | $0.80 |
TODO (help and PR's welcome!)
- Add iOS App inference to photos and videos in Camera Roll, as well as 'Flexible', or at least rectangular inference. #224
- Add parameter to switch between 'darknet' and 'power' wh methods. #168
- YAPF linting (including possible wrap to PEP8 79 character-line standard) #88.
- Resolve mAP bug: #222
- Rectangular training. #232
- Genetic Hyperparameter Evolution. HELP NEEDED HERE. If you have available hardware please contact us, as we need help expanding our hyperparameter search, for the benefit of everyone!
Video Inference, Transfer Learning Improvements
This release requires PyTorch >= v1.0.0 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- None
Added Functionality
- Video Inference. detect.py now automatically processes both images and videos. Image and video results are saved in their respective formats now (video inference saves new videos).
- Transfer learning now operates automatically regardless of yolo layer size #152.
Performance
https://cloud.google.com/deep-learning-vm/
Machine type: n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.198/hr), P4 ($0.279/hr), T4 ($0.353/hr), P100 ($0.493/hr), V100 ($0.803/hr)
HDD: 100 GB SSD
Dataset: COCO train 2014
| GPUs | batch_size |
batch time | epoch time | epoch cost |
|---|---|---|---|---|
| (images) | (s/batch) | |||
| 1 K80 | 16 | 1.43s | 175min | $0.58 |
| 1 P4 | 8 | 0.51s | 125min | $0.58 |
| 1 T4 | 16 | 0.78s | 94min | $0.55 |
| 1 P100 | 16 | 0.39s | 48min | $0.39 |
| 2 P100 | 32 | 0.48s | 29min | $0.47 |
| 4 P100 | 64 | 0.65s | 20min | $0.65 |
| 1 V100 | 16 | 0.25s | 31min | $0.41 |
| 2 V100 | 32 | 0.29s | 18min | $0.48 |
| 4 V100 | 64 | 0.41s | 13min | $0.70 |
| 8 V100 | 128 | 0.49s | 7min | $0.80 |
TODO (help and PR's welcome!)
mAP Improvements Past Darknet, Multithreaded DataLoader
This release requires PyTorch >= v1.0.0 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- Multi GPU support is now working correctly #21.
test.pynow natively outputs the same results as pycocotools to within 1% under most circumstances #2
Added Functionality
- Dataloader is now multithread. #141
- mAP improved by smarter NMS. mAP now exceeds darknet mAP by a small amount in all image sizes 320-608.
ultralytics/yolov3 with pycocotools |
darknet/yolov3 | |
|---|---|---|
| YOLOv3-320 | 51.8 | 51.5 |
| YOLOv3-416 | 55.4 | 55.3 |
| YOLOv3-608 | 58.2 | 57.9 |
sudo rm -rf yolov3 && git clone https://github.com/ultralytics/yolov3
# bash yolov3/data/get_coco_dataset.sh
sudo rm -rf cocoapi && git clone https://github.com/cocodataset/cocoapi && cd cocoapi/PythonAPI && make && cd ../.. && cp -r cocoapi/PythonAPI/pycocotools yolov3
cd yolov3
python3 test.py --save-json --conf-thres 0.001 --img-size 416
Namespace(batch_size=32, cfg='cfg/yolov3.cfg', conf_thres=0.001, data_cfg='cfg/coco.data', img_size=416, iou_thres=0.5, nms_thres=0.5, save_json=True, weights='weights/yolov3.weights')
Using cuda _CudaDeviceProperties(name='Tesla V100-SXM2-16GB', major=7, minor=0, total_memory=16130MB, multi_processor_count=80)
Image Total P R mAP
Calculating mAP: 100%|█████████████████████████████████| 157/157 [08:34<00:00, 2.53s/it]
5000 5000 0.0896 0.756 0.555
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.312
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.554
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.317
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.145
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.343
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.452
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.268
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.411
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.435
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.244
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.477
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.587
python3 test.py --save-json --conf-thres 0.001 --img-size 608 --batch-size 16
Namespace(batch_size=16, cfg='cfg/yolov3.cfg', conf_thres=0.001, data_cfg='cfg/coco.data', img_size=608, iou_thres=0.5, nms_thres=0.5, save_json=True, weights='weights/yolov3.weights')
Using cuda _CudaDeviceProperties(name='Tesla V100-SXM2-16GB', major=7, minor=0, total_memory=16130MB, multi_processor_count=80)
Image Total P R mAP
Calculating mAP: 100%|█████████████████████████████████| 313/313 [08:54<00:00, 1.55s/it]
5000 5000 0.0966 0.786 0.579
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.331
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.582
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.344
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.198
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.362
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.427
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.281
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.437
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.463
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.309
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.494
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.577Performance
- mAP computation is much slower now than before using default settings, as
--conf-thres 0.001captures many boxes that all must be passed through NMS. On a V100 test.py runs in about 8 minutes - Training speed is improved substantially compared to v3.0 due to the addition of the multithreaded PyTorch dataloader.
https://cloud.google.com/deep-learning-vm/
Machine type: n1-standard-8 (8 vCPUs, 30 GB memory)
CPU platform: Intel Skylake
GPUs: K80 ($0.198/hr), P4 ($0.279/hr), T4 ($0.353/hr), P100 ($0.493/hr), V100 ($0.803/hr)
HDD: 100 GB SSD
Dataset: COCO train 2014
| GPUs | batch_size |
batch time | epoch time | epoch cost |
|---|---|---|---|---|
| (images) | (s/batch) | |||
| 1 K80 | 16 | 1.43s | 175min | $0.58 |
| 1 P4 | 8 | 0.51s | 125min | $0.58 |
| 1 T4 | 16 | 0.78s | 94min | $0.55 |
| 1 P100 | 16 | 0.39s | 48min | $0.39 |
| 2 P100 | 32 | 0.48s | 29min | $0.47 |
| 4 P100 | 64 | 0.65s | 20min | $0.65 |
| 1 V100 | 16 | 0.25s | 31min | $0.41 |
| 2 V100 | 32 | 0.29s | 18min | $0.48 |
| 4 V100 | 64 | 0.41s | 13min | $0.70 |
| 8 V100 | 128 | 0.49s | 7min | $0.80 |
TODO (help and PR's welcome!)
- Video Inference. Pass a video file to detect.py.
- YAPF linting (including possible wrap to PEP8 79 character-line standard) #88.
- Add iOS App inference to photos and videos in Camera Roll.
- Add parameter to switch between 'darknet' and 'power' wh methods. #168
- Hyperparameter search for loss function constants.
Multi-GPU, Tutorials, Official COCO mAP Support
This release requires PyTorch >= v1.0.0 to function properly. Please install the latest version from https://github.com/pytorch/pytorch/releases
Breaking Changes
There are no breaking changes in this release.
Bug Fixes
- Multi GPU support #21.
Added Functionality
- Tutorial created: https://github.com/ultralytics/yolov3/wiki/Example:-Transfer-Learning
- Tutorial created: https://github.com/ultralytics/yolov3/wiki/Example:-Train-Single-Image
- Tutorial created: https://github.com/ultralytics/yolov3/wiki/Example:-Train-Single-Class
- Tutorial created: https://github.com/ultralytics/yolov3/wiki/Train-Custom-Data
test.pyoptionally outputs pycocotools compatible json files now with the--save-jsonflag, and computes official COCO mAP using pycocotools. Output is verified against official darknet results from https://arxiv.org/abs/1804.02767. #2 (comment).
| ultralytics/yolov3 mAP | darknet mAP | |
|---|---|---|
| YOLOv3-320 | 51.3 | 51.5 |
| YOLOv3-416 | 54.9 | 55.3 |
| YOLOv3-608 | 57.9 | 57.9 |
Performance
- 10% improvement in training speed via code optimization. Performance should be further improved by multithreading the dataloader (on the TODO list).
https://cloud.google.com/deep-learning-vm/
Machine type: n1-highmem-4 (4 vCPUs, 26 GB memory)
CPU platform: Intel Skylake
GPUs: 1-4 x NVIDIA Tesla P100
HDD: 100 GB SSD
| GPUs | batch_size |
speed | COCO epoch |
|---|---|---|---|
| (P100) | (images) | (s/batch) | (min/epoch) |
| 1 | 16 | 0.54s | 66min |
| 2 | 32 | 0.99s | 61min |
| 4 | 64 | 1.61s | 49min |
TODO (help and PR's welcome!)
- Dataloader should enable multithread. Single thread loading takes about 230 ms per batch currently, out of total batch time of 550 ms (40%). Low GPU utilization reported. #141
- test.py should natively output the same results as pycocotools #2
- Video Inference. Pass a video file to detect.py.
- YAPF linting (including possible wrap to PEP8 79 character-line standard) #88.
- Add iOS App inference to photos and videos in Camera Roll.
- Add parameter to switch between 'darknet' and 'power' wh methods.