 We train embedding tables with fewer parameters by combining multiple sketches of the same data, iteratively.
We train embedding tables with fewer parameters by combining multiple sketches of the same data, iteratively.
This repository contains the code for the paper "Clustering the Sketch: Dynamic Compression for Embedding Tables".
Embedding tables are used by machine learning systems to work with categorical features. In modern Recommendation Systems, these tables can be very large, necessitating the development of new methods for fitting them in memory, even during training. We suggest Clustered Compositional Embeddings (CCE) which combines clustering-based compression like quantization to codebooks with dynamic methods like Hashing Trick [ICML '09] and Compositional Embeddings (QR) [KDD '20]. Experimentally CCE achieves the best of both worlds: The high compression rate of codebook-based quantization, but dynamically like hashing-based methods, so it can be used during training. Theoretically, we prove that CCE is guaranteed to converge to the optimal codebook and give a tight bound for the number of iterations required.
import torch, cce
class GMF(torch.nn.Module):
""" A simple Generalized Matrix Factorization model """
def __init__(self, n_users, n_items, dim, num_params):
super().__init__()
self.user_embedding = cce.make_embedding(n_users, num_params, dim, 'cce', n_chunks=4)
self.item_embedding = cce.make_embedding(n_items, num_params, dim, 'cce', n_chunks=4)
def forward(self, user, item):
user_emb = self.user_embedding(user)
item_emb = self.item_embedding(item)
return torch.sigmoid((user_emb * item_emb).sum(-1))
def epoch_end(self):
self.user_embedding.cluster()
self.item_embedding.cluster()Instead of the Clustered Compositional Embedding, the library also contain many other compressed embedding methods, such as cce.RobeEmbedding, cce.CompositionalEmbedding, cce.TensorTrainEmbedding and cce.DeepHashEmbedding.
See cce/__init__.py for examples on how to initialize them.
-
Context: Modern Recommendation Systems require large embedding tables, challenging to fit in memory during training.
-
Solution: CCE combines hashing/sketching methods with clustering during training, to learn an efficent sparse, data dependent hash function.
-
Contributions:
- CCE fills the gap between post-training compression (like Product Quantization) and during-training random mixing techniques (like Compositional Embeddings).
- CCE provably finds the optimal codebook with bounded iterations, at least for linear models.
- CCE experimentally outperforms all other methods for training large recommendation systems.
- We provide a large, standardized library of related methods available on GitHub.
Install with
pip install -e .Then run
python examples/movielens.py --method cceTo test run CCE on a simple movielens 100K dataset.
You can also use --method robe to use the Robe method, or ce for compositional embeddings.
@inproceedings{tsang2023clustering,
title={Clustering Embedding Tables, Without First Learning Them},
author={Tsang, Henry Ling-Hei and Ahle, Thomas Dybdahl},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2023}
}
- Hashing Trick [ICML '09]
- HashedNets [ICML '15]
- Hash Embeddings [NeurIPS '17]
- Compositional Embeddings (QR) [KDD '20]
- Deep Hash Embedding (DHE) [KDD '21]
- Tensor Train (TT-Rec) [MLSys '21]
- Random Offset Block Embedding (ROBE) [MLSys '22]
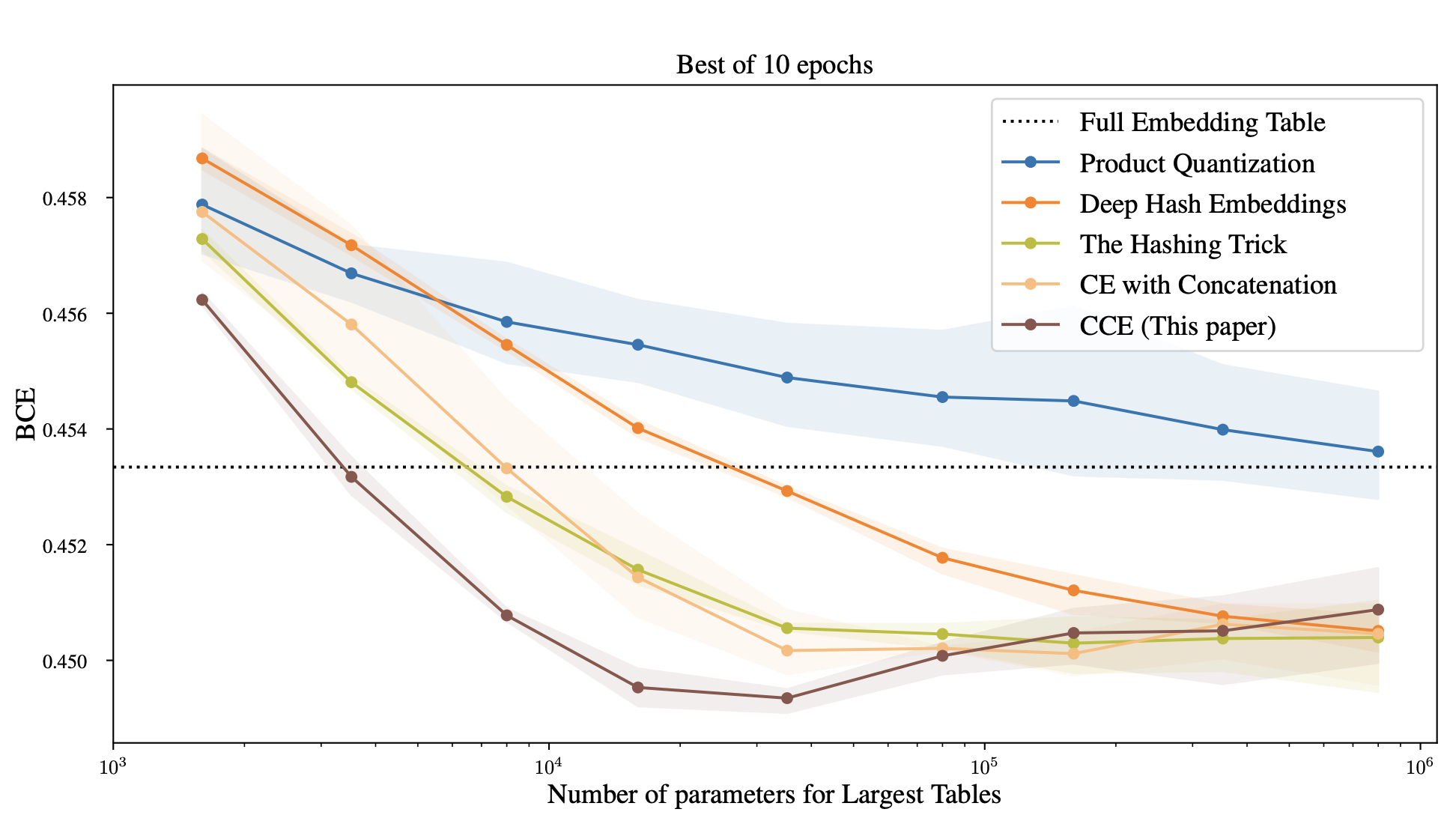
We adapted the Deep Learning Recommendation Model (DLRM) model to use CCE. Even reducing the number of parameters by a factor 8,500, we were able to get the same test loss (Binary cross entropy) as the full DLRM model.
| Criteo Kaggle | Criteo Terabyte |
|---|---|
|
|
|
We trained DLRM on the Criteo Kaggle dataset with different compression algorithms. Each of 27 categorical features was given its own embedding table, where we limited the number of parameters in the largest table as shown in the x-axis. See more details in the paper. |
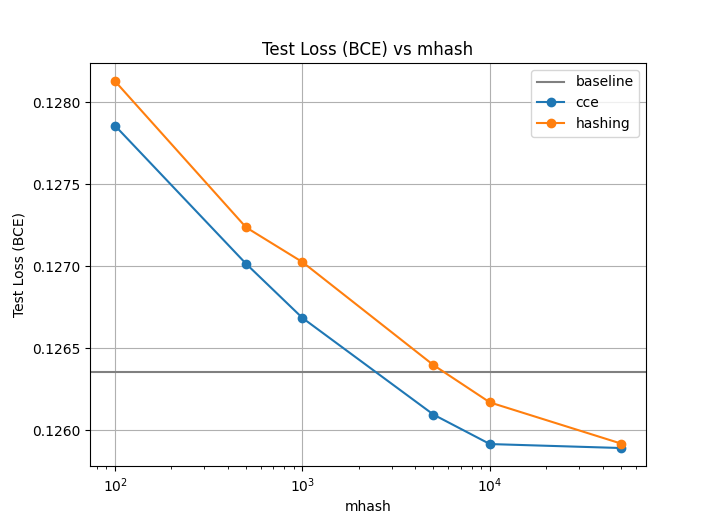
The Download Criteo 1TB Click Logs dataset is the largest publicly available recommendation dataset. We trained for 10 epochs using the CCE method, as well as hashing, but only one repetition as the dataset is massive. |
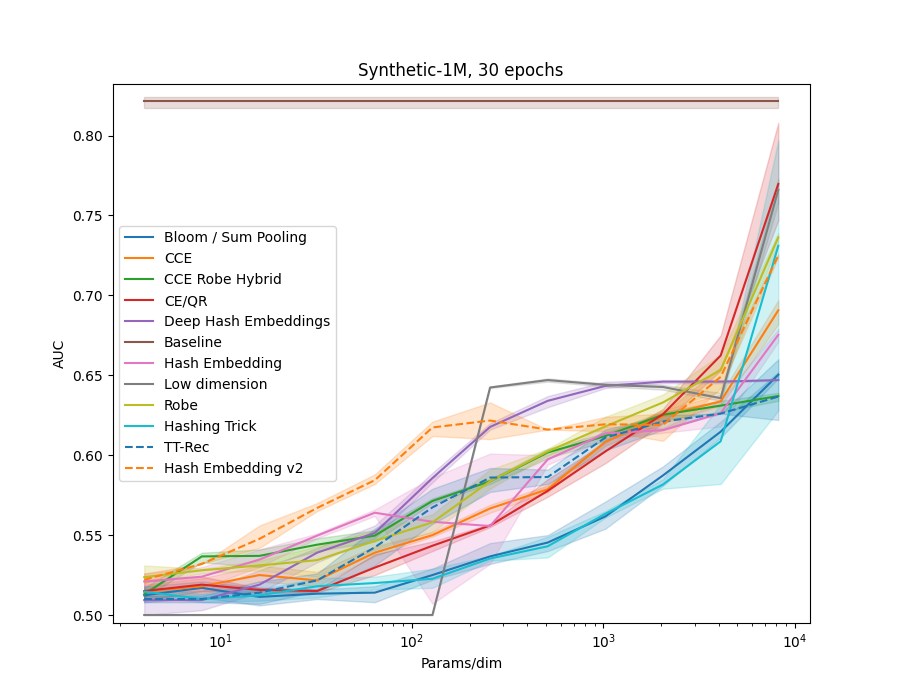
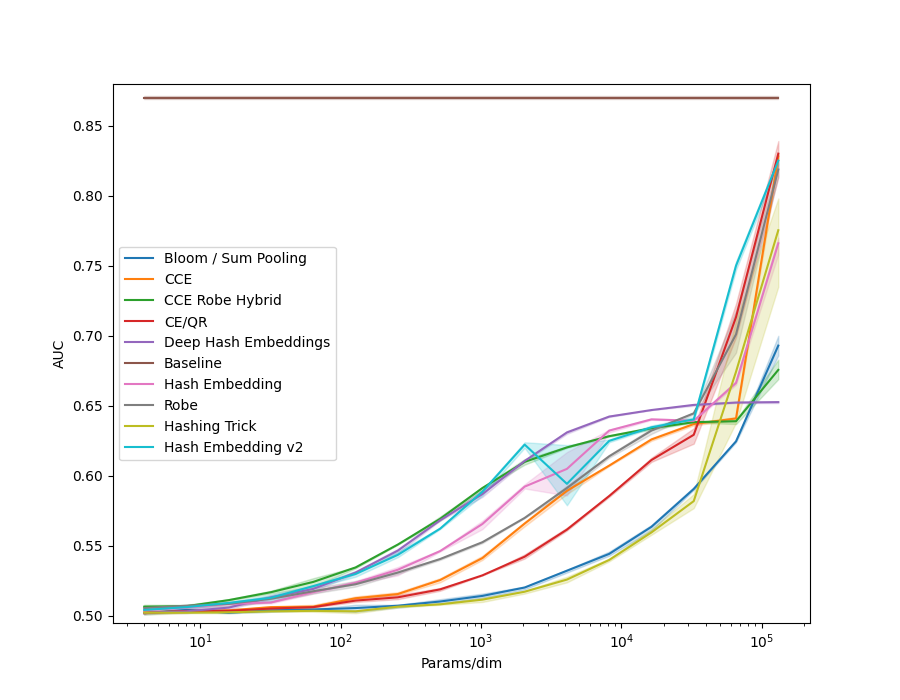
In examples/movielens.py we implemented a Generalized Matrix Factorization model, as in the example code above. We then ran each method in the library on the different MovieLens datasets, ML-1m, ML-20m and ML-25m. We also created a synthetic dataset, using random embeddings and the GMF model to generate interaction data.
| Size | MovieLens | Synthetic |
|---|---|---|
| 1M | 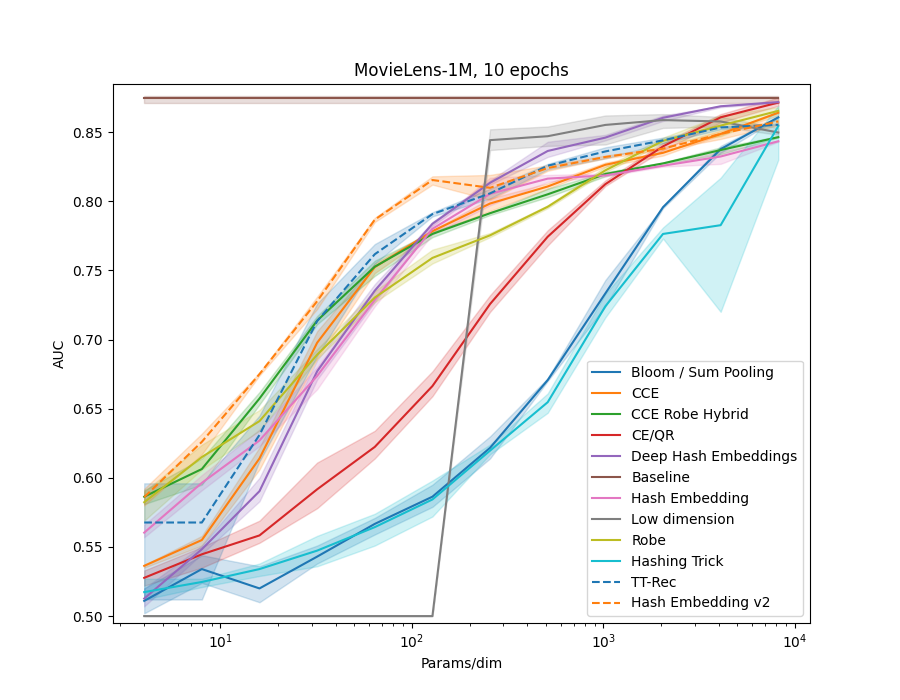 |
 |
| 10M | . | 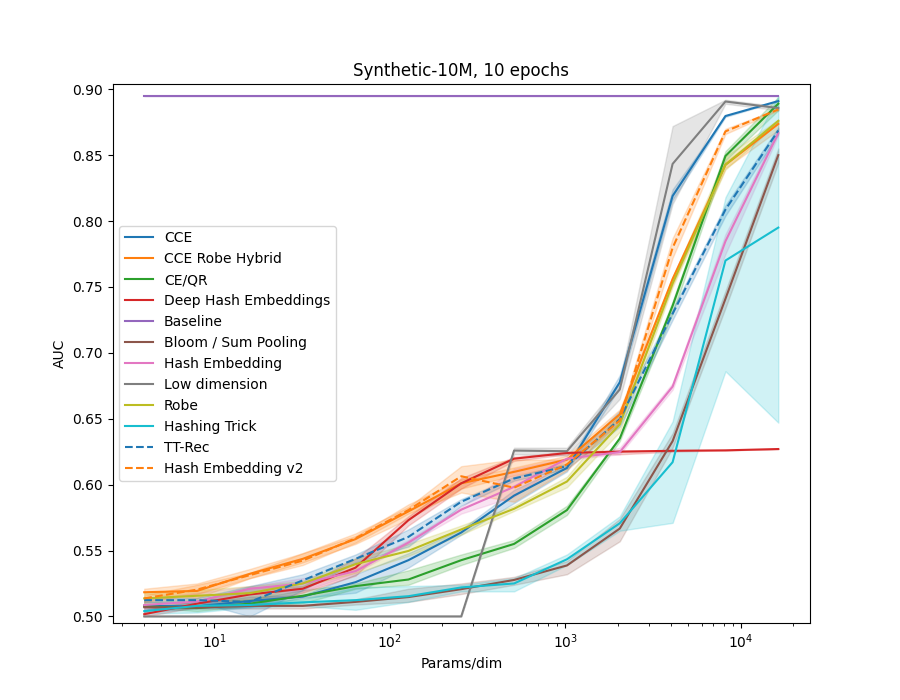 |
| 20M | 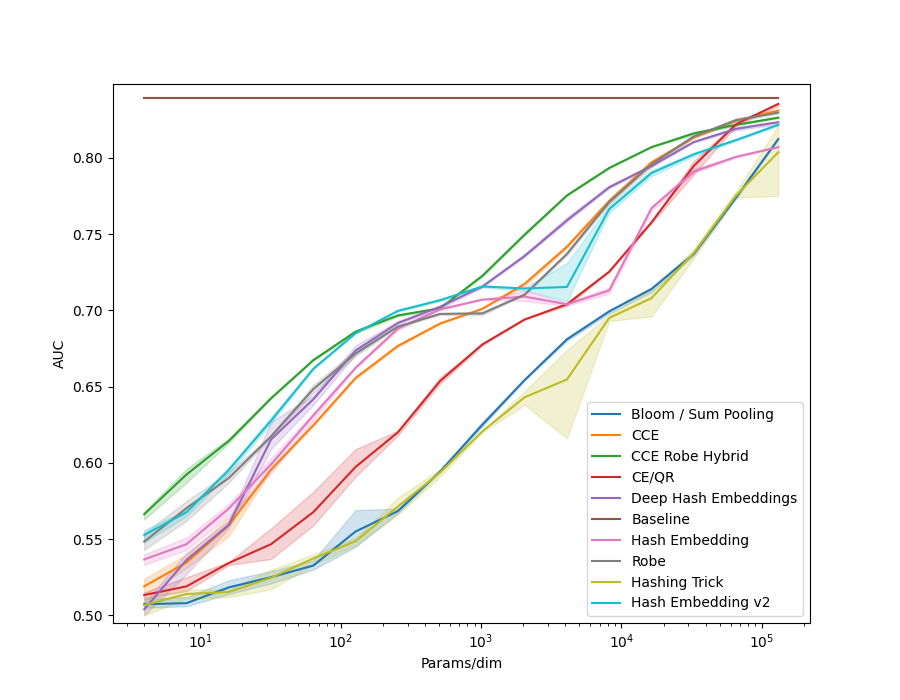 |
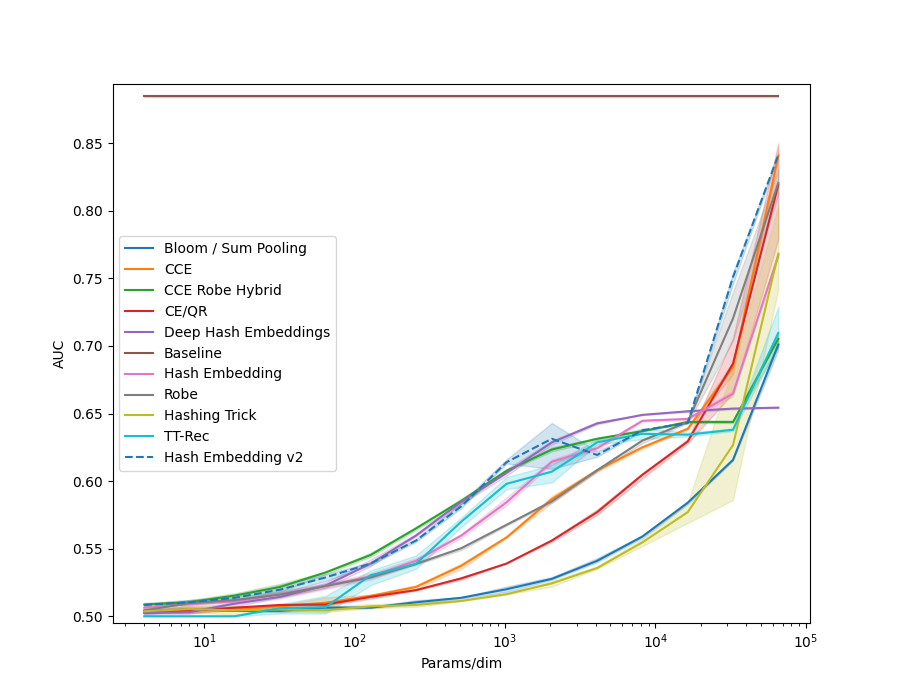 |
| 25M | 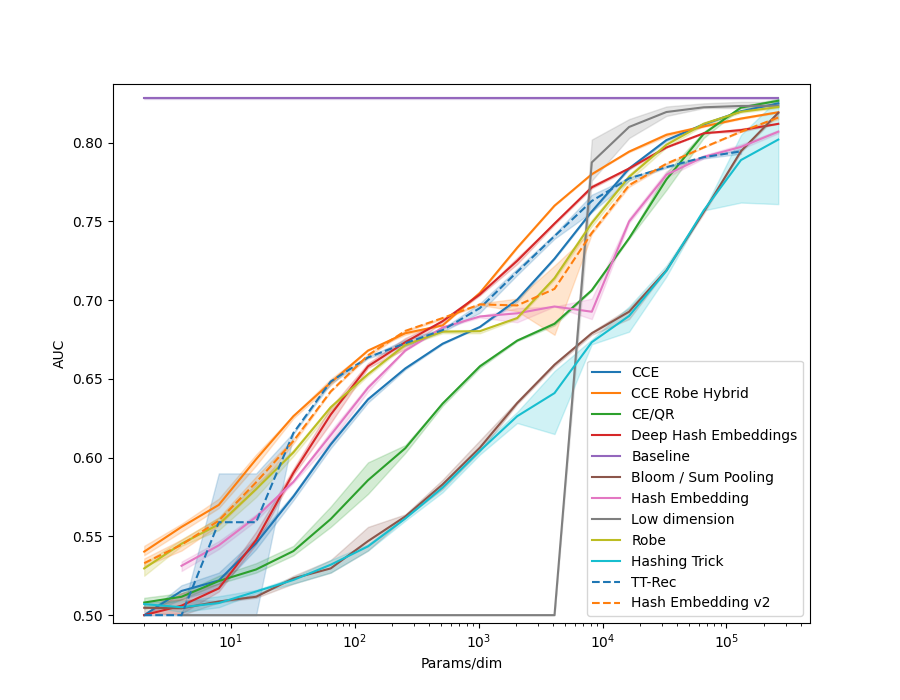 |
 |
| 100M | 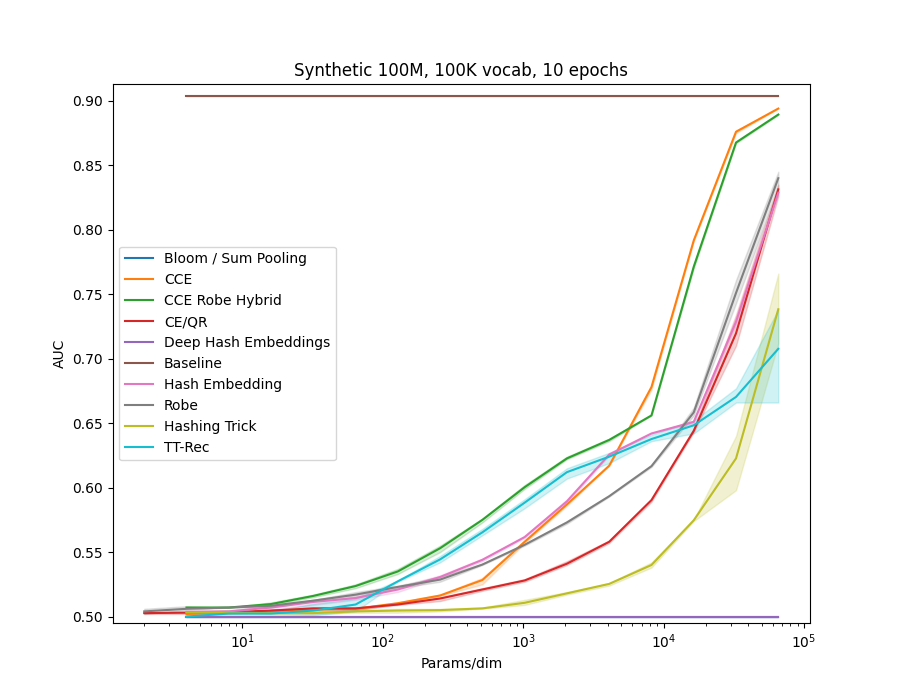 |
All models use 32 dimensional embedidng tables of the given method.
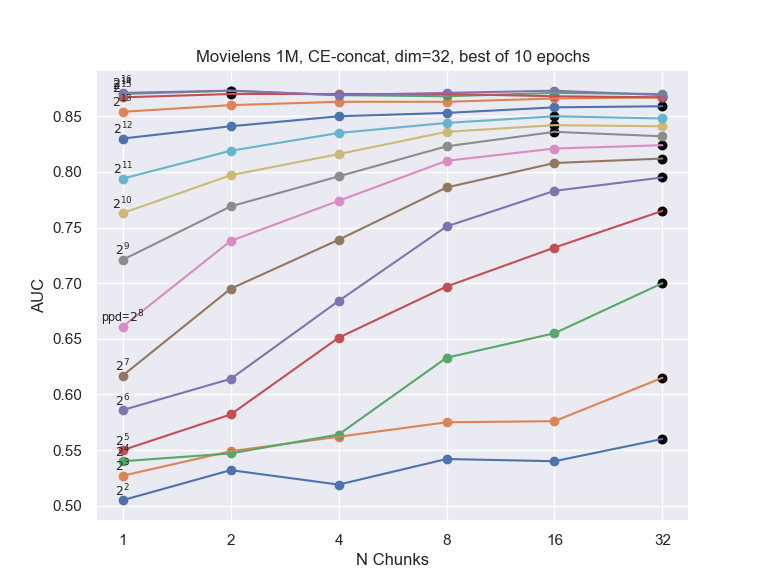
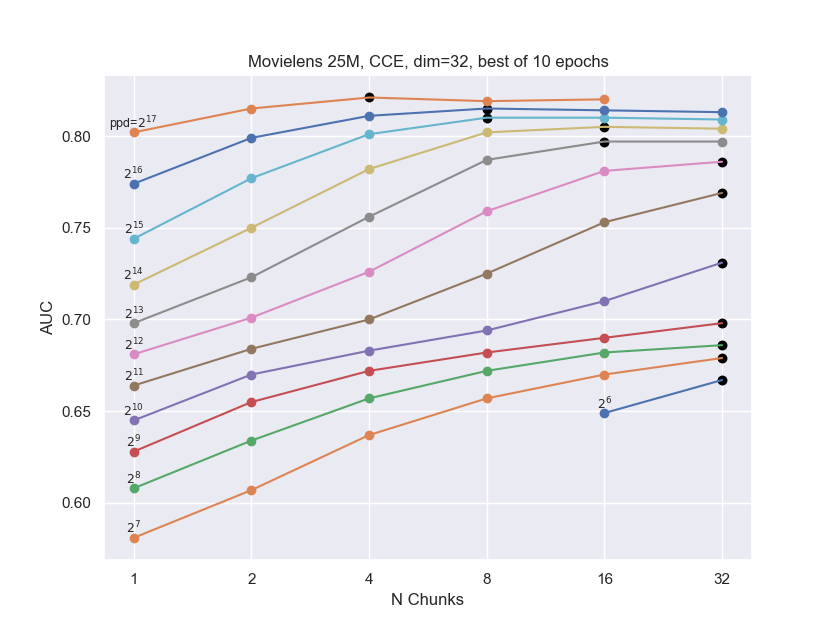
Many of the methods which utilize hashing allow a n_chunks parameter, which defines how many sub-vectors are combined to get the final embedding.
Increasing n_chunks nearly always give better results (as evidenced in the plot below), but it also increases time usage.
In our results above we always used a default of n_chunks=4.
| CE | CCE |
|---|---|
 |
 |