- About the project
- Demo Notebook
- Installation
- Usage
- Sample Pipeline Example
- Quick API guide
- Functionalities
- Limitation
Delta Live Tables (DLTs) are a great way to design data pipelines with only focusing on the core business logic. It makes the life of data engineers easy but while the development workflows are streamlined in DLT, when it comes to debugging and seeing how the data looks after each transformation step in a typical DLT pipeline it becomes very tedious as we dont have the DLT package available in our interactive environment.
Enter dlt-with-debug a lightweight decorator utility which allows developers to do interactive pipeline development by having a unified source code for both DLT run and Non-DLT interactive notebook run.
- Python's builtins
Click here to go to a sample notebook which you can import in your workspace to see the utility in action
pip install in your Databricks Notebook
PyPI
%pip install dlt-with-debug-
In our notebooks containing DLT Jobs the imports changes slightly as below and also the extra decorator
@dltwithdebug(globals())is added to the functions# Imports from dlt_with_debug import dltwithdebug, pipeline_id, showoutput if pipeline_id: import dlt else: from dlt_with_debug import dlt # Now define your dlt code with one extra decorator "@dltwithdebug(globals())" added to it @dlt.create_table(comment = "dlt pipeline example") @dltwithdebug(globals()) def click_raw_bz(): return ( spark.read.option("header","true").csv("dbfs:/FileStore/souvikpratiher/click.csv") ) # See the output showoutput(click_raw_bz) # Get the output data to a dataframe df = click_raw_bz()
Note:
- Use the
dlt.create_table()API instead ofdlt.table()asdlt.table()sometimes gets mixed withspark.table()in the global namespace.- Always pass the
globals()namespace todltwithdebugdecorator like this@dltwithdebug(globals())
Code:
Cmd 1
%pip install -e git+https://github.com/souvik-databricks/dlt-with-debug.git#"egg=dlt_with_debug"Cmd 2
from pyspark.sql.functions import *
from pyspark.sql.types import *
# We are importing
# dltwithdebug as that's the entry point to interactive DLT workflows
# pipeline_id to ensure we import the dlt package based on environment
# showoutput is a helper function for seeing the output result along with expectation metrics if any is specified
from dlt_with_debug import dltwithdebug, pipeline_id, showoutput
if pipeline_id:
import dlt
else:
from dlt_with_debug import dltCmd 3
json_path = "/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed-json/2015_2_clickstream.json"Cmd 4
# Notice we are using dlt.create_table instead of dlt.table
@dlt.create_table(
comment="The raw wikipedia click stream dataset, ingested from /databricks-datasets.",
table_properties={
"quality": "bronze"
}
)
@dltwithdebug(globals())
def clickstream_raw():
return (
spark.read.option("inferSchema", "true").json(json_path)
)Cmd 5
# for displaying the result of the transformation
# use showoutput(func_name)
# for example here we are using showoutput(clickstream_raw)
showoutput(clickstream_raw)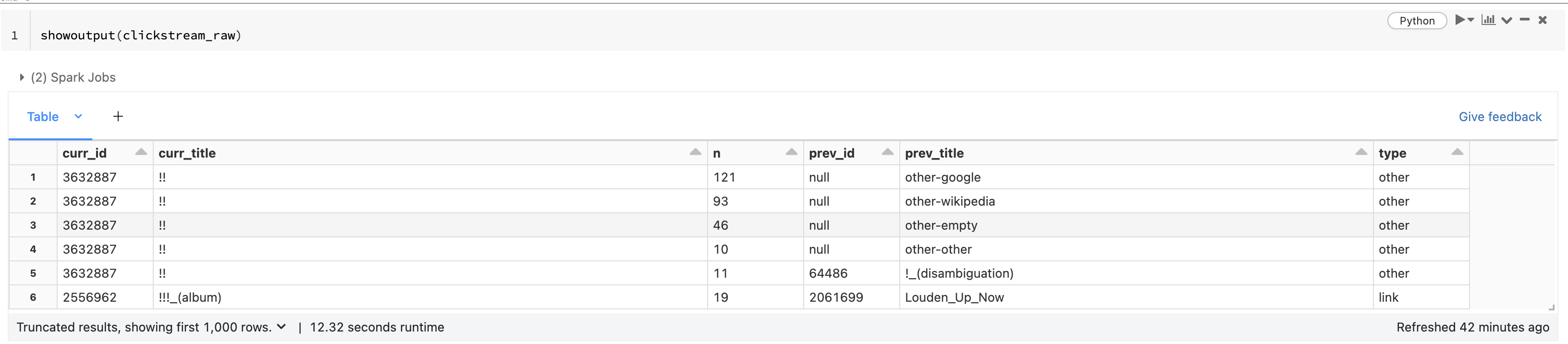
Cmd 6
@dlt.create_table(
comment="Wikipedia clickstream dataset with cleaned-up datatypes / column names and quality expectations.",
table_properties={
"quality": "silver"
}
)
@dlt.expect("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
@dlt.expect_or_fail("valid_count", "click_count > 0")
@dlt.expect_all({'valid_prev_page_id': "previous_page_id IS NOT NULL"})
@dltwithdebug(globals())
def clickstream_clean():
return (
dlt.read("clickstream_raw")
.withColumn("current_page_id", expr("CAST(curr_id AS INT)"))
.withColumn("click_count", expr("CAST(n AS INT)"))
.withColumn("previous_page_id", expr("CAST(prev_id AS INT)"))
.withColumnRenamed("curr_title", "current_page_title")
.withColumnRenamed("prev_title", "previous_page_title")
.select("current_page_id", "current_page_title", "click_count", "previous_page_id", "previous_page_title")
)Cmd 7
showoutput(clickstream_clean)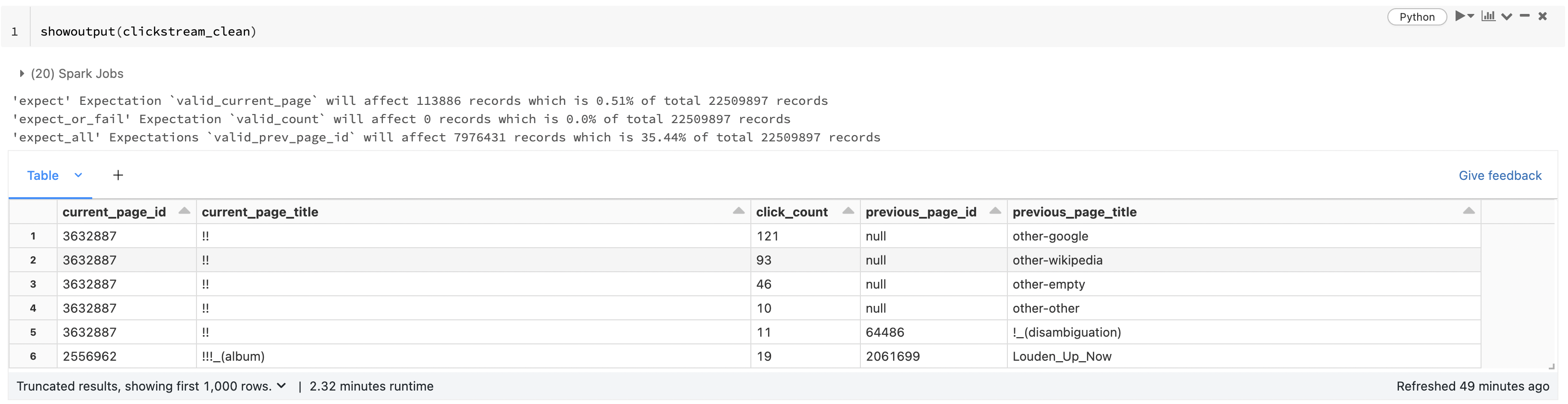
Important to note that here you can see we are also seeing how many records will the expectations affect.

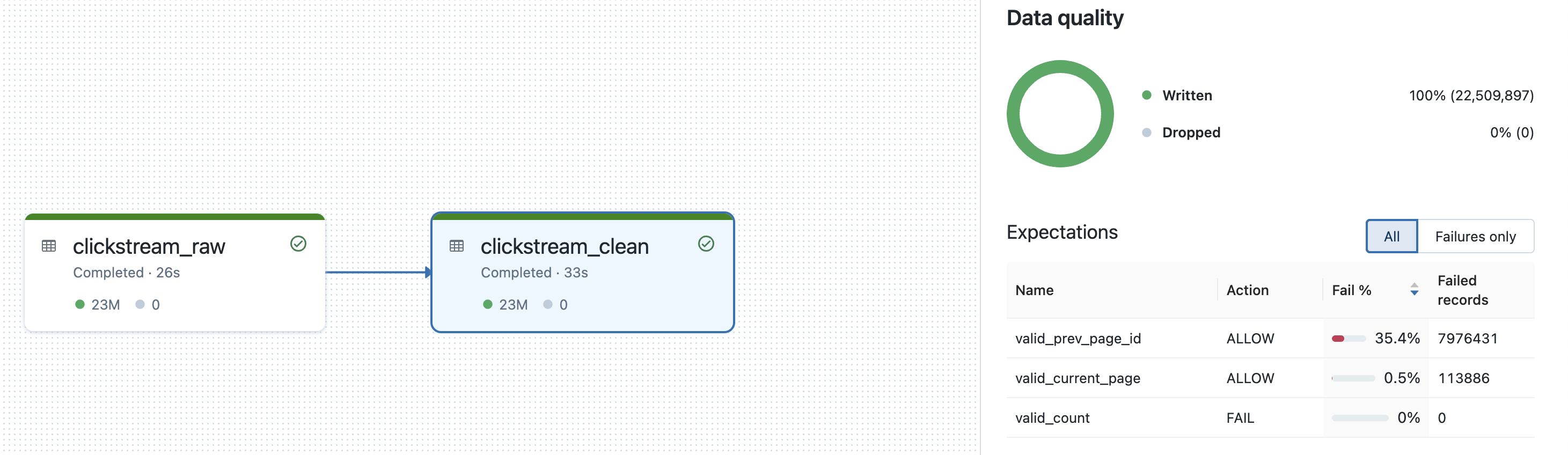
Below we can see the expectation results also match up with the expectation metrics that we got from dltwithdebug earlier with
showoutput(clickstream_clean)
@dlt.create_table( # <-- Notice we are using the dlt.create_table() instead of dlt.table()
name="<name>",
comment="<comment>",
spark_conf={"<key>" : "<value", "<key" : "<value>"},
table_properties={"<key>" : "<value>", "<key>" : "<value>"},
path="<storage-location-path>",
partition_cols=["<partition-column>", "<partition-column>"],
schema="schema-definition",
temporary=False)
@dlt.expect
@dlt.expect_or_fail
@dlt.expect_or_drop
@dlt.expect_all
@dlt.expect_all_or_drop
@dlt.expect_all_or_fail
@dltwithdebug(globals()) # <-- This dltwithdebug(globals()) needs to be added
def <function-name>():
return (<query>)@dlt.create_view( # <-- Notice we are using the dlt.create_view() instead of dlt.view()
name="<name>",
comment="<comment>")
@dlt.expect
@dlt.expect_or_fail
@dlt.expect_or_drop
@dlt.expect_all
@dlt.expect_all_or_drop
@dlt.expect_all_or_fail
@dltwithdebug(globals()) # <-- This dltwithdebug(globals()) needs to be added
def <function-name>():
return (<query>)showoutput(function_name) # <-- showoutput(function_name)
# Notice we are only passing the function name
# The name of the function which is wrapped by the dltdecorators
# For example:
# @dlt.create_table()
# @dltwithdebug(globals())
# def step_one():
# return spark.read.csv()
# showoutput(step_one)# We are importing
# dltwithdebug as that's the entry point to interactive DLT workflows
# pipeline_id to ensure we import the dlt package based on environment
# showoutput is a helper function for seeing the output result along with expectation metrics if any is specified
from dlt_with_debug import dltwithdebug, pipeline_id, showoutput
if pipeline_id:
import dlt
else:
from dlt_with_debug import dltAs of now the following DLT APIs are covered for interactive use:
-
Currently Available:
dlt.readdlt.read_streamdlt.create_tabledlt.create_viewdlt.table<-- This one sometimes gets overridden withspark.tableso usedlt.create_tableinstead.dlt.viewdlt.expectdlt.expect_or_faildlt.expect_or_dropdlt.expect_alldlt.expect_all_or_dropdlt.expect_all_or_fail
-
Will be covered in the upcoming release:
dlt.create_target_tabledlt.create_streaming_live_tabledlt.apply_changes
DLT with Debug is a fully python based utility and as such it doesn't supports spark.table("LIVE.func_name") syntax.
So instead of spark.table("LIVE.func_name") use dlt.read("func_name") or dlt.read_stream("func_name")
Distributed under the MIT License.
Drop a ⭐️ if you liked the project and it helped you to have a smoother experience while working with DLTs