Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Enhance Traceability of Generator Outputs in Promptflow Tracing (#3120)
# Description This PR introduces an enhanced method for capturing the trace of generator output functions within the Promptflow tracing framework. In the previous approach, when a function returned a generator, the associated span would terminate, and the output would be a string representing the generator object. Subsequently, a new span would be initiated when another function consumed this generator. With the modifications proposed in this PR, the span persists beyond the point where a function returns a generator, concluding only after the generator has been fully consumed. Consequently, the output of the span encapsulating the generator or iterator object is now a comprehensive list of the iterated objects. These changes significantly improve the transparency and intelligibility of the tracing process for generator outputs. ## Example with OpenAI Call Consider the following code for a node: ```python @trace def chat(connection: AzureOpenAIConnection, question: str, stream: bool = False): connection_dict = normalize_connection_config(connection) client = AzureOpenAI(**connection_dict) messages = [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": question}] response = client.chat.completions.create(model="gpt-35-turbo", messages=messages, stream=stream) if stream: def generator(): for chunk in response: if chunk.choices: yield chunk.choices[0].delta.content or "" return "".join(generator()) return response.choices[0].message.content or "" @tool def my_python_tool(connection: AzureOpenAIConnection, question: str, stream: bool) -> str: return chat(connection, question, stream) ``` With the changes in this PR, specifying `stream=True` yields a generator object from the `client.chat.completions.create` call. ### Original Implementation  - In the original implementation, two spans were generated for `openai_chat`. The first span ended when the call finished, and the output was a string representing the generator object. The second span started when the generator was consumed and ended when the generator was fully consumed. ### New Implementation 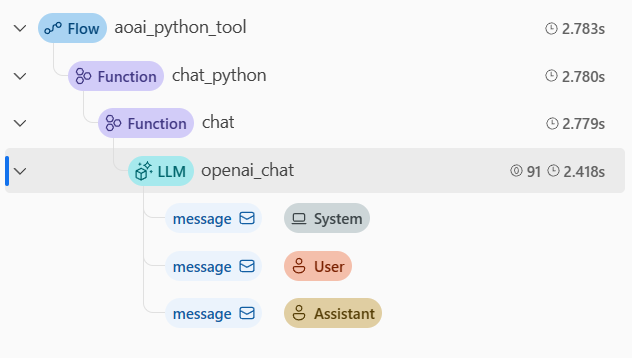 - In the new implementation, only one span is generated for `openai_chat`. The span ends when the generator is fully consumed. # All Promptflow Contribution checklist: - [ ] **The pull request does not introduce [breaking changes].** - [ ] **CHANGELOG is updated for new features, bug fixes or other significant changes.** - [x] **I have read the [contribution guidelines](../CONTRIBUTING.md).** - [ ] **Create an issue and link to the pull request to get dedicated review from promptflow team. Learn more: [suggested workflow](../CONTRIBUTING.md#suggested-workflow).** ## General Guidelines and Best Practices - [x] Title of the pull request is clear and informative. - [x] There are a small number of commits, each of which have an informative message. This means that previously merged commits do not appear in the history of the PR. For more information on cleaning up the commits in your PR, [see this page](https://github.com/Azure/azure-powershell/blob/master/documentation/development-docs/cleaning-up-commits.md). ### Testing Guidelines - [x] Pull request includes test coverage for the included changes.
- Loading branch information
1 parent
c1f9884
commit cd07d6d