




Replace OpenAi's GPT APIs with llama.cpp's supported models locally
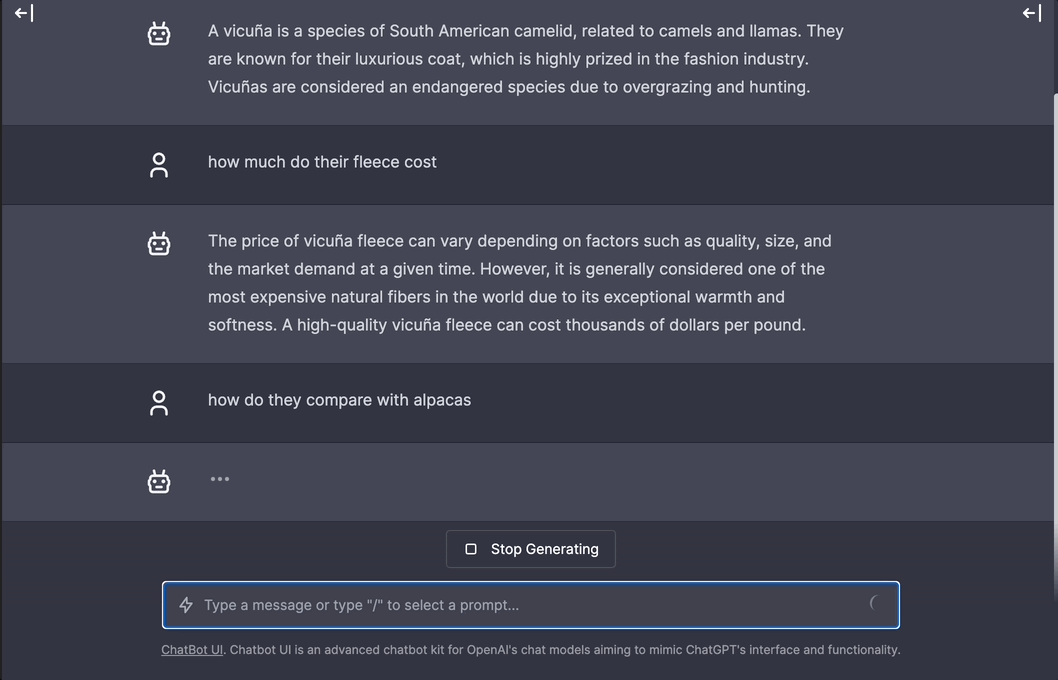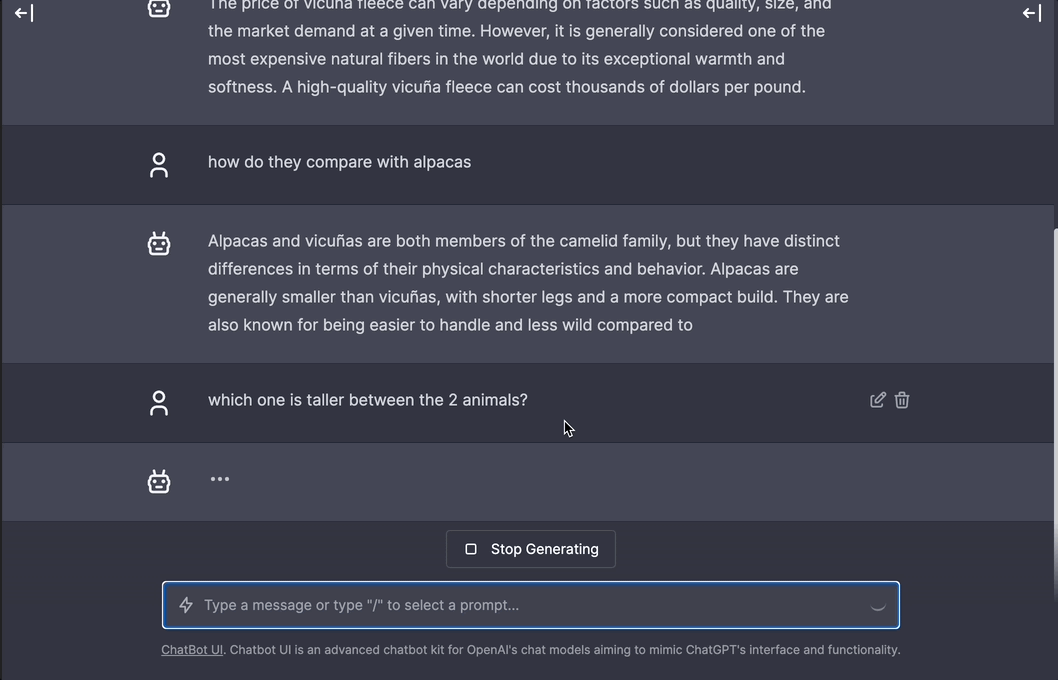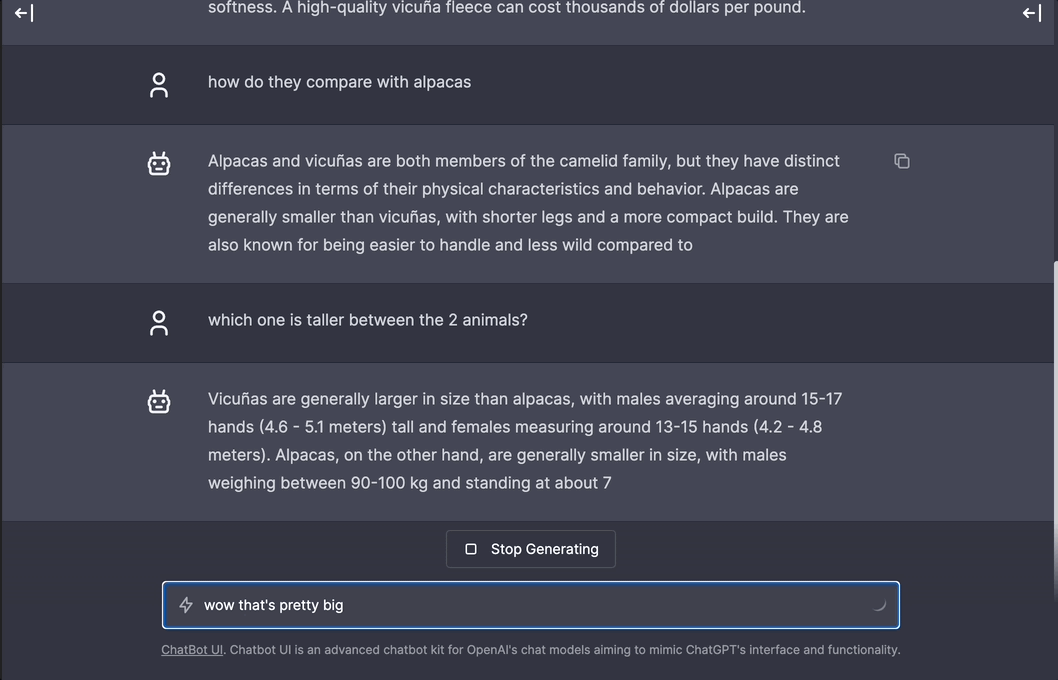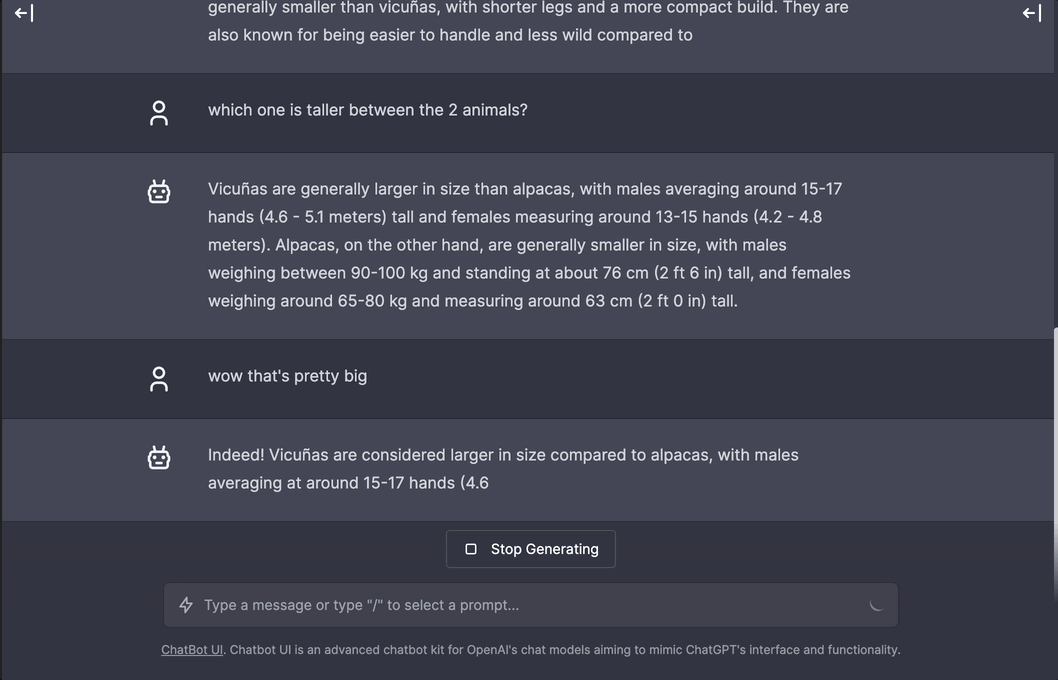 Real-time speedy interaction mode demo of using
Real-time speedy interaction mode demo of using gpt-llama.cpp's API + chatbot-ui (GPT-powered app) running on a M1 Mac with local Vicuna-7B model. See all demos here.
Join our Discord Server community for the latest updates and to chat with the community (200+ members and growing): https://discord.gg/yseR47MqpN
- Langchain support added
- Openplayground support added
- Embeddings support added (non-llama based, higher accuracy)
EMBEDDINGS=py npm start - Text Completion support added
- AUTO-ADD SUPPORT FOR GPT-POWERED APPS WITH PYTHON
add-api-base.pySCRIPT🔥🔥 - DiscGPT (full featured gpt-llama.cpp POWERED Discord BOT) open-sourced, see repo
- Our discord server is running DiscGPT and with the bot named ELIZA
gpt-llama.cpp is an API wrapper around llama.cpp. It runs a local API server that simulates OpenAI's API GPT endpoints but uses local llama-based models to process requests.
It is designed to be a drop-in replacement for GPT-based applications, meaning that any apps created for use with GPT-3.5 or GPT-4 can work with llama.cpp instead.
The purpose is to enable GPT-powered apps without relying on OpenAI's GPT endpoint and use local models, which decreases cost (free) and ensures privacy (local only).
- macOS (ARM)
- macOS (Intel)
- Windows
- Linux
gpt-llama.cpp provides the following features:
- Drop-in replacement for GPT-based applications
- Interactive mode supported, which means that requests within the same chat context will have blazing-fast responses
- Automatic adoption of new improvements from
llama.cpp - Usage of local models for GPT-powered apps
- Support for multiple platforms
The following applications (list growing) have been tested and confirmed to work with gpt-llama.cpp without requiring code changes:
- chatbot-ui - setup guide
- WORKS WITH FORK: Auto-GPT - setup guide here
- Issue tracking this here
- ☘️ NEW langchain - (minimal) SETUP GUIDE SOON
- ChatGPT-Siri - setup guide
- ☘️ NEW openplayground - (minimal) SETUP GUIDE SOON
- ☘️ NEW DiscGPT - (minimal) SETUP GUIDE SOON
- ai-code-translator
- See issue tracking this here
More applications are currently being tested, and welcome requests for verification or fixes by opening a new issue in the repo.
See all demos here.
🔴🔴
Setup llama.cpp by following the instructions below. This is based on the llama.cpp README. You may skip if you have llama.cpp set up already.
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# install Python dependencies
python3 -m pip install -r requirements.txtgit clone https://github.com/ggerganov/llama.cpp
cd llama.cpp- Then, download the latest release of llama.cpp here
I do not know if there is a simple way to tell if you should download
avx,avx2oravx512, but oldest chip foravxand newest chip foravx512, so pick the one that you think will work with your machine. (lets try to automate this step into the future) - Extract the contents of the zip file and copy everything in the folder (which should include
main.exe) into your llama.cpp folder that you had just cloned. Now back to the command line
# install Python dependencies
python3 -m pip install -r requirements.txtConfirm that llama.cpp works by running an example. Replace <YOUR_MODEL_BIN> with your llama model, typically named something like ggml-model-q4_0.bin
# Mac
./main -m models/7B/<YOUR_MODEL_BIN> -p "the sky is"
# Windows
main -m models/7B/<YOUR_MODEL_BIN> -p "the sky is"It'll start spitting random BS, but you're golden if it's responding. You may now move on to running gpt-llama.cpp itself now.
-
Clone the repository:
git clone https://github.com/keldenl/gpt-llama.cpp.git cd gpt-llama.cpp- Strongly recommended folder structure
documents ├── llama.cpp │ ├── models │ │ └── <YOUR_.BIN_MODEL_FILES_HERE> │ └── main └── gpt-llama.cpp
- Strongly recommended folder structure
-
Install the required dependencies:
npm install
-
Start the server!
# Basic usage npm start
You're done! Here are some more advanced configs you can run:
# To run on a different port
# Mac
PORT=8000 npm start
# Windows cmd
set PORT=8000
npm start
# Use llama.cpp flags (use it without the "--", so instead of "--mlock" do "mlock")
npm start mlock threads 8 ctx_size 1000 repeat_penalty 1 lora ../path/lora
# To use sentence transformers instead of llama.cpp based embedding set EMBEDDINGS env var to "py"
# Mac
EMBEDDINGS=py npm start
# Windows cmd
set EMBEDDINGS=py
npm startYou have 2 options:
-
Open another terminal window and test the installation by running the below script, make sure you have a llama .bin model file ready. Test the server by running the
scripts/test-installationscript (currently only supports Mac)# Mac sh ./test-installion.sh -
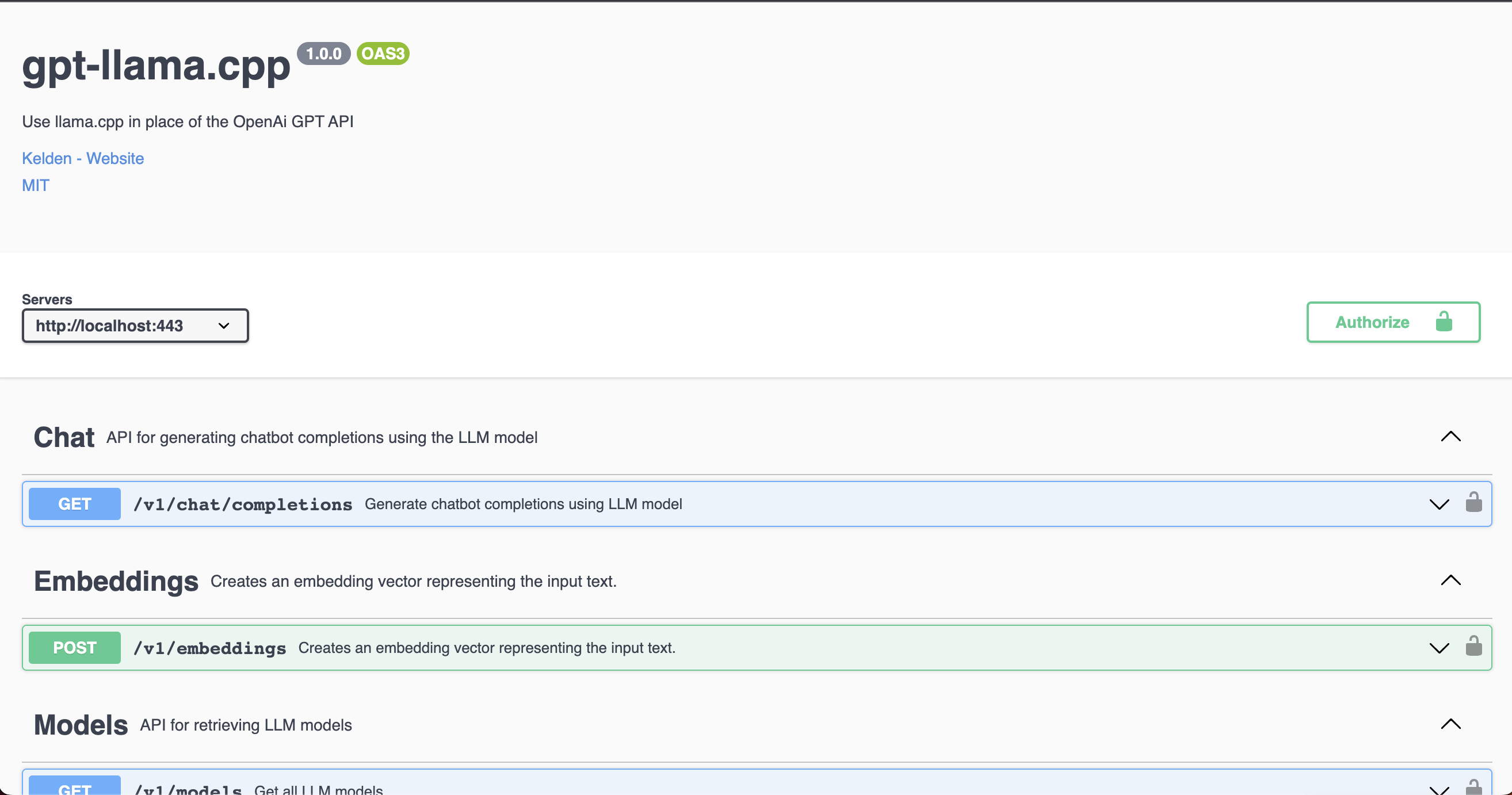
Access the Swagger API docs at
http://localhost:443/docsto test requests using the provided interface. Note that the authentication token needs to be set to the path of your local llama-based model (i.e. for mac,"/Users/<YOUR_USERNAME>/Documents/llama.cpp/models/vicuna/7B/ggml-vicuna-7b-4bit-rev1.bin") for the requests to work properly.
There are 2 ways to set up a GPT-powered app:
-
Use a documented GPT-powered application by following supported applications directions.
-
Use a undocumented GPT-powered application by checking if they support
openai.api_base:- Update the
openai_api_keyslot in the gpt-powered app to the absolute path of your local llama-based model (i.e. for mac,"/Users/<YOUR_USERNAME>/Documents/llama.cpp/models/vicuna/7B/ggml-vicuna-7b-4bit-rev1.bin"). - Change the
BASE_URLfor the OpenAi endpoint the app is calling tolocalhost:443orlocalhost:443/v1. This is sometimes provided in the.envfile, or would require manual updating within the app OpenAi calls depending on the specific application.
- Update the
-
Under no circumstances should IPFS, magnet links, or any other links to model downloads be shared anywhere in this repository, including in issues, discussions, or pull requests. They will be immediately deleted.
-
The LLaMA models are officially distributed by Facebook and will never be provided through this repository.
You can contribute to gpt-llama.cpp by creating branches and pull requests to merge. Please follow the standard process for open sourcing.
This project is licensed under the MIT License. See the LICENSE file for more details.