{kind=link}
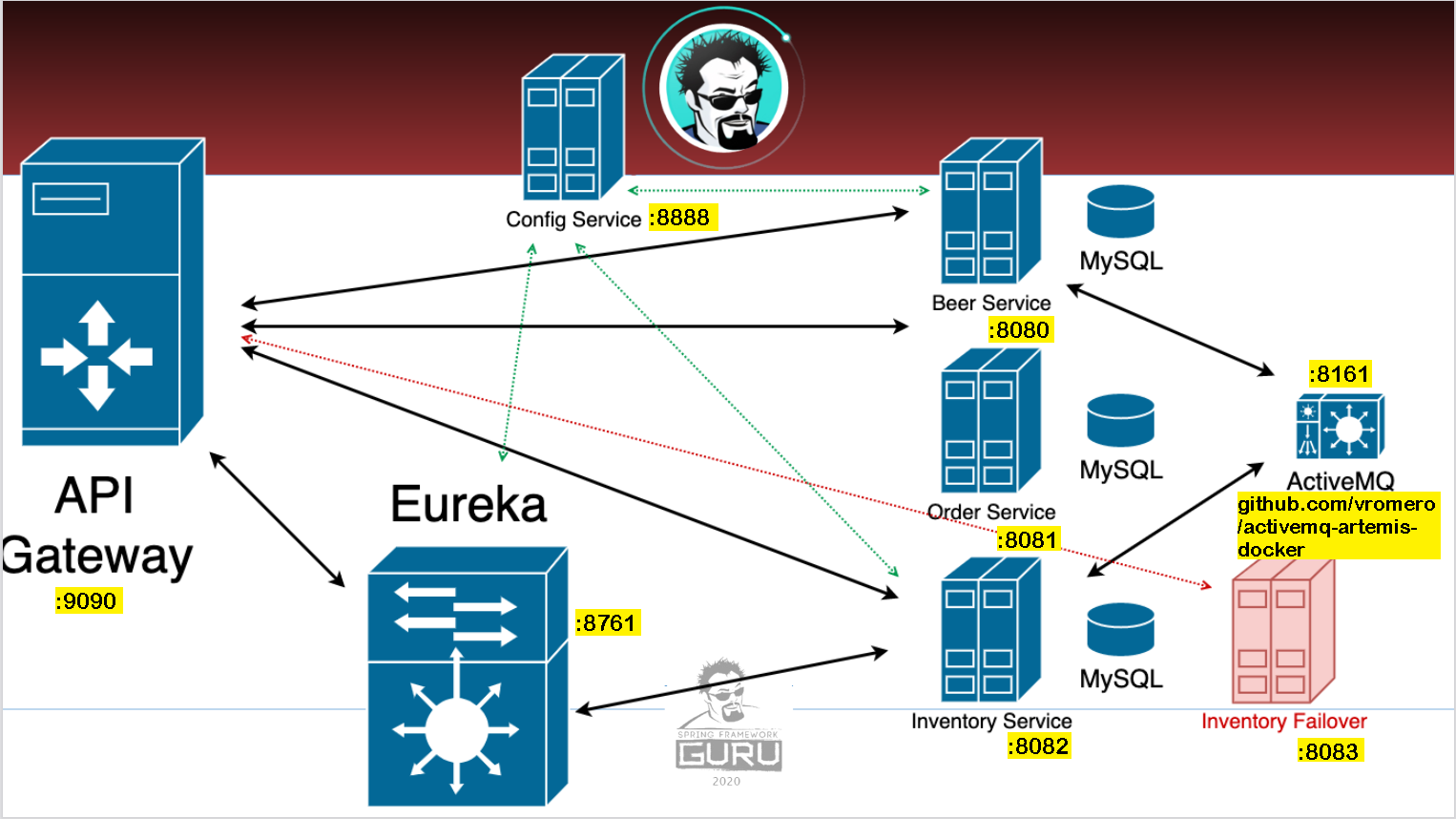
multi-module maven project containing brewery microservices and servers
-
Current configuration "Profiles"
-
inventory-service - local-discovery only
-
beer-service - local-discovery, local-cloud-config
-
beer-order-service - local-discovery, local-cloud-config
-
Also need to run Eureka Server with ("local-discovery") Profile set so that the Failover Service can be found (GET requested by the other Microservices) at http://localhost:8083/inventory-failover
-
Access Eureka Console to verify @ http://localhost:8761/
-
And Cloud Config Repo
-
And ActiveMQ
| Project | |
|---|---|
| KWG MICROSERVICES BREWERY | |
| Service Name | Port |
| Brewery Beer Service | 8080 |
| Brewery Beer Order Service | 8081 |
| Brewery Beer Inventory Service | 8082 |
| Inventory Failover Service | 8083 |
| Netflix Eureka Server | 8761 |
| Spring Cloud Gateway Server | 9090 |
| Spring Cloud Config Server | 8888 |
| Brewery Cloud Config Repo | ----- |
1. Dependency Management
2. (Local) MySQL Configuration
3. JMS Messaging
4. JMS with Microservices
5. Spring State Machine
6. Using Sagas with Spring
7. Integration Testing Sagas
8. Compensating Transactions
9. Spring Cloud Gateway
10. Service Registration
11. Service Discovery
12. Circuit Breaker
13. Spring Cloud Config
14. Distributed Tracing
15. Securing Spring Cloud
16. Building Docker Images
17. Docker Compose
18. Consolidated Logging
19. Docker Swarm
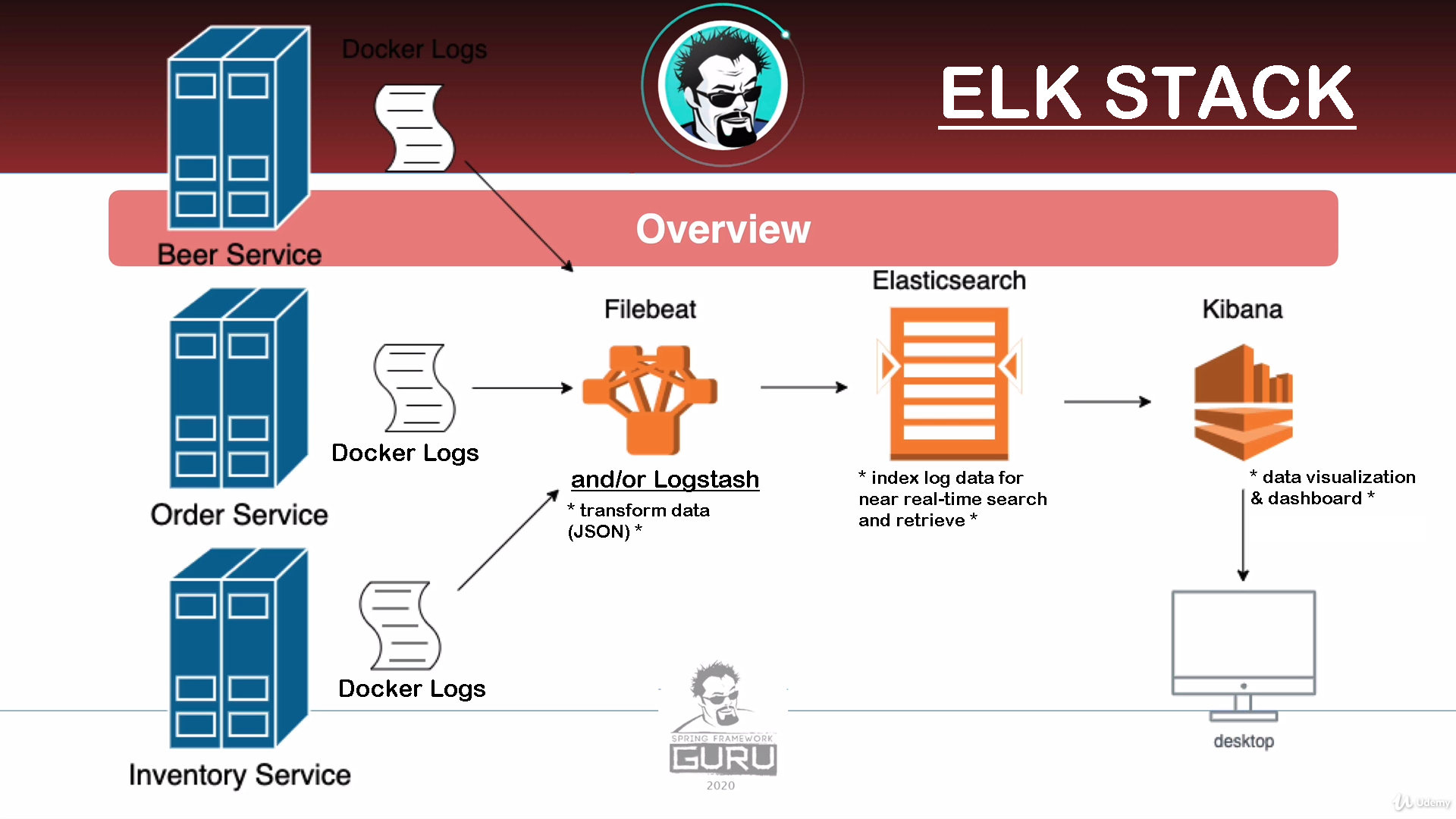
-
All products open source, supported by company called elastic
-
Elasticsearch
- JSON based search engine based on Lucene
- Highly scalable - 100s of nodes (cloud scale)
- JSON based search engine based on Lucene
-
Logstash
- Data processing pipeline for log data
- Similar to ETL tool "Extract-Transform-Load"
- Allows to:
- Collect log data from multiple sources
- Transform that log data
- Send log data to Elasticsearch
- Allows to:
-
Kibana
- Data visualization fool for Elasticsearch
- Can query data and act as a dashboard
- Can also create charts, graphs and alerts
- Many many more features
-
FileBeat
- FileBeat is the log shipper
- Moves log data from a client machine to a destination
- Often destination is a logstash server
- Logstash is used for further transformation before sending to Elasticsearch
-
ELK Without Logstash
- Filebeat has ability to do some transformations
- Thus, possible to skip Logstash and write directly to Elasticsearch
- Previously we setup JSON log output
- Filebeat can convert JSON logs to JSON objects for Elasticsearch
-
Distributed Tracing Overview
- Allows us to see data and process flows as they go through the service
- Ex.) We get a request that comes in through the Gateway, going to Service A, Service B, maybe Service C and then get a response.
- Dstributing Tracing allows you to "see" this flow through the system.
- This is important because if there's a known or unknown failure anywhere in a request path, this allows you to isolate the problem quickly and visualize the chain of events leading to that failure.
-
What is Distributing Tracing?
- Monoliths have luxury of being self-contained, thus tracing typically is not needed.
- Reminder: a simple search request on Amazon is going to span potentially hundreds of microservices to return results - many algorithms, inventory, rating, purchase history, seasonal promotions, etc.
- Transactions in microservices can span across many services / instances and even multiple data centers
- Distributed Tracing provides the tools to trace a transaction across services and nodes
- Distributed Tracing is used primarily for two aspects:
- Perofrmance monitoring across steps
- Logging / Troubleshotting
-
Spring Cloud Sleuth
- Spring Cloud Sleuth is the distributed tracing tool for Spring Cloud
- Spring Cloud Sleuth uses an open source distributed tracing library called "Brave"
- Conceptually what happens:
- Headers on HTTP requests or messages are enhanced with trace data
- Logging is enhanced with trace data
- Optionally trace data can be reported to Zipkin (tracing server)
-
Tracing Terminology
- Spring Cloud Sleuth uses terminology established by Dapper
- Dapper is a distributed tracing system created by Google for their production systems
- Span - is a basic unit of work. Typically a send and receive of a message
- Trace - A set of spans for a transaction
- CS/SR - Client Sent / Sender Received - aka the request
- SS/CR - Sender Sent / Client Received - aka the response
- Spring Cloud Sleuth uses terminology established by Dapper
-
Zipkin Server
- Zipkin is an open source project used to report distributed tracing metrics
- Information can be reported to Zipkin via webservices via HTTP
- Optionally metrics can be provided via Kafka or Rabbit
- Zipkin is a Spring MVC project
- Recommended to use binary distribution or Docker image
- Building your own is not supported
- Uses in-memory database for development
- Cassandra or Elasticsearch should be used for production for data persistence
-
Zipkin Quickstart
- https://zipkin.io/pages/quickstart.html
- via Curl: curl -sSL https://zipkin.io/quickstart.sh | bash -s java -jar zipkin.jar
- via Docker (Recommended): docker run -d -p 9411:9411 openzipkin/zipkin
- View traces in UI at:
-
Installing Spring Cloud Sleuth
- org.springframework.cloud : spring-cloud-start-sleuth
- Starter for logging only
- org.springframework.cloud : spring-cloud-starter-zipkin
- Start for Sleuth with Zipkin - includes Sleuth dependencies
- Property spring.zipkin.baseUrl is used to configure Zipkin server
- org.springframework.cloud : spring-cloud-start-sleuth
-
Logging Output Spring Cloud Sleuth
- Example: - DEBUG [beer-service, 354as6d8f76, 57a4sdfa54, true]
- [Appname, TraceId, SpanId, exportable]
- Appname - Spring Boot Application Name
- TraceId - Id value of the trace
- SpanId - Id of the span
- Exportable - Should span be exported to Zipkin? (Programmatic configuration option)
- Example: - DEBUG [beer-service, 354as6d8f76, 57a4sdfa54, true]
-
Loggin Configuration
- Microservices will typically use consolidated logging
- Number of different approaches for this - highly dependent on deployment environment
- To supposed consolidated logging, log data should be available in JSON
- Spring Boot by default uses logback, which is easy to configure for JSON output
-
JVM Resource Limits
- Java 11 or higher is recommended
- Earlier versions of Java did not recognize limits on memory and CPUs of a container
- Java would see system memory, not the container
- Docker will terminate a container when resource limits are exceeded
- Difficult to troubleshoot
- ex.) you're running your container and all of a sudden it crashes
- you might spend hours debugging the container/program when it's Java itself
-
Docker Host Considerations
- Running multiple Docker contaienrs on a host can be resource intensive
- Can also consume a lot of disk space on host system
- Recommendations:
- Use 'slim' base images - you don't need a full featured linux OS for Java runtime
- Be aware of build layers as you build images
- A host system only needs one copy of a layer
- ex.) you have 12 microservices and 5 layers, but the first 4 layers are all shared by the 12 microservices
- so you only need 1 of each of the first 4 layers - not 12 x 4 = 48 layers
-
Which Base Image?
- Highly debated and opinionated in Java Community
- We will be using OpenJDK Slim - appropriate for ~95% of applications
- Opionated options are from Fabric8 are a good choice
- Azul Systems published curated JVM Docker images, good choice for commercial applications
- For security and compliance, companies might want to build their own base image
-
Building Docker Images with Maven
- Maven can be configured to build and work with Docker images
- Capability is done with Maven plugins
- Several very good options available
- Will be using Fabric8's Maven Docker Plugin (pronounce 'fabricate')
- Very versatile plugin w/ rich capabilities - only using for build
- Fabric8 is a DevOps platofrm for Kubernetes and Openshit - worth becoming more familiar with
- This Maven Docker Plugin is 1 tool of many in that platform
-
Docker Integration Under the Hood
- The Docker Maven Plugins work with Docker installed on your system
- Generally, will autodetect the Docker daemon
- This can be different depending on OS
- If Fabric8 cannot connect to Docker you may need to configure the plugin
- Under the Maven POM properties element:
- Set property 'docker.host' for your OS
- Difficulties with versions of Windows older than Windows 10
- Under the Maven POM properties element:
- The Docker Maven Plugins work with Docker installed on your system
-
Building Docker Images with Maven
- For microservices using common BOM
- Fabric8 is configured in parent
- Each service will need a Dockerfile in /src/main/docker
- For microservices NOT using common BOM
- Fabric8 will need to be configured in Build element of Maven POM
- Each service will need a Dockerfile in /src/main/docker
- For microservices using common BOM
-
Spring Boot Layered Builds
- Common best practice
- Layered builds is a new feature with Spring Boot 2.3.0
- https://springframework.guru/why-you-should-be-using-spring-boot-docker-layers/
- We will be configuring our builds to perform layered builds
- Services using BOM need to use 1.0.17 or higher
- Services not using BOM need to use Spring Boot 2.3.0 or higher
-
Publishing to Docker Hub
- If you've created a Docker Hub account and wish to publish to your own account:
-
Configure server credentials in settings.xml (User home dir/.m2)
-
In servers element, add server with id of 'docker.io'
-
add your username and password to respective elements
-
https://www.udemy.com/course/spring-boot-microservices-with-spring-cloud-beginner-to-guru/learn/lecture/20071480#questions/11674030 - Depends what OS you are using.
Unix/Mac OS X – ~/. m2/repository. Windows – C:\Users\{your-username}\. m2\repository. Create a settings.xml file if one does not exist and add <?xml version="1.0" encoding="UTF-8"?> <settings> <servers> <server> <id>registry.hub.docker.com</id> <username><DockerHub Username></username> <password><DockerHub Password></password> </server> </servers> </settings> -
Running Docker build in IntelliJ
-
first run maven clean, maven package
-
Under Maven/ {application} / Plugins / docker / docker:build to build a local image on the computer
-
to push to DockerHub using Maven - before pushing, remember to log out, then log in from the command line to your docker hub account - # you may need log out first
docker logoutref. https://stackoverflow.com/a/53835882/248616 docker loginAccording to the docs: You need to include the namespace for Docker Hub to associate it with your account. The namespace is the same as your Docker Hub account name. You need to rename the image to YOUR_DOCKERHUB_NAME/docker-whale. So, this means you have to tag your image before pushing: docker tag firstimage YOUR_DOCKERHUB_NAME/firstimage and then you should be able to push it. docker push YOUR_DOCKERHUB_NAME/firstimage - mvn clean package docker:build docker:push -
need to push each server/microservice up to DockerHub
- Docker interview with John Thompson and James Labocki of Redhat on Docker
- https://www.udemy.com/course/spring-boot-microservices-with-spring-cloud-beginner-to-guru/learn/lecture/20118108#questions
-
-
- If you've created a Docker Hub account and wish to publish to your own account:
-
What is JMS?
- JMS is a Java API which allows a Java Application to send a message to another application
- Generally the other application is a Java application - but not always!
- JMS is a standard Java API which requires an underlying implementation to be provided
- For example, JPA - where JPA is the API standard, and Hibernate is the implementation
- JMS is highly scalable and allows you to loosely couple applications using asynchronous messaging
- JMS is a Java API which allows a Java Application to send a message to another application
-
JMS Implementations
- Amazon SQS
- Apache ActiveMQ - used in this project
- JBoss Messaging
- IBM MQ (closed source / paid)
- OracleAQ - (closed source / paid)
- RabbitMQ
- Many more!
-
Why use JMS over REST?
- JMS is a true messaging service
- Asynchronous - send it and forget it!
- Greater throughput - the HTTP protocol is slow comparatively
- JMS protocols are VERY performant
- Flexibility in message delivery - Deliver to one or many consumers
- Security - JMS has very robust security
- Reliability - Can guarantee message delivery
-
Types of Messaging
-
Point to Point
- Message is queued and deliver to one consumer
- Can have multiple consumers - but message will be delivered only ONCE (ie to exactly one consumer)
- Consumers connect to a queue
-
Publish / Subscribe
- Message is delivered to one or more subscribers
- Subscribers will subscribe to a topic, then receive a copy of all messages sent to the topic
-
-
Key Terms
- JMS Provider - JMS Implementation
- JMS Client - Application which sends or receives messages from the JMS Provider
- JMS Producer (Publisher) - JMS Client which sends messages
- JMS Consumer (Subscriber) - JMS Client which receives messages
- JMS Message - the entity of data sent (see below)
- JMS Queue - Queue for point to point messages. Often, not always, FIFO
- JMS Topic - Similiar to a queue - but for publish & subscribe
-
-
-
- contains meta data about the message
-
- Message properties are in 3 sections:
- Application - From Java Application sending message
- Provider - Used by the JMS Provider and are implementation specific
- Standard Properties - Defined by the JMS API - might not be supported by the Provider
- Message properties are in 3 sections:
-
- the message itself
-
-
-
- String - typically a UUID. Set by application, often used to trace a message through multiple consumers
-
- Long
- zero, does not expire.
- else, time when message will expire and be removed form the queue.
- Long
-
- String - typically set by the JMS Provider
-
- Integer - Priority of the message
-
- Long - Time message was sent
-
- String - The type of the message
-
- Queue or topic to which sender is expecting replies
-
- Boolean - Has messaged been re-delivered?
-
- Integer
- set by JMS Provider for Delivery Mode
- Persistent (Default) - JMS Provider should make best effort to deliver message
- Non-Persistent - Occasional message loss is acceptable
- set by JMS Provider for Delivery Mode
- Integer
-
-
-
- String - User ID sending message. Set by JMS Provider.
-
- String - ID of the application sending the message. Set by JMS Provider.
-
- Int - Number of delivery attempts. Set by JMS Provider.
-
- String - The message group which the message if part of. Set by JMS Client.
-
- Int - Sequence number of message in group. Set by JMS Client.
-
- String - Transaction ID when message was produced. Set by JMS Producer.
-
- String - Transaction ID when the message was consumed. Set by JMS Provider.
-
- Long - Timestamp when messaged delivered to consumer. Set by JMS Provider.
-
- Int - State of the JMS Message. Set by JMS Provider.
-
-
- typically where work/config about the metadata occurs
- JMS Client can set custom properties on messages
- Properties are set as key / value pairs (String, value)
- Values must be one of:
- String, boolean, byte, double, float, int, short, long or Object
-
- The JMS Client can also set JMS Provider Specific properties
- These properties are set as JMS_
- JMS Provider specific properties allow the client to utilize features specific to the JMS Provider
- Refer to documentation of your selected JMS Provider for details
-
-
- Just a message, no payload. Often used to notify about events.
-
- Payload is an array of bytes
-
- Message is stored as a string (often JSON or XML)
-
- sequence of Java primitives
-
- message is name value pairs
-
- Message is a serialized Java object
-
-
- JMS 1.0 was originally released in 1998 - initial focus was on Java to Java messaging
- Since 1998, Messaging and technology have grown and evolved beyond the Java ecosystem
- JMS TextMessages with JSON or XML payloads are currently favored
- Decoupled from Java - can be consumed by any technology
- Not uncommon to 'bridge' to non-java providers
- Makes migration to a non-JMS provider less painful
- Important since messaging is becoming more and more generic and abstracted
- Fore example, tools like Spring Integration
- where an application sends a message and as a developer you are completely unaware of what the messaging infrastructure is
-