🛠️ Image-to-Text extraction from image and PDF files. Uses the open-sourced Tesseract OCR Engine & JNA Java Wrapper Class.
A native Desktop application built with Tess4J in Java.
- Multiple image/PDF file uploads
- Text extraction from image/PDF files
- Export to text file
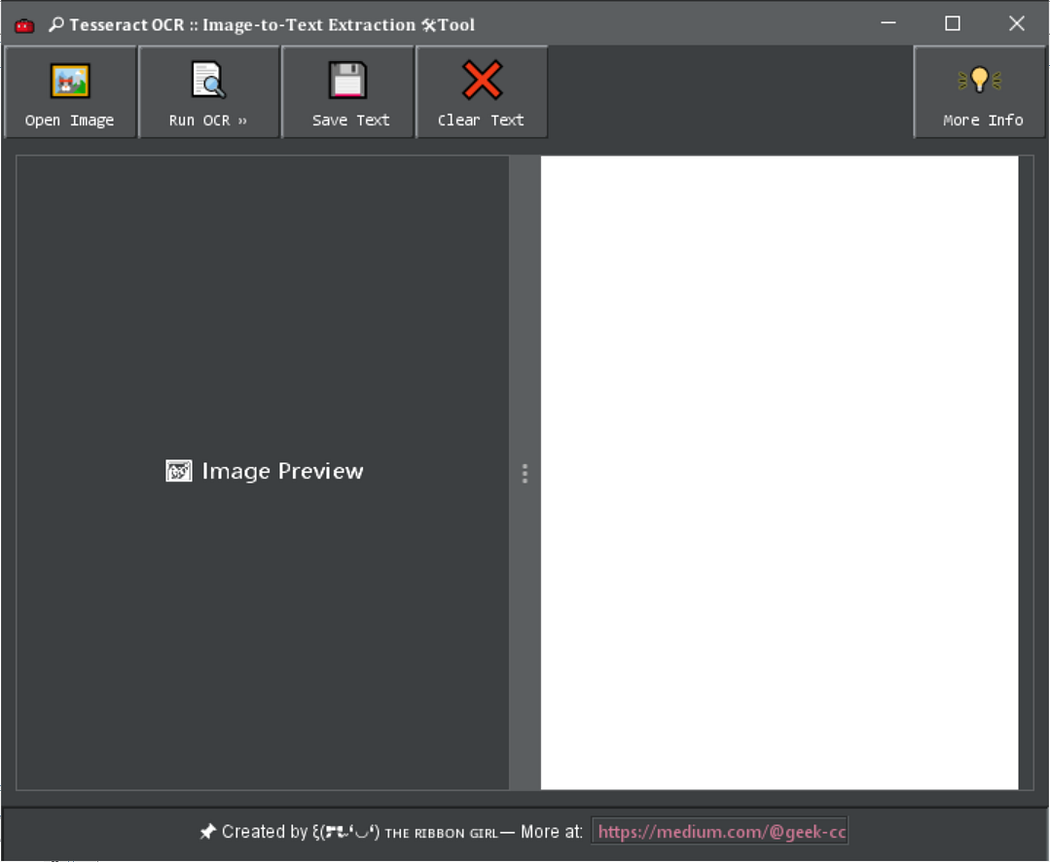
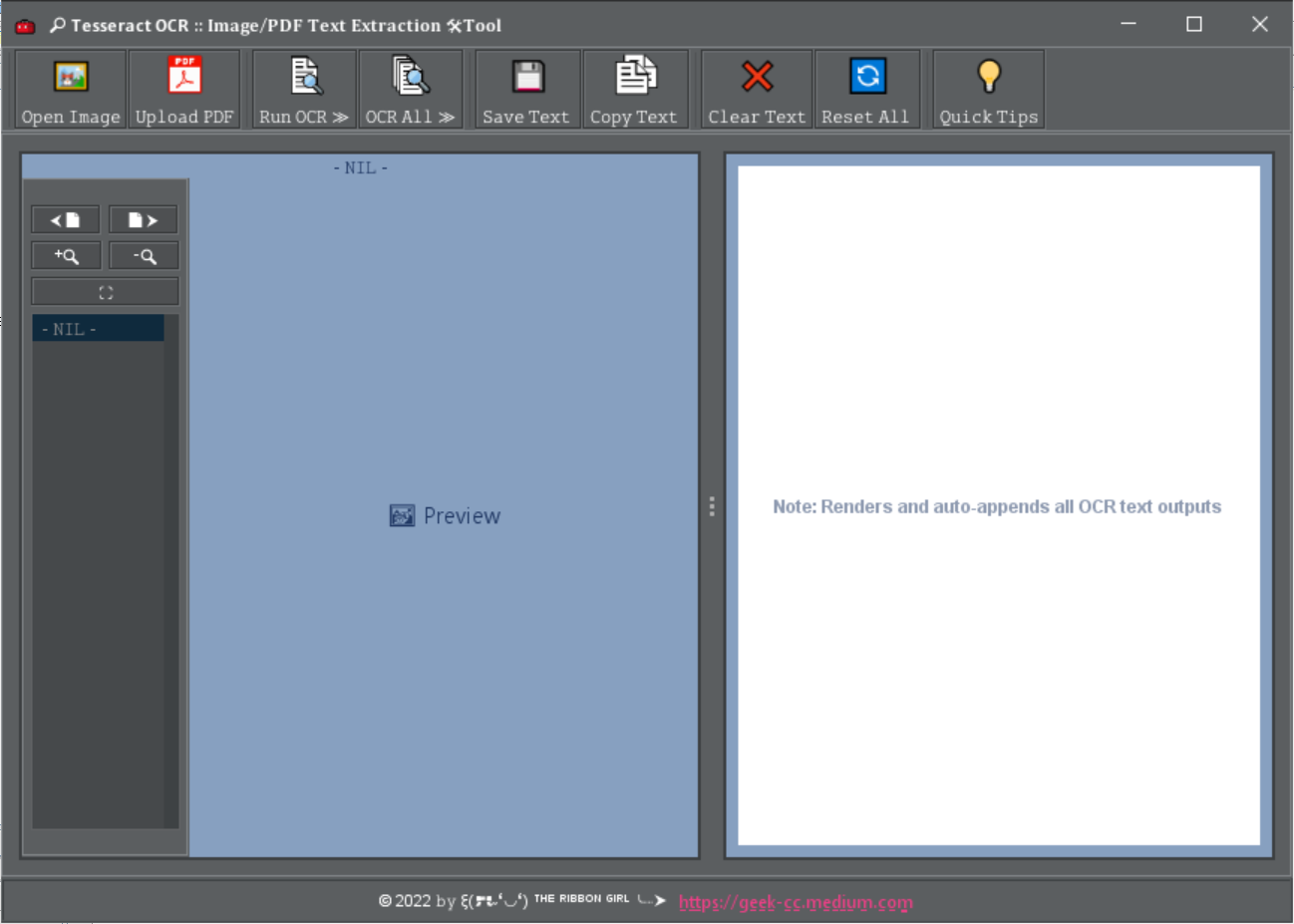


Note: As of current, the latest version is available in the folder at v4x.
Both Tesseract and this Software are licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
— Join me on 📝 Medium at ~ ξ(🎀˶❛◡❛) @geek-cc