- 본 프로젝트는 ‘어르신을 위한 인공지능 비서'의 TTS 시스템 개발을 목표로 합니다. 5분의 음성 녹음만으로, 가족 또는 친구, 연인의 목소리를 가진 인공지능 비서를 만들 수 있습니다.
- 실시간으로 생성이 필요한 인공지능 스피커에 대응하기 위해, Non-Autoregressive Acoustic Model FastSpeech2과 GAN 기반 Vocoder Model HiFi-GAN을 채택하여 품질과 생성 속도를 고려했습니다.
- Multi-Speaker의 성능 향상을 위해, 추가적인 커스텀이 진행되었습니다.
- 본 레포지토리는 D-vector Multi Speaker FastSpeech2, HiFi-GAN 모델을 Fine-Tune이 가능하도록 구성하기 위해 shell script를 활용하여, 학습과 생성 과정을 간단히 수행할 수 있도록 구성했습니다.
- 어플에서 실시간 TTS를 제공하기 위해, FastAPI를 활용하여 서버를 구성하고 Backend와 연동합니다.
-
Acoustic-Fastspeech2(Custom), Vocoder-HiFiGAN 모델을 활용한 고성능 및 고속 음성합성
-
소량의 데이터로 개인화를 위한 Transfer Learning을 활용해 합리적인 성능 제공
-
실시간으로 한국어 데이터셋에 Fine-Tune과 생성이 가능한 API 제공
- dataset 폴더에 속한 fine_tune_transcript.txt에 따라 스마트폰으로 숫자에 따라 100문장을 녹음하고, m4a 파일을 sampling rate가 16000인 wav 파일로 변환합니다. (ffmpeg)
- 그림과 같이 변환된 wav 파일 100개를 본인 이니셜 폴더에 넣어 준비합니다.
-
Fine-tune에 맞게 모델 코드 수정
- FastSpeech2와 HiFi-GAN 수정 및 통합
- Dataset, ckpt, results 디렉토리를 최상위 디렉토리에 데이터셋 별로 구분
-
Shell Script를 통한 간편한 preprocess, train, synthesis 수행
- dataset 디렉토리의 바꿔줌으로써
-
독자적인 docker image 제공
- 복잡한 추가 의존성 패키지 추가 없이 바로 수행 가능한 이미지 제공
- 도커 허브 링크를 통해 latest 이미지 불러오기
-
FastSpeech2와 HiFi-GAN pre-trained ckpt의 파일명을 일치시킨 후 모델 각 디렉토리에 보관합니다.
(FastSpeech2: 3만 step 학습 / HiFi-GAN - Jungil King 저자분의 공식 pretrained - UNIVERSAL_V1)
-
학습과 합성을 위해 모든 의존성 패키지가 포함된 도커 이미지를 불러와 실행합니다.
docker pull hws0120/e2e_speech_synthesis -
run_FS2_preprocessing.sh 단계는 conda 명령어로 도커 내 가상환경에 접속하고 python 패키지 jamo를 설치합니다.
conda activate aligner pip install jamo -
run_FS2_train 또는 synthesis를 수행하기 위해 가상 환경을 종료합니다.
conda activate base
-
위 항목을 모두 충족하면 shell script를 실행하여 mfa를 추출합니다.
sh run_FS2_preprocessing.sh # Enter the dataset name [Dataset_Name](ex. HW)
-
성공적으로 textgrid를 생성하면 가상환경을 종료하고 학습 스크립트를 실행합니다.
sh run_FS2_train.sh # Enter the dataset name [Dataset_Name](ex. HW) -
FastSpeech2 5000 step 학습이 완료되면, HiFi-GAN 스크립트를 실행합니다.
sh run_HiFi-GAN_train.sh # Enter the dataset name [Dataset_Name](ex. HW)
-
ckpt 폴더에 학습된 모델이 준비되면 합성을 위한 스크립트를 실행합니다.
sh run_FS2_synthesize.sh # Enter the dataset name [Dataset_Name](ex. HW)
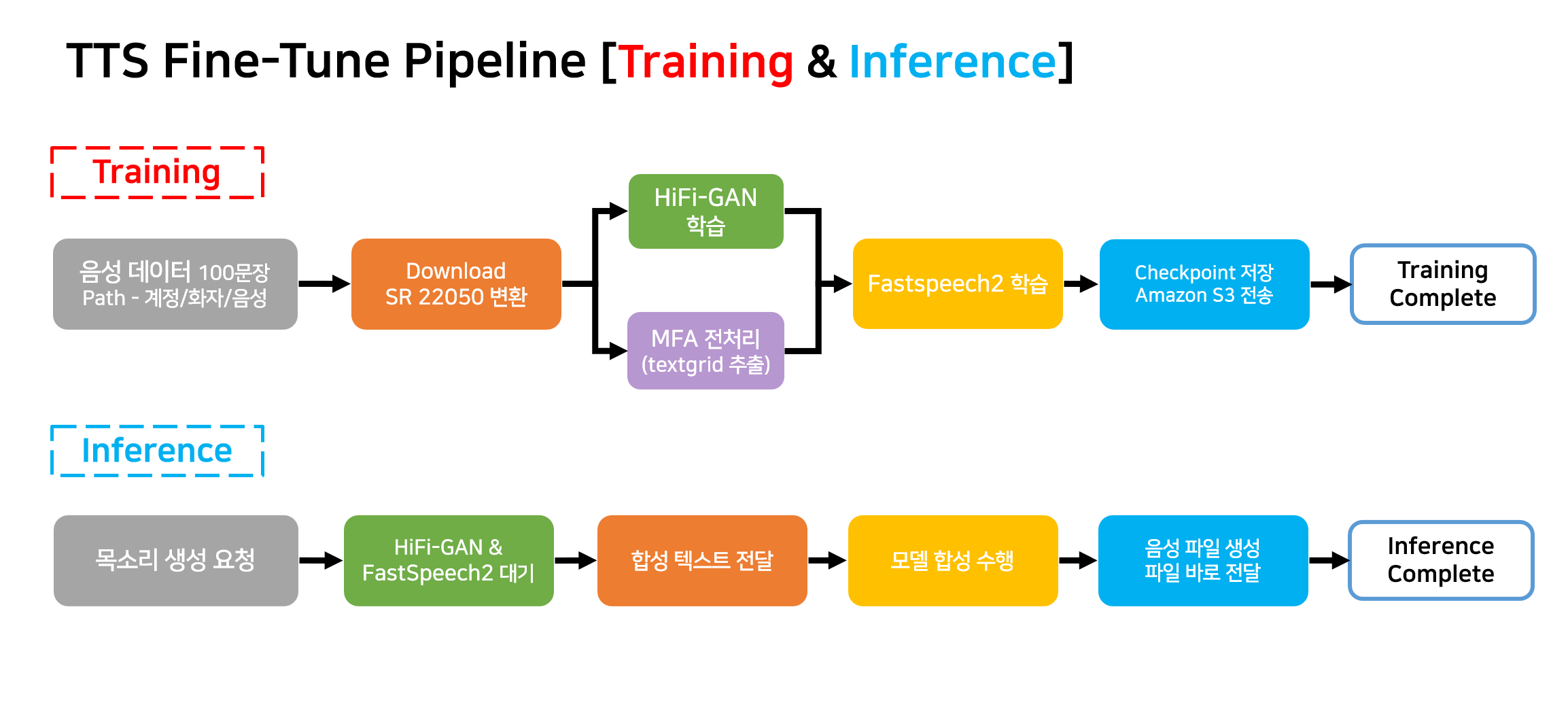
학습 및 합성 과정에서 각각의 컨테이너를 구축하고 그림과 같은 과정을 수행합니다.
적절한 HiFi-GAN 체크포인트가 있을 경우, HiFi-GAN 학습은 생략하셔도 무방합니다.