A curated list for Efficient Large Language Models
- Knowledge Distillation
- Network Pruning
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware/System
- Tuning
- Survey
- Leaderboard
Please check out all the papers by selecting the sub-area you're interested in. On this page, we're showing papers released in the past 30 days.
- May 29, 2023: We've had this awesome list for a year now 🥰! It's grown pretty long, so we're reorganizing it and would divide the list by their specific areas into different readme.
- Sep 27, 2023: Add tag
for papers accepted at NeurIPS'23.
- Sep 6, 2023: Add a new subdirectory project/ to organize those projects that are designed for developing a lightweight LLM.
- July 11, 2023: In light of the numerous publications that conduct experiments using PLMs (such as BERT, BART) currently, a new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs but have yet to be verified for their effectiveness on LLMs (not implying that they are not suitable on LLM).
Paper from 05/26/2024 - Now (Full List)
| Title & Authors | Introduction | Links |
|---|---|---|
| Network Pruning | ||
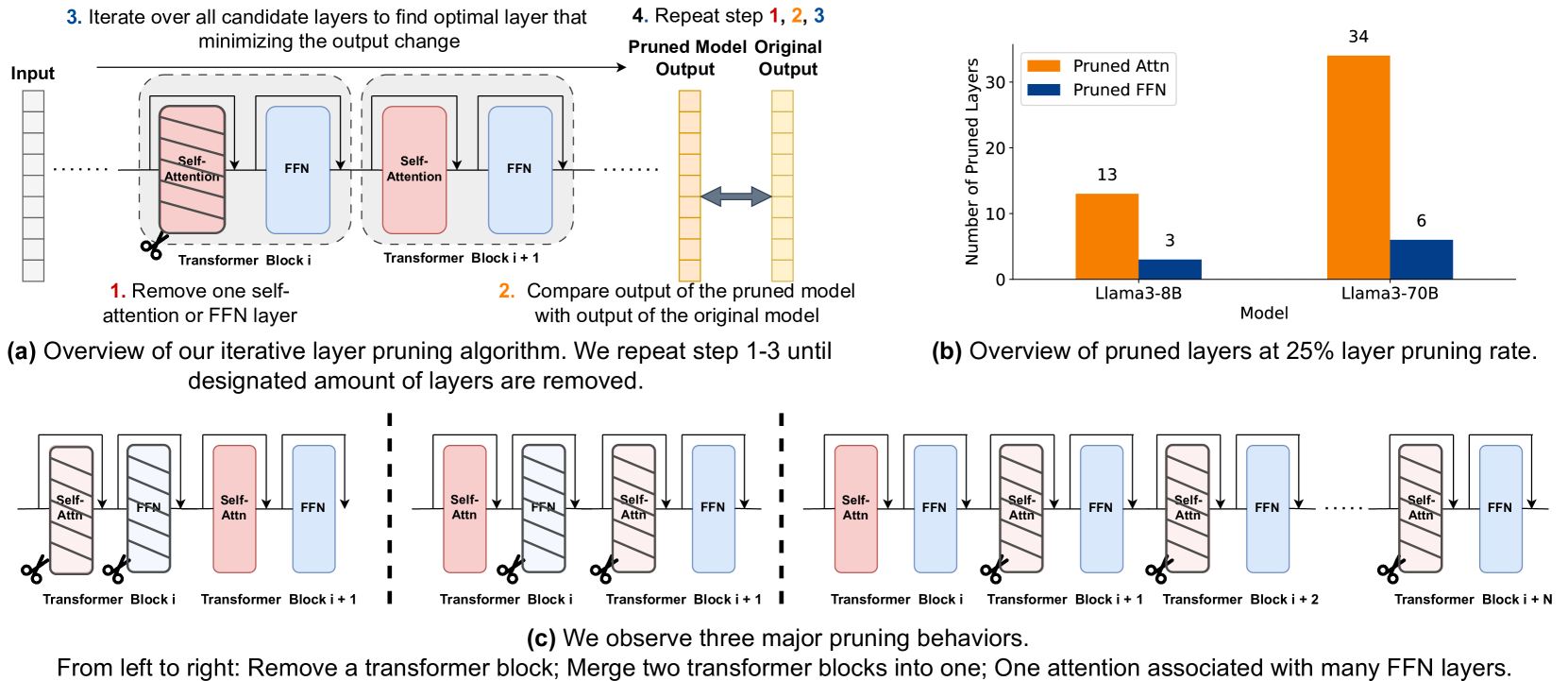
| FinerCut: Finer-grained Interpretable Layer Pruning for Large Language Models Yang Zhang, Yawei Li, Xinpeng Wang, Qianli Shen, Barbara Plank, Bernd Bischl, Mina Rezaei, Kenji Kawaguchi |
 |
Paper |
 SLoPe: Double-Pruned Sparse Plus Lazy Low-Rank Adapter Pretraining of LLMs Mohammad Mozaffari, Amir Yazdanbakhsh, Zhao Zhang, Maryam Mehri Dehnavi |
 |
Github Paper |
 SPP: Sparsity-Preserved Parameter-Efficient Fine-Tuning for Large Language Models Xudong Lu, Aojun Zhou, Yuhui Xu, Renrui Zhang, Peng Gao, Hongsheng Li |
 |
Github Paper |
| Quantization | ||
 Compressing Large Language Models using Low Rank and Low Precision Decomposition Rajarshi Saha, Naomi Sagan, Varun Srivastava, Andrea J. Goldsmith, Mert Pilanci |
 |
Github Paper |
| I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit Large Language Models Xing Hu, Yuan Chen, Dawei Yang, Sifan Zhou, Zhihang Yuan, Jiangyong Yu, Chen Xu |
 |
Paper |
 Exploiting LLM Quantization Kazuki Egashira, Mark Vero, Robin Staab, Jingxuan He, Martin Vechev |
 |
Github Paper |
| CLAQ: Pushing the Limits of Low-Bit Post-Training Quantization for LLMs Haoyu Wang, Bei Liu, Hang Shao, Bo Xiao, Ke Zeng, Guanglu Wan, Yanmin Qian |
 |
Paper |
| SpinQuant -- LLM quantization with learned rotations Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, Tijmen Blankevoort |
 |
Paper |
 SliM-LLM: Salience-Driven Mixed-Precision Quantization for Large Language Models Wei Huang, Haotong Qin, Yangdong Liu, Yawei Li, Xianglong Liu, Luca Benini, Michele Magno, Xiaojuan Qi |
 |
Github Paper |
 PV-Tuning: Beyond Straight-Through Estimation for Extreme LLM Compression Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik |
 |
Github Paper |
| Integer Scale: A Free Lunch for Faster Fine-grained Quantization of LLMs Qingyuan Li, Ran Meng, Yiduo Li, Bo Zhang, Yifan Lu, Yerui Sun, Lin Ma, Yuchen Xie |
 |
Paper |
| Inference Acceleration | ||
| Faster Cascades via Speculative Decoding Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Seungyeon Kim, Neha Gupta, Aditya Krishna Menon, Sanjiv Kumar |
 |
Paper |
 Hardware-Aware Parallel Prompt Decoding for Memory-Efficient Acceleration of LLM Inference Hao (Mark)Chen, Wayne Luk, Ka Fai Cedric Yiu, Rui Li, Konstantin Mishchenko, Stylianos I. Venieris, Hongxiang Fan |
 |
Github Paper |
| Efficient MOE | ||
MoNDE: Mixture of Near-Data Experts for Large-Scale Sparse Models Taehyun Kim, Kwanseok Choi, Youngmock Cho, Jaehoon Cho, Hyuk-Jae Lee, Jaewoong Sim |
 |
Paper |
 Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models Yongxin Guo, Zhenglin Cheng, Xiaoying Tang, Tao Lin |
 |
Github Paper |
A Provably Effective Method for Pruning Experts in Fine-tuned Sparse Mixture-of-Experts Mohammed Nowaz Rabbani Chowdhury, Meng Wang, Kaoutar El Maghraoui, Naigang Wang, Pin-Yu Chen, Christopher Carothers |
 |
Paper |
| KV Cache Compression | ||
| ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification Yefei He, Luoming Zhang, Weijia Wu, Jing Liu, Hong Zhou, Bohan Zhuang |
 |
Paper |
| Hardware/System | ||
Parrot: Efficient Serving of LLM-based Applications with Semantic Variable Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, Lili Qiu |
 |
Paper |
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.