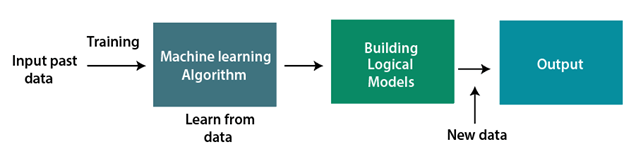
Machine learning is a growing technology that enables computers to learn automatically from past data.
Machine learning uses various algorithms for building mathematical models and making predictions using historical data or information.

This machine learning tutorial gives you an introduction to machine learning along with a wide range of machine learning techniques such as Supervised, Unsupervised, and Reinforcement learning.
Machine Learning is said as a subset of artificial intelligence that is mainly concerned with the development of algorithms that allow a computer to learn from the data and past experiences on its own.
The term machine learning was first introduced by Arthur Samuel in 1959.

A Machine Learning system learns from historical data, builds the prediction models, and whenever it receives new data, predicts the output for it. The accuracy of predicted output depends upon the amount of data, as the huge amount of data helps to build a better model which predicts the output more accurately.
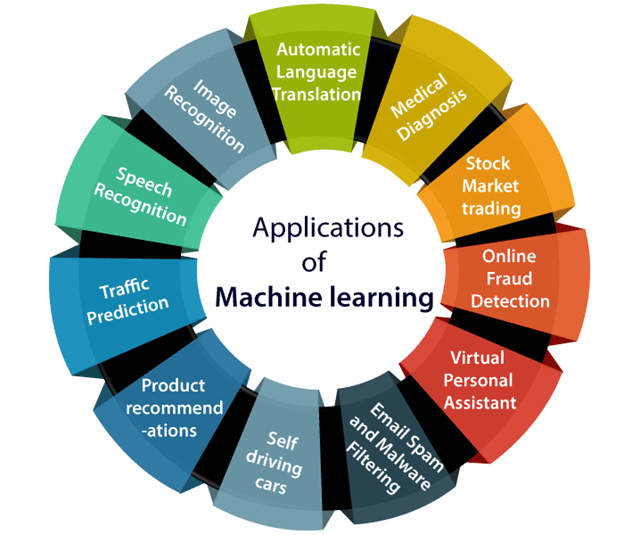
Below are some most trending real-world applications of Machine Learning:

- Identify various data sources
- Collect data
- Integrate the data obtained from different sources
- Data exploration
- Data pre-processing
Data wrangling is the process of cleaning and converting raw data into a useable format.
- Missing values
- Duplicate data
- Invalid data
- Noise
It starts with the determination of the type of the problems, where we select the machine learning techniques such as Classification, Regression, Cluster analysis, Association, etc. then build the model using prepared data, and evaluate the model.
- Selection of analytical techniques
- Building models
- Review the result
We train our model to improve its performance for better outcome of the problem.
We use datasets to train the model using various machine learning algorithms.
We check for the accuracy of our model by providing a test dataset to it.
Testing the model determines the percentage accuracy of the model as per the requirement of project or problem.
The key to success in the field of machine learning or to become a great data scientist is to practice with different types of datasets. But discovering a suitable dataset for each kind of machine learning project is a difficult task.
1.Types of data in datasets
- Numerical data:Such as price etc.
- Categorical data:Such as True/False,Yes/No, Red/yellow, etc.
- Ordinal data: These data are similar to categorical data but can be measured on the basis of comparison.
A tabular dataset can be understood as a database table or matrix, where each column corresponds to a particular variable, and each row corresponds to the fields of the dataset. The most supported file type for a tabular dataset is "Comma Separated File," or CSV. But to store a "tree-like data," we can use the JSON file more efficiently.
- Some popular sources for ML Datasets
- Google's Dataset Search Engine - https://toolbox.google.com/datasetsearch.
- UCI Machine Learning Repository - https://archive.ics.uci.edu/ml/index.php.
- Kaggle Datasets - https://www.kaggle.com/datasets.
- Datasets via AWS - https://registry.opendata.aws/.
- Microsoft Datasets - https://msropendata.com/.
- Awesome Public Dataset Collection - https://github.com/awesomedata/awesome-public-datasets.
- Scikit-learn dataset - https://scikit-learn.org/stable/datasets/index.html.
Data preprocessing is a process of preparing the raw data and making it suitable for a machine learning model. It is the first and crucial step while creating a machine learning model.
When creating a machine learning project, it is not always a case that we come across the clean and formatted data. And while doing any operation with data, it is mandatory to clean it and put in a formatted way.
Data preprocessing is required tasks for cleaning the data and making it suitable for a machine learning model which also increases the accuracy and efficiency of a machine learning model.
- Getting the dataset
- Importing libraries
- Importing datasets
- Finding Missing Data
- Encoding Categorical Data
- Splitting dataset into training and test set
- Feature scales