This repository contains a Jax implementation of conformal training corresponding to the follow paper:
David Stutz, Krishnamurthy Dj Dvijotham, Ali Taylan Cemgil, Arnaud Doucet. Learning optimal conformal classifiers. ICLR, 2022.
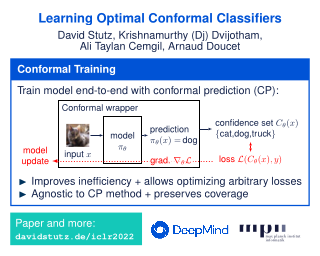
Conformal training allows training models explicitly for split conformal prediction (CP). Usually, split CP is used as a separate calibration step - a wrapper - after training with the goal to predict confidence sets of classes instead of making point predictions. The goal of CP is to associate these confidence sets with a so-called coverage guarantee, stating that the true class is included with high probability. However, applying CP after training prevents the underlying model from adapting to the prediction of confidence sets. Conformal training explicitly differentiates through the conformal predictor during training with the goal of training the model with the conformal predictor end-to-end. Specifically, it "simulates" conformalization on mini-batches during training. Compared to standard training, conformal training reduces the average confidence set size (inefficiency) of conformal predictors applied after training. Moreover, it can "shape" the confidence sets predicted at test time, which is difficult for standard CP. We refer to the paper for more background on conformal prediction and a detailed description of conformal training.
The code included in this repository reproduces the majority of the experiments included in the paper.
All dependencies, including versions this repository has been tested with,
can be found in environment.yml, ready to be used with Conda. Find
detailed instructions below:
-
Install Conda following the official instructions. Make sure to restart bash after installation.
-
Clone this repository using
$ git clone https://github.com/deepmind/git $ cd conformal_training -
Create a new Conda environment from
environment.ymland activate it (the environment can be deactivated any time usingconda deactivate):$ conda env create -f environment.yml $ conda activate conformal_training -
Check if the code runs by running all tests:
$ chmod +x test.sh $ ./test.sh
These instructions have been tested with Conda version 4.12 (not miniconda)
on a 64-bit Linux workstation. We recommend to make sure that no conflicting
pyenv environments are activated or PATH is explicitly set or changed in
the used bash profile. After activating the Conda environment, the corresponding
Python binary should be first in PATH. If that is not the case (e.g.,
PATH lists a local Python installation in ~/.local/ first), this can
cause problems.
All of this repository's components can be used in a standalone fashion.
This will likely be most interesting regarding the (smooth) conformal prediction
implementations in conformal_prediction.py and
smooth_conformal_prediction.py (corresponding to Sections 2.1 and 2.2)
as well as the variational sorting network for differentiable sorting in
variational_sorting_net. Conformal training is implemented in
train_conformal.py (Section 3), the coverage
training baseline in train_coverage.py (Section E) and normal cross-entropy
training in train_normal.py.
This section focuses on reproducing some of the paper's experiments. For simplicity, we will not consider running multiple training trials (see Section F).
The experiment definitions for all datasets can be found in experiments/
and are started through run.py. For example,
$ python3 run.py \
--experiment_dataset=mnist \
--experiment_experiment=models \
--experiment_seeds=1 \
--experiment_path=~/experiments/
trains a baseline model on MNIST. The supported experiment names for
--experiment_experiment can be found in experiments/run_mnist.py.
$ python3 run.py \
--experiment_dataset=mnist \
--experiment_experiment=conformal.training \
--experiment_seeds=1 \
--experiment_path=~/experiments/
runs conformal training on MNIST. In both cases, --experiment_seeds can be
used to run multiple training trials as done in the paper.
Checkpoints and predictions are stored in --experiment_path using pickle
files. Both experiments can be evaluated using
$ python eval.py \
--experiment_path=~/experiments/mnist_models_seed0/ \
--experiment_method=thr \
--experiment_dataset=mnist
# ...
Trial 0: 0.008522
Trial 1: 0.010164
# ...
Accuracy: 0.923990
Coverage: 0.990830
Size: 2.238840
Class size 0: 1.552605
Class size 1: 1.887313
Class size 2: 2.066631
Class size 3: 2.293224
Class size 4: 2.189819
Class size 5: 2.742948
Class size 6: 1.852211
Class size 7: 2.015539
Class size 8: 2.917412
Class size 9: 2.952475
Group groups size 0: 2.116852
Group groups size 1: 2.356661
Group groups miscoverage 0: 0.421632
Group groups miscoverage 1: 0.474612
and
$ python eval.py \
--experiment_path=~/experiments/mnist_conformal.training_seed0/ \
--experiment_method=thr \
--experiment_dataset=mnist
# ...
Accuracy: 0.903780
Coverage: 0.990230
Size: 2.147300
# ...
Here, --experiment_method=aps will use adaptive prediction sets (APS) as
conformal predictor instead of the default threshold conformal predictor
- see Section 2.1 in the paper. The output of
eval.pywill look as shown above where size denotes inefficiency and confidence level is fixed at0.01. Here, group size corresponds to odd vs. even on MNIST or vehicles vs. animals on CIFAR, see paper, and class size corresponds to the inefficiency of the individual classes.
On CIFAR, conformal training is to started from scratch. Instead, a backbone is fine-tuned. On CIFAR10, use
$ python3 run.py \
--experiment_dataset=cifar10 \
--experiment_experiment=models \
--experiment_seeds=1 \
--experiment_path=~/experiments/
$ python3 run.py \
--experiment_dataset=cifar10 \
--experiment_experiment=baseline \
--experiment_seeds=1 \
--experiment_path=~/experiments/
$ python3 run.py \
--experiment_dataset=cifar10 \
--experiment_experiment=conformal.training \
--experiment_seeds=1 \
--experiment_path=~/experiments/
Evaluation can be done as on MNIST, see above.
This table provides an overview over all experiments included in this repository. Note that the paper runs 10 training trials and reports averages, while the above commands only run 1 training trial for simplicity. This will result in slightly different results.
| Dataset | Experiment | Description |
|---|---|---|
| MNIST | models |
Baseline with cross-entropy training. |
| MNIST | conformal.training |
Conformal training. |
| MNIST | conformal.group_zero/one |
Conformal training to reduce group mis-coverage. |
| MNIST | conformal.singleton_zero/one |
Conformal training to reduce mis-coverage between a singleton and all other classes. |
| MNIST | conformal.group_size_0/1 |
Conformal training to reduce inefficiency of a group. |
| MNIST | conformal.class_size_0-9 |
Conformal training to reduce inefficiency per class. |
| EMNIST | models |
Baseline with cross-entropy training. |
| EMNIST | conformal |
Conformal training. |
| Fashion-MNIST | models |
Baseline with cross-entropy training. |
| Fashion-MNIST | conformal.training |
Conformal training. |
| Fashion-MNIST | conformal.confusion_4_6 |
Conformal training to reduce coverage confusion between classes 4 and 6. |
| Fashion-MNIST | conformal.confusion_2_4_6 |
Conformal training to reduce coverage confusion between classes 2, 4, and 6. |
| Fashion-MNIST | conformal.confusion_6 |
Conformal training to reduce coverage confusion between 6 and all other classes. |
| WineQuality | models |
Baseline with cross-entropy training. |
| WineQuality | conformal.training |
Conformal training. |
| WineQuality | conformal.importance_0/1 |
Conformal training to increase importance of class 0/1. |
| WineQuality | conformal.confusion_0/1_1/0 |
Conformal training to reduce confusion between classes 0/1 and 1/0. |
| CIFAR10 | models |
Backbone. |
| CIFAR10 | baseline |
Cross-entropy training on backbone. |
| CIFAR10 | conformal.training |
Conformal training on backbone. |
| CIFAR10 | conformal.group_zero/one |
Conformal training to reduce group mis-coverage. |
| CIFAR10 | conformal.singleton_zero/one |
Conformal training to reduce mis-coverage between a singleton and all other classes. |
| CIFAR10 | conformal.group_size_0/1 |
Conformal training to reduce inefficiency of a group. |
| CIFAR10 | conformal.class_size_0-9 |
Conformal training to reduce inefficiency per class. |
| CIFAR10 | models |
Backbone. |
| CIFAR10 | baseline |
Cross-entropy training on backbone. |
| CIFAR10 | conformal.training |
Conformal training on backbone. |
| CIFAR10 | conformal.group_zero/one |
Conformal training to reduce group mis-coverage. |
| CIFAR10 | conformal.hierarchy_size0-19 |
Conformal training to reduce size of coarse classes 0-19. |
Implementations of smooth conformal predictors can be found in
smooth_conformal_prediction.py. The tests provided in
smooth_conformal_prediction_test.py can be referred to as usage examples.
Conformal training is implemented in train_conformal.py but heavily depends
on coverage training as implemented in train_coverage.py. The essential
parts, which are also listed in Section P in the paper, are
compute_loss_and_error_with_calibration in train_conformal.py
which runs smooth calibration and prediction and calculates the
inefficiency and/or classification loss. The smooth calibration and prediction
functions are set up in select_smooth_calibrate and select_smooth_predict,
the latter is inherited from train_coverage.py. All necessary configuration
parameters are included in config.py with some explanations in the comments.
When using any part of this repository, make sure to cite the paper as follows:
@inproceedings{StutzICLR2022
title={Learning Optimal Conformal Classifiers},
author={David Stutz and Krishnamurthy Dj Dvijotham and Ali Taylan Cemgil and Arnaud Doucet},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=t8O-4LKFVx}
}
Copyright 2022 DeepMind Technologies Limited
All software is licensed under the Apache License, Version 2.0 (Apache 2.0); you may not use this file except in compliance with the Apache 2.0 license. You may obtain a copy of the Apache 2.0 license at: https://www.apache.org/licenses/LICENSE-2.0
All other materials are licensed under the Creative Commons Attribution 4.0 International License (CC-BY). You may obtain a copy of the CC-BY license at: https://creativecommons.org/licenses/by/4.0/legalcode
Unless required by applicable law or agreed to in writing, all software and materials distributed here under the Apache 2.0 or CC-BY licenses are distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the licenses for the specific language governing permissions and limitations under those licenses.
This is not an official Google product.