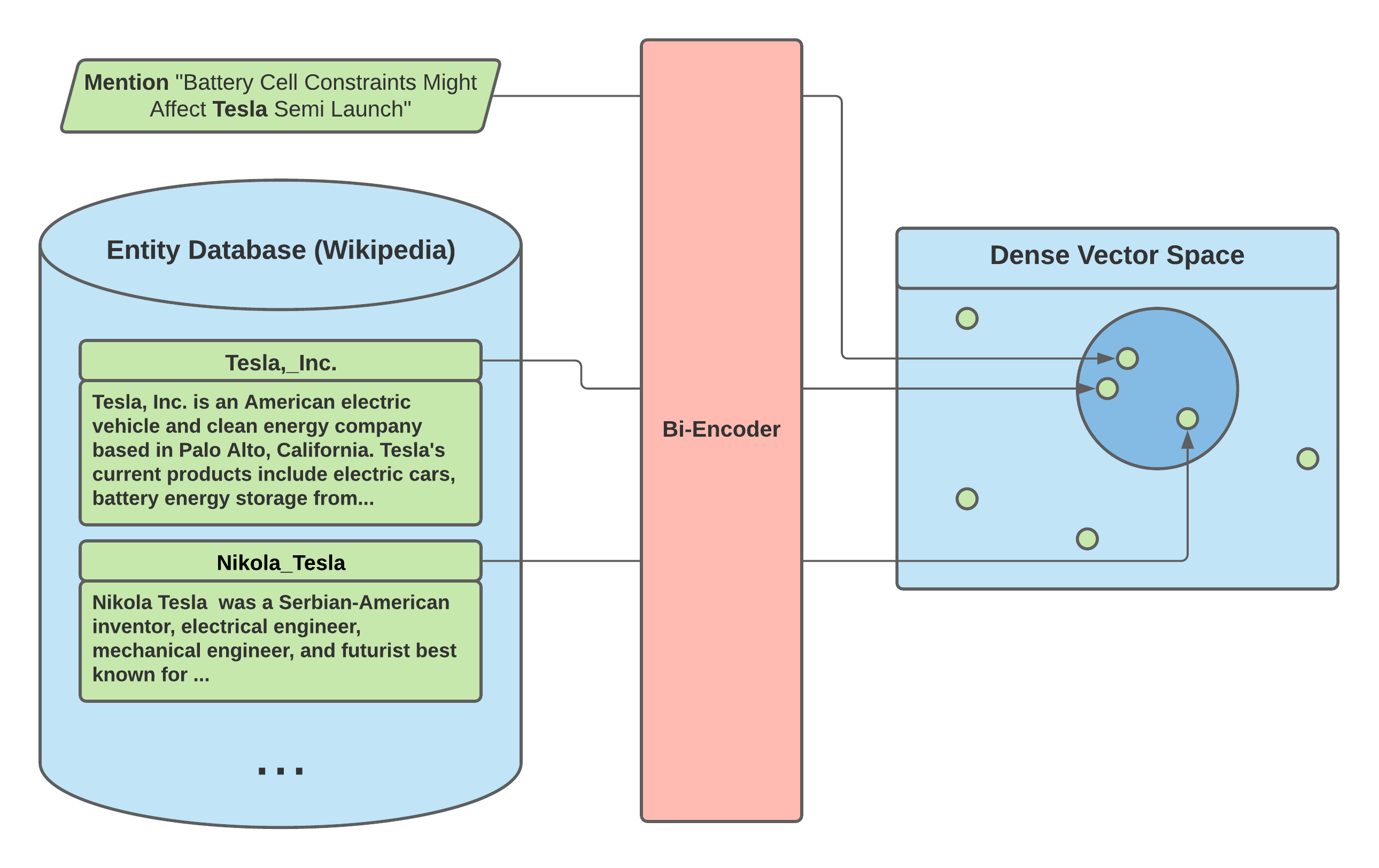
This repo implements a bi-encoder model for entity linking. The bi-encoder separately embeds mention and entity
pairs into a shared vector space. The encoders in the bi-encoder model are pretrained transformers.
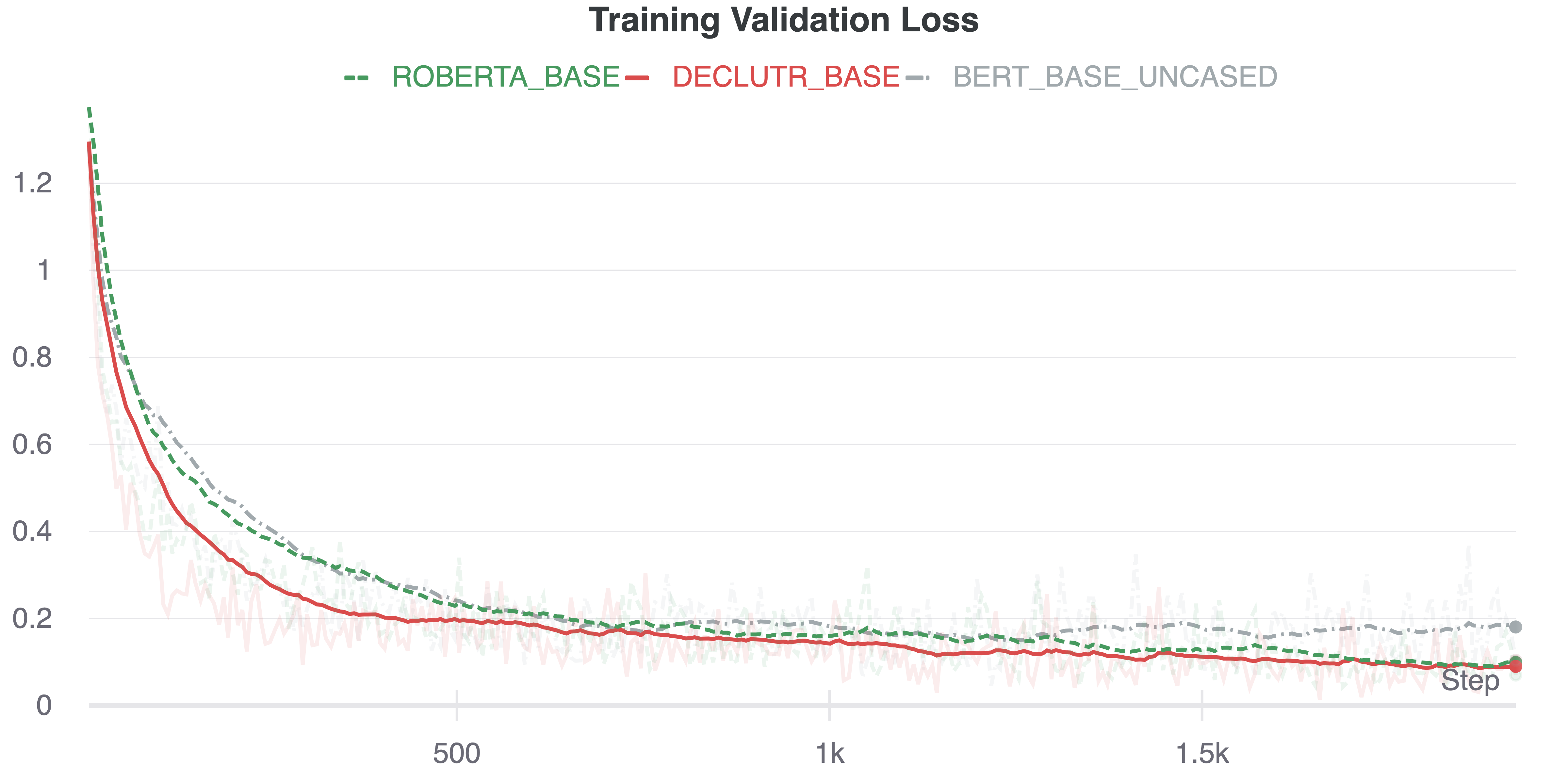
We evaluate three different base encoder models on the retrieval rate metric.
The retrieval rate is the rate at which the correct entity for a mention is included when generating
k candidates for each mention in the test set.
The HuggingFace names of the three
base encoder models are:
bert-base-uncasedroberta-basejohngiorgi/declutr-base
The ML models in this repo are implemented using PyTorch and PyTorch-Lightning.
- Install Miniconda
- Run
conda env create -f environment.ymlfrom inside the extracted directory. This creates a Conda environment calledenli - Run
source activate enli - Install requirements.
pip install -r requirements.txt
We use the Zeshel (zero-shot-entity-linking) dataset for training and evaluation. The Zeshel train/dev/test splits are completely non-overlapping and have the following numbers:
- Train: 49275 labeled mentions covering 31502 entities
- Val: 10000 labeled mentions covering 7513 entities
- Test: 10000 labeled mentions covering 7218 entities
The train, val, and test sets do not share any entities at all between them.
Download the training data from here.
Copy the downloaded file into the root folder of this repo and then run
tar -xvf zeshel.tar.bz2
This step will require at least 20gb of memory.
python -m src.transform_zeshel --input-dir="./zeshel"To train on Google Cloud Platform (GCP), you must first build and push the training and
evaluation docker image
to your google cloud project. To do this edit scripts/build-images.sh with your own info.
Next, you can edit scripts/train-gcp.sh with your own
google cloud project and then run
./scripts/train-gcp.shto submit a training job.
Similarly, edit scripts/eval-gcp.sh with your google cloud project id and run
./scripts/eval-gcp.shto submit the eval job.
We find the using DeCLUTR embedding model (which is based on roberta) significantly outperforms
both roberta-base and bert-base-uncased on the entity linking task. With DeCLUTR
we achieved a retrieval-rate at k=64 of ~69%. Note that this score
is measured on a test set of completely unseen entities.
The validation loss curves and retrieval rates for the three base model types are shown below.