{kind=link}
This is proof of concept I wrote when I was at college/uni using OpenMPI to parallelize some computation on a 2-d array in C. The library is availabe at: https://www.open-mpi.org/
Basically, this is an array relaxation process that computes an average values based on surrounding neighbour values until a set precision is reached. Suprisingly, the problem and the way I split the load is very close to what is described here: https://blogs.msdn.microsoft.com/visualizeparallel/2010/03/29/the-jacobi-relaxation-an-instance-of-data-parallelism/
The array is initially setup at the root processor (with rank = 0) and the rows of the array is given to the set number of processors. Array rows are scatter in such a way that a processor can work in isolation without needing to talk to other processors during its average value calculation process. Once every processors finish working on their arrays, processors will send and request new rows to and from other processor that might affect their next calculation. This process is repeated until the precision has been met. Finally, the new rows are gathered back the main array in the root processor. Of course, this is one way. The other way could have been done by load balancing in a different way and rather than gathering at the ROOT process each time to check for precision, do this directly and repeatedly by the slave processes themselves when computation are done and only gather at ROOT when finished. But the reason why this is done is precisely the point of making a proof of concept as it is much easier to see the usefulness and functions provided by OpenMPI.
When running the program with mpirun I have also added further two arguments to specify the dimension of the array and the precision to work on. For compiling using OpenMPI wrapper for C, please refer to the documentation here: https://www.open-mpi.org/faq/?category=mpi-apps
Example: mpirun -np 5 ./executable 16 0.04 The first argument after the executable program name will be the dimension and the second will the precision.
NOTE: This is a PROOF OF CONCEPT for demonstration, not an absolute state of the art implementation of the problem. This is just show how OpenMPI can be used. For more info, seek.
Examples
Setup
This depends on the cluster structure and processors of course, and more importantly the overhead between the cluster processors' communication. I was fortunate to use one of the massive university cluster for this test.The initial value of these 2-d dimension does not reallly matter. The following initial constant value were used throughout.
Using precision: 0.002 Dimension: 5000
Overiew of the speedup:
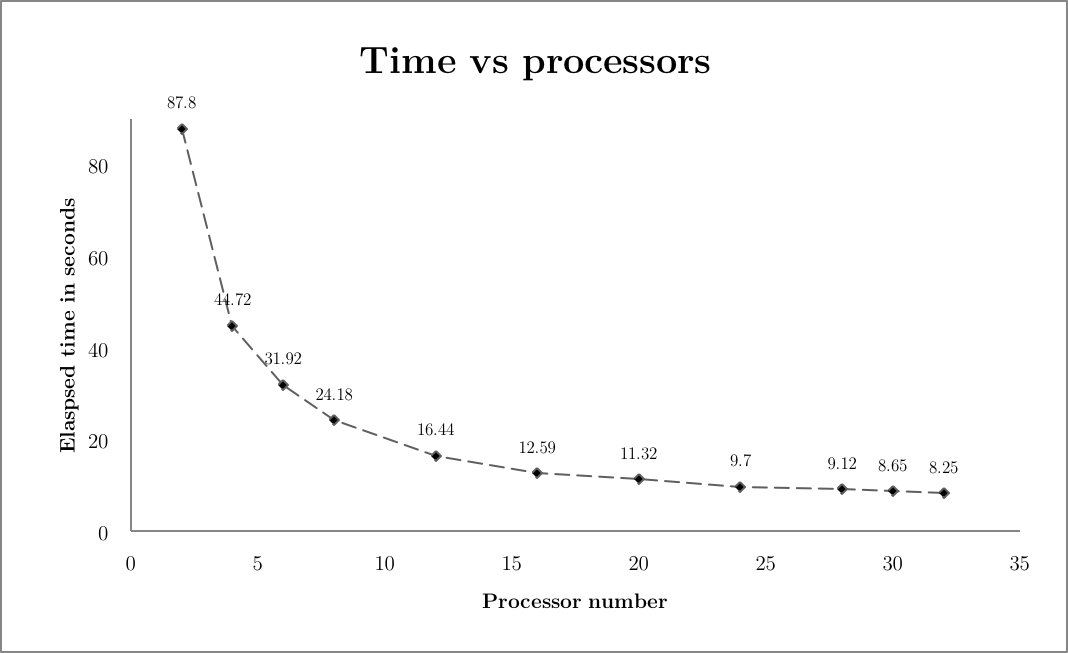
The time unit was probabbly in seconds but I don't quite remember.