Free hands-on course with the implementation (in Python) and description of several Natural Language Processing (NLP) algorithms and techniques, on several modern platforms and libraries.
Although it is not intended to have the formal rigor of a book, we tried to be as faithful as possible to the original algorithms and methods, only adding variants, when these were necessary for didactic purposes.
The best way to get the most out of this course is to carefully read each selected problem, try to think of a possible solution (language independent) and then look at the proposed Python code and try to reproduce it in your favorite IDE. If you already have knowledge of the Python language, then you can go directly to programming your solution and then compare it with the one proposed in the course.
If you want to play with these notebooks online without having to install any library or configure hardware, you can use the following service:
Natural Language Processing project with Python frameworks. NLP is a discipline where computer science, artificial intelligence and cognitive logic are intercepted, with the objective that machines can read and understand our language for decision making.
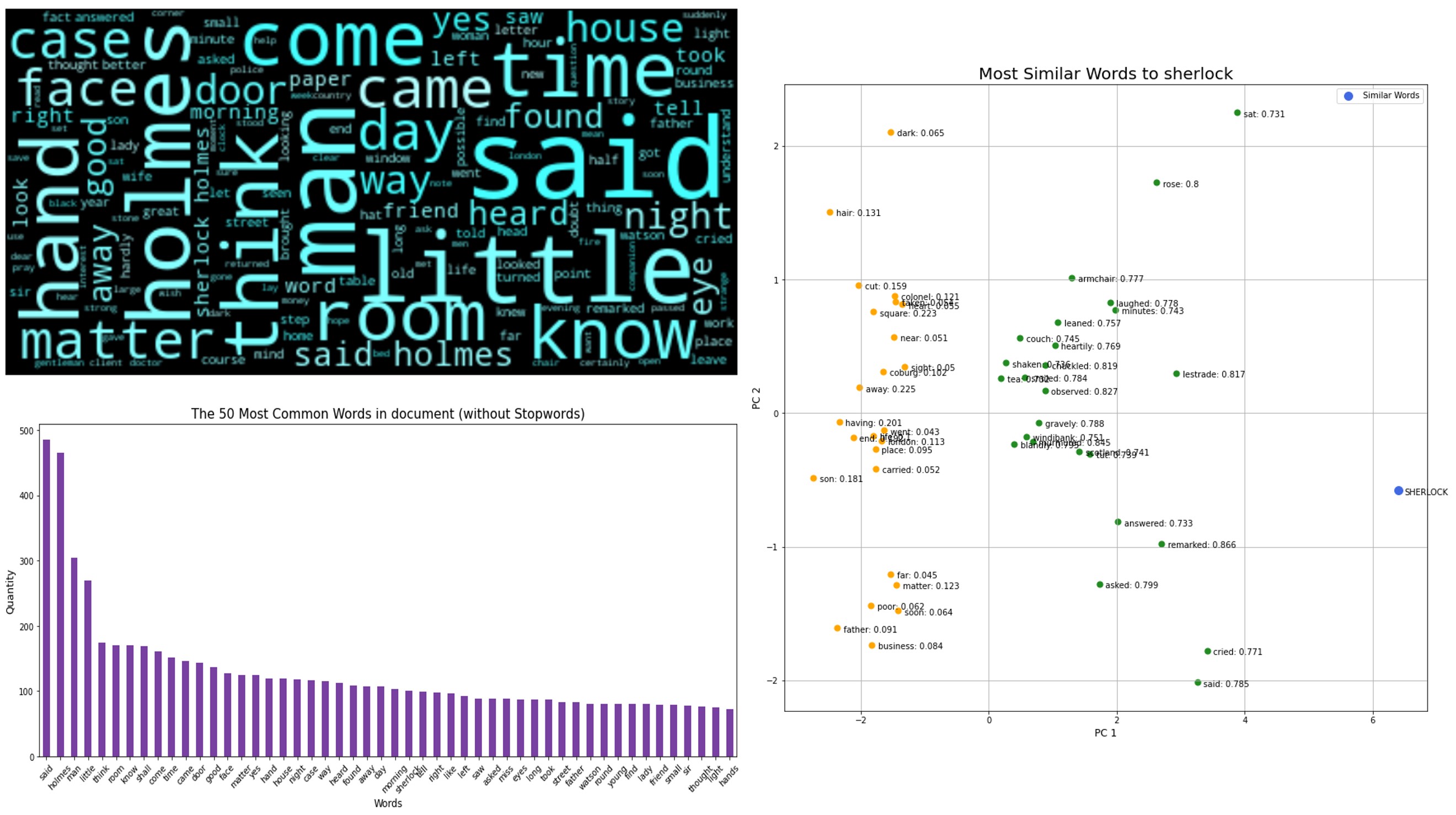
1. NLP with spaCy
- Read natural text of a book in Spanish
- Create a NLP model with spaCy
- Working with POS, NER and sentences
2. Semantic Enrichment of Entities
- Semantic enrichment
- SPARQL
- DBpedia
3. Spell Checker/Corrector
- Spell Checker from scratch
- Spell Checker using PySpellChecker class
4. Word Embedding with Gensim
- Read natural text of a book in English
- Tokenize and remove stopwords
- Create a Word2Vec model (CBOW)
- Plot similars words
- Export similarity between the words
5. Relationship between Words
- Networks and force system
- d3.js
6. Introduction to Stanza (Stanford CoreNLP)
- Stanza text processing
- Stanford CoreNLP interface
Books in plain text, both in English and Spanish. The enrichment of the entities is done from DBpedia.
conda install -c conda-forge spacy
python -m spacy download en_core_web_sm
python -m spacy download es_core_news_sm
conda install -c conda-forge sparqlwrapper
pip install pyspellchecker
conda install -c anaconda gensim
conda install -c conda-forge wordcloud
conda install -c conda-forge stanza- Python 3.8.5
- spaCy 3.0.5
- Gensim 4.0.1
- Stanza 1.2.3
Any kind of feedback/suggestions would be greatly appreciated (algorithm design, documentation, improvement ideas, spelling mistakes, etc...). If you want to make a contribution to the course you can do it through a PR.
Please read the contributing and code of conduct documentation.
- Created by Andrés Segura Tinoco
- Created on June 04, 2019
This project is licensed under the terms of the MIT license.
I would like to thank Project Gutenberg for sharing the books in English and Peter Norvig for the spell checker algorithm.