A special data storage to meet the requirements of a project from LTU PERCCOM Masters program.
SDSi is a special kind of storage where members are in cluster system. SEARCH and STORE can be performed in this storage from any members of the cluster. Cluster is formed using Hazelcast. Auto discovery of the member is configured in private network. Any machine in the network running the application will join the cluster automatically and be a part of storage system. Settings parameter can be changed from any member and it will persist in every member of the cluster.
Criteria to STORE:
The entire peer-to-peer system will maintain a pool of addresses for storage locations.
The number of storage locations across the system is large.
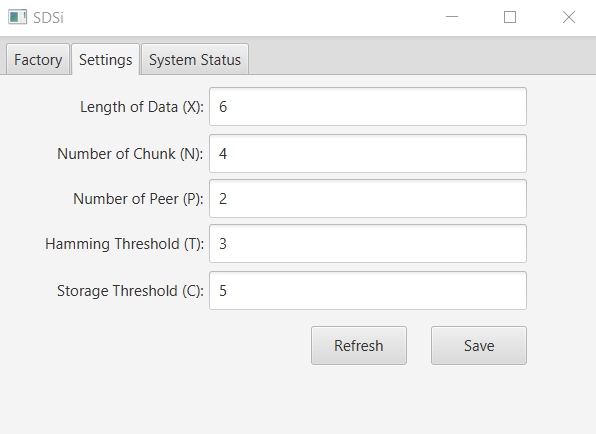
This global number of storage locations (denoted as S=PN) is a configurable parameter via P and N.
Each storage location is X bins in size and is addressed by an X bits address, where X is the size of the data chunk. The addresses are X-bit binary sequences, which are RANDOMLY generated during the peer’s initialization time and remain stable during the peer’s lifetime, i.e. each peer has an NxX matrix for addressing purposes. The initialization time all storage locations are empty.
The Data will be stored based on the principles of proximity/similarity between the Data chunk and the address. The proximity metric is Hamming distance (the number of bit positions in which two sequences disagree). The threshold T (in number of different bits) is a configurable parameter of the system.
The incoming Data is stored only in these storage locations for which Hamming distance between Data and the location’s address is less or equal T. Thus, Data is stored in many (in the order of tens of thousand) locations on different peers. This implies that the storage request will be propagated through the network and potentially stored in many peers.
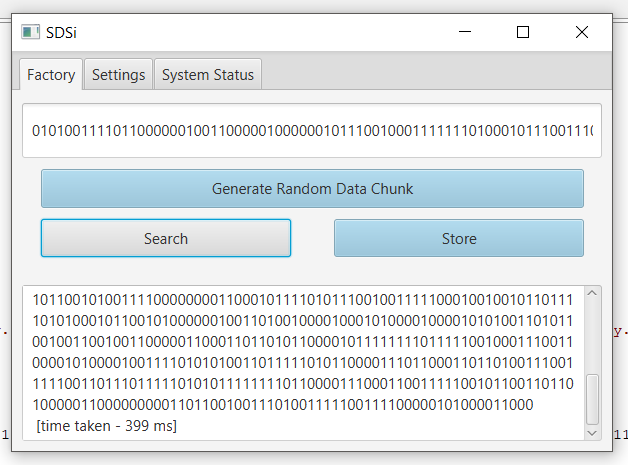
The data will be stored in a somewhat unconventional way. It will be POSITIONWISE added to the content of all identified storage locations. It is probably wise to use byte array of size X for implementing each storage position. Thus, as you can see each storage location will potentially contain a superposition of many stored Data chunks.
Criteria to SEARCH: Query to the system is a Data chunk of size X bits, which is similar to one of the stored Data chunks. The proximity is again measured by Hamming distance.
The query can be generated at any peer and the network should cooperatively find the best matching stored Data. To do this the querying peer will perform several iterations monitoring Hamming distance between the response of the iteration i-1 and the current iteration. The distance will either converge to 0 or diverge to X/2. This is search TERMINATION criteria.
On each iteration the query is broadcasted to all peers. Each peer selects the content of all matching storage locations if any (i.e., Hamming distance between the query and an address is less or equal T), performs a position-wise summation (no thresholding at this step) and sends the result to the requesting peer. Since more than one peer can contain the matching record, several responses can arrive to the requesting peer. These several responses will be treated according to the following procedure: 1. all individual responses will be summed position-wise 2. the resultant sum will be binarized: all positive positions including 0 will become 1 and all negative positions will become 0 This binarized data chunk will be the RESPONSE for a single iteration.
The RESULT of the query is either the binarized Data chunk from the latest iteration if the search procedure has converged or an error code if the procedure has diverged (see the TERMINATION criteria above).
Java 8 (or higher)
Hazelcast
Maven
Application will boot up with default settings with parameters read from app.properties file. Settings can be re-configured runtime.
All the member wants to join the cluster should be in same private network and run the application with following command. Application will boot with a GUI and it the machine will join the cluster with existing cluster configuration.
java -jar sdsi.jar
- Maven - Dependency Management
- Anisul Islam - Anis
- Anastasiiaa Grishina
- Sami Kabir
- Ijlal Niazi
See also the list of contributors who participated in this project.
This project is licensed under the MIT License - see the LICENSE.md file for details
- Prof. Evgeny Osipov
- Towfiqu Imam Mithu - My former Development Manager to whom I'm ever grateful to teach me proper coding.