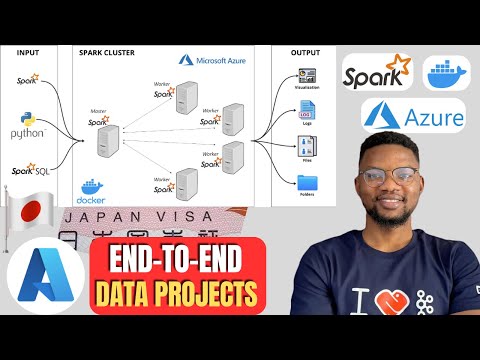
This project provides an end-to-end data processing and visualization of visa numbers in Japan using PySpark and Plotly. The spark clusters are set up within a Docker container on Azure.

- Azure Account: Ensure you have an active Azure account.
- Docker: The Spark master-worker architecture is set up in a Docker container on Azure.
- Python Libraries: Install the required Python libraries:
- PySpark
- Plotly Express
- pycountry
- pycountry_convert
- fuzzywuzzy
- Data Input: Place your CSV file named
visa_number_in_japan.csvin theinputdirectory. - Run the Script: Execute the provided Python script.
- Visualizations: After execution, you'll find the visualizations saved as HTML files in the
outputdirectory. - Cleaned Data: The cleaned data will also be saved as a CSV file in the
outputdirectory.
- System Architecture: The Spark master-worker architecture is set up in a Docker container on Azure.
- Data Ingestion: The script ingests the CSV file containing the visa numbers in Japan.
- Data Cleaning: The script standardizes column names, drops null columns, and corrects country names using fuzzy matching.
- Data Transformation: The data is further enriched by adding continent information for each country.
- Data Visualization: The cleaned and transformed data is visualized using Plotly Express to provide insights into visa trends in Japan.
- Ensure that your Azure and Docker setups are correctly configured to allow the Spark master-worker architecture to function seamlessly.
- The country name corrections and continent mapping are based on the
pycountryandpycountry_convertlibraries. Ensure that these libraries are up-to-date to get accurate results. - You can adjust the manual mappings in the
country_mappingdictionary in themain.pyfile to correct any country names that are not correctly matched.