Web Requests is a versatile plugin for ChatGPT Plus subscribers that allows users to access and parse content from the web, overcoming the "September 2021 Knowledge Cutoff." The plugin is built as an API service layer backend using the Quart server and is accessible via the provided OpenAPI specification, specifically optimized for ChatGPT's Plugins model. (GPT built it 🤖)
- Features
- Web Requests Pro
- Installation
- Scrape URL Endpoint
- Cache Management
- Pagination
- Input Validation
- Content Handling
- Command Line Interface
- OpenAPI Specification
- Best Practices and Usage
- Licensing
- Scrape URLs and Extract Content: Retrieve data from any accessible website.
- Perform Google Searches: Get search results directly in your ChatGPT conversation.
- Follow Links: Navigate through search results and extract additional content.
- Cache Management: Reduce server load and improve response times with intelligent caching.
- Pagination: Easily navigate through large sets of data.
- Input Validation: Ensure the integrity and safety of your requests.
- Content Handling: Process various types of content, including HTML, XML, JSON, CSV, PDF, and images.
- User-Friendly Command Line Interface: Interact with the plugin through a simple and intuitive CLI.
- Image Generation: Turn your text prompts into visual art, perfect for blog headers, game assets, or just for fun.
- Playground: A sandbox environment for coding, game development, and art creation.

For a subscription fee of $8.88/month, Web Requests Pro offers the following premium features:
- Unlimited Web Requests: No more limitations on the number of web requests you can make.
- Unlimited Playground Sessions: Create as many playgrounds as you like for coding, game development, and more.
- Priority Search Engine Requests: Get faster and more reliable search results.
- 100 Image Generations per Month: Generate up to 100 images per month to bring your creative ideas to life.
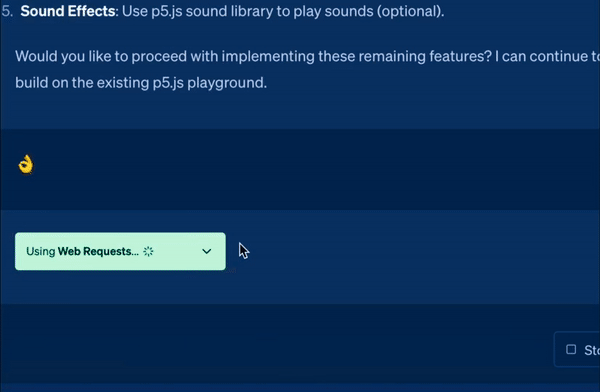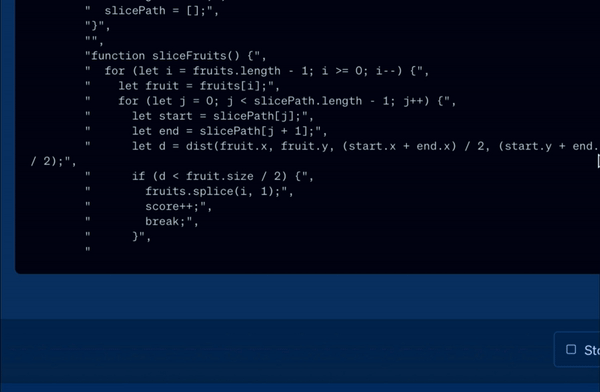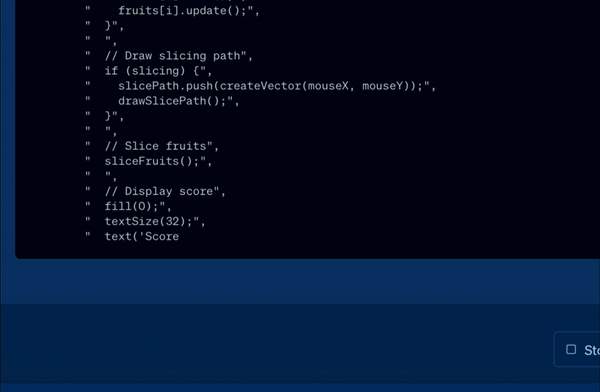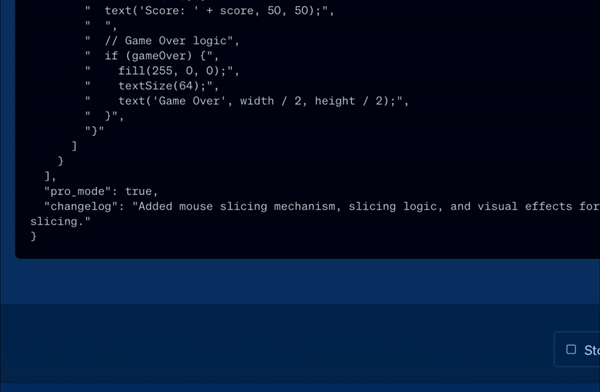
- Pro Mode in Playground: Access advanced features in the Playground, including customizable autonomous AI agents.
- WeGPT.ai Early Access: Get early access to collaborative ChatGPT features.
- Video Generation and Editing: Create and edit videos right within your ChatGPT conversation.
- AI Writing Assistant: Enhance your writing with AI-powered suggestions and corrections.
- AI Image Editing: Edit images using advanced AI algorithms.
To install and run the plugin, you need to have Python 3.7 or higher installed on your system. The plugin uses the following libraries:
- Quart
- httpx
- BeautifulSoup
- aiofiles
- htmlmin
- defusedxml
- pdfminer
- PIL (Pillow)
- aioconsole
- hypercorn
- googlesearch-python
- markdownify
Install the required libraries using the following command:
pip install quart httpx beautifulsoup4 aiofiles htmlmin defusedxml pdfminer.six pillow aioconsole hypercorn googlesearch-python markdownifyThen, set the required environment variables in a .env file:
OPENAI_API_KEY=<your_openai_api_key>
Finally, run the plugin using the following command:
python web_requests.pyEndpoint: /scrape_url
Method: POST
Description: Scrape a URL or perform a Google search and return the content. The content types supported include HTML, PDF, JSON, XML, CSV, and images.
Input Parameters:
-
url(string, required): The URL to scrape or the search query to perform ifis_searchis set to true. -
page(integer, optional, default: 1): The page number for pagination, based on the chosenpage_size. -
page_size(integer, optional, default: 10000): The maximum number of characters per page (chunk) for pagination. -
is_search(boolean, optional, default: false): Set totrueif the input is a search query instead of a URL. -
follow_links(boolean, optional, default: false): Set totrueto follow links in search results and extract content. -
num_results_to_scrape(integer, optional, default: 3): The number of search results to return ifis_searchis true. -
job_id(string, optional): A unique identifier for the request. If not provided, a UUID will be generated. -
refresh_cache(boolean, optional, default: false): Set totrueto force a cache refresh for the request. -
no_strip(boolean, optional, default: false): Set totrueto disable content minification.
Output:
success(boolean): Indicates whether the request was successful.content(object): The extracted content in various formats, including HTML, XML, JSON, CSV, PDF, images, and plain text.error(string): An error message, if any.has_more(boolean): Indicates whether there is more content available for pagination.job_id(string): The unique identifier for the request.cache_age(integer): The age of the cache in seconds.page_context(string): The current page context in the formatcurrent_page/total_pages.notice(string): A system message providing additional context that may help instruct and inform subsequent actions.
Example Request:
{
"url": "OpenAI",
"is_search": true,
"follow_links": false,
"num_results_to_scrape": 5
}Example Response:
{
"success": true,
"content": {
"search_results": [
{
"title": "OpenAI",
"link": "https://openai.com/",
"description": "OpenAI is an artificial intelligence research laboratory consisting of the for-profit corporation OpenAI LP and its parent company, the non-profit OpenAI Inc."
},
{
"title": "OpenAI - Wikipedia",
"link": "https://en.wikipedia.org/wiki/OpenAI",
"description": "OpenAI is an artificial intelligence (AI) research laboratory consisting of the for-profit corporation OpenAI LP and its parent company, the non-profit OpenAI Inc."
},
{
"title": "GitHub - openai",
"link": "https://github.com/openai",
"description": "GitHub is where people build software. More than 73 million people use GitHub to discover, fork, and contribute to over 200 million projects."
},
{
"title": "OpenAI - Home | Facebook",
"link": "https://www.facebook.com/openai",
"description": "OpenAI, San Francisco, California. 50,772 likes · 1,445 talking about this. We're conducting research to ensure that artificial general intelligence (AGI) benefits all of humanity. We're... "
},
{
"title": "OpenAI - Crunchbase Company Profile & Funding",
"link": "https://www.crunchbase.com/organization/openai",
"description": "OpenAI is an artificial intelligence research organization that aims to promote and develop friendly AI that benefits humanity as a whole."
}
]
},
"has_more": false,
"job_id": "987654",
"cache_age": 120,
"page_context": "1/1",
"notice": ""
}The plugin uses an in-memory cache to store request results and improve response times. The cache is cleaned every 2 minutes, removing items older than 15 minutes. The cache size is limited to 200 items.
The plugin supports pagination to handle large amounts of data. The page and page_size input parameters control the pagination behavior. The default values are 1 and 10000, respectively.
The plugin validates input parameters to ensure they are valid and within acceptable ranges. The validate_input function checks the input parameters and returns a boolean value indicating whether the input is valid, along with an error message if the input is invalid.
The plugin can handle various content types, including HTML, XML, JSON, CSV, PDF, and images. It also supports images and text-based files. The strip_html function is used to process HTML content, while other content types are handled by their respective functions.
For images, the plugin returns metadata such as format, size, mode, and image URL. For text-based files, the plugin performs transformations to improve readability.
The plugin provides a user-friendly command line interface that allows you to interact with the server and perform various tasks. The available commands are:
stats: Display server statistics, such as requests per hour, cache stats, and ephemeral user requests.purge cache: Clear the cache.restart: Restart the server.quit: Shut down the server.
To use the command line interface, simply type the desired command and press Enter.
The Web Requests plugin is accessible through an OpenAPI 3.0.0 specification, which provides a clear and concise way to describe the API service and its available endpoints. This allows developers to understand and interact with the API more effectively. You can find the OpenAPI specification for the Web Requests plugin here.
-
Caching: To reduce server load and improve response times, the plugin caches request results for 15 minutes. When paginating through large content, use the same
job_idto retrieve content from the cached snapshot of the original request. -
Pagination: When dealing with large volumes of data, use the
pageandpage_sizeparameters to paginate through the content. Be consistent with thepage_sizevalue when paginating a specific job to ensure accurate page context. -
Input validation: Validate your input parameters before sending a request to prevent issues with invalid input values and improve the overall stability of the service.
-
Error handling: Always check the
successproperty in the response to verify if the request was successful. If an error occurs, handle it gracefully and use the provided error message to resolve the issue. -
Content handling: Depending on your use case, you might need to process different content types such as HTML, XML, JSON, CSV, PDF, or images. Make sure to handle each content type appropriately and sanitize the content if necessary.
-
The 'no_strip' parameter: Use the
no_stripparameter when the content structure and formatting are critical to the understanding of the information. Otherwise, rely on the default content processing to preserve context and improve readability for ChatGPT.
By adhering to these best practices and understanding the Web Requests plugin's capabilities, you can effectively use it to retrieve and process web content for your ChatGPT projects.
The Web Requests plugin is proprietary software developed by WeGPT.ai. Although the code is not publicly available on GitHub, this documentation is intended to provide information about the plugin's features and usage.
All rights to the code and documentation are reserved by WeGPT.ai. The code and documentation may not be redistributed, reproduced, or modified without prior written permission from WeGPT.ai.
For licensing inquiries or any other questions regarding the usage of the Web Requests plugin or its documentation, please contact [email protected] for further information.