Integrantes: ✒️ -Fernanda Muñoz -Matias Paredes
Acceso a los cuadernos de Jupyter: http://35.247.26.79:5000/tree#
El problema que se quiere resolver es de disponibilizar un servicio de entorno analítico ocupando distintas herramientas de procesamiento de datos escalables (Base de datos con BigQuery, motor de procesamiento con Spark , interfaz de prueba de código con Jupiter Notebook bajo la arquitectura de Terraform). Dada la necesidad de procesar un conjunto de datos densos, se requiere implementar un sistema distirbuido para procesar eficientemente los datos.
Dentro de los problemas detectados, hubo en primer lugar una gran barrera que fue el acceso a la cuenta de Google cloud platform, puesto que solicita tarjeta de credito para acceder a sus servicios. Asi mismo, otros problemas fueron que habian muchos paquetes que estaban desactualizados por lo que no se podia implementar de manera correcta los diferentes lenguajes e integrarlos en jupyter. En el ambito general, hubieron muchas horas de investigacion para poder llegar al resultado obtenido.
Nuestro objetivo es poder tener un entorno práctico donde poder manipular una gran cantidad de datos al alcance de la mano. De esta manera, para poder levantar el ambiente de trabajo se requiere combinar varias tecnologías y servicios, en este caso Jupyter notebook, Google Big Query, R, Python y Apache Spark, todo esto bajo una arquitectura basada en codigo con la cual nos apoyaremos de Terraform.
Como ejemplo básico de lo que se puede logra hacer, utilizando la interfaz de Jupyter podremos ingresar datos a nuestra base de datos Big Query. Por ejemplo con el siguiente codigo en Python, podemos generar una cantidad N de personas aleatorias e ingresarlas de manera sencilla.
rows_to_insert = [(edad=53, estatura=68.18927069629541, genero='female', nombre='Carolyn Manuel', peso=1.5090926581606248),
(edad=82, estatura=55.70266007380923, genero='male', nombre='Tim Vaughn', peso=1.4713677025968352),
(edad=19, estatura=35.88645058366604, genero='male', nombre='Matt Whitehead', peso=1.4717804396700485),
(edad=45, estatura=62.34714177776431, genero='male', nombre='Anthony Turner', peso=1.5419193846793644),
(edad=33, estatura=81.03913924707561, genero='female', nombre='Diane Keyes', peso=1.6906731469220142),
(edad=27, estatura=77.9606250225021, genero='female', nombre='Dorothy Guieb', peso=1.9682002494175275),
(edad=87, estatura=75.77433626854037, genero='female', nombre='Lisa Reynolds', peso=1.848592263893368),
(edad=71, estatura=46.08094018740735, genero='male', nombre='Mike Smith', peso=1.550111882749193),
(edad=89, estatura=73.85156406243465, genero='male', nombre='Shane Halstead', peso=1.6451370044264957),
(edad=18, estatura=45.32750817059075, genero='male', nombre='Kristopher Eager', peso=2.036834995896506),
(edad=40, estatura=76.01341343608632, genero='male', nombre='John Roorda', peso=1.8613356481652992),
(edad=80, estatura=85.14753512878423, genero='male', nombre='Bruce Anderson', peso=1.4524308280574405),
(edad=43, estatura=64.33607237785482, genero='female', nombre='Frances Lopez', peso=1.6282678979104492),
(edad=72, estatura=44.686542409367135, genero='male', nombre='Daniel Parker', peso=2.0874359066940307),
(edad=38, estatura=63.716831496820596, genero='female', nombre='Emilia Mccluskey', peso=1.637577613490331),
(edad=25, estatura=54.827771346892206, genero='female', nombre='Mary Gonzales', peso=1.8597714297798233),
(edad=71, estatura=70.99515602958475, genero='female', nombre='Charlotte Maynard', peso=1.9668774517247813),
(edad=34, estatura=88.92154783666567, genero='female', nombre='Margaret Garrett', peso=1.8579289357251958),
(edad=66, estatura=76.54271294885405, genero='male', nombre='Christopher Keith', peso=1.9858323962309903),
(edad=31, estatura=61.54702494719777, genero='female', nombre='Frances Santorelli', peso=1.570490897663655)]
def export_items_to_bigquery(rows_to_insert):
# Instanciar el cliente
bigquery_client = bigquery.Client()
# Preparar la referencia al dataset y a la tabla que tenemos en Big Query
dataset_ref = bigquery_client.dataset('Dataset_1')
table_ref = dataset_ref.table('Personas')
# LLamamos a la API para obtener la tabla que referenciamos
table = bigquery_client.get_table(table_ref)
# Procedemos a ingresar en la tabla nuestras filas que creamos
errors = bigquery_client.insert_rows(table, rows_to_insert) # API request
assert errors == []De esta manera, si miramos la consola de Big Query tendermos que la inserción se realizó exitosamente

Ahora, en el caso que querramos trabajar con la información almacenada en la base de datos, podemos realizar la consulta de los datos de la misma manera.
def import_items_from_bigquery():
# Iniciacion del cliente
bigquery_client = bigquery.Client()
# Query de BigQuery
QUERY = """ SELECT * FROM `x-pivot-241800.Dataset_1.Personas` LIMIT 100 """
# Arranca la Query y se obtienen los datos
query_job = bigquery_client.query(QUERY) # API REQUEST
return query_job.to_dataframe()
De esta forma, tenemos acceso total a la base de datos Big Query a traves de la interfaz de Jupyter Notebook utilizando Python.
Para manipular los datos con Apache Spark, nos situamos en el mismo contexto de la sección anterior; Queremos obtener datos para realizar análisis y procesamiento sobre esto. Para esto, utilizamos en conjunto con Python el modulo PySpark con la cual podremos manipular los datos obtenidos

de esta manera, damos cuenta del acceso a los datos por parte de las funciones de Spark. Ahora bien, podemos realizar pequeños calculos sobre estos datos. Veamos un ejemplo donde se muestre un resumen de las edades de las personas:

Fascinante!
- Terraform
- Python 3
- R
- Google cloud Platform
- Big Query
- Servicios de VM
- Jupyter notebook
- Spark
- Cuenta vinculada a google la cual debe estar asociada a google cloud platform
- Tarjeta de credito para activar los servicios de VM
- Tener terraform vinculado al path en nuesto entorno local
- Una clave ssh existente
En primer lugar, se debe crear un proyecto en google cloud para poder consumir sus servicios. Además, se debe configurar el archivo main.tf para poder levantar el entorno de desarrollo con Terraform. En este punto se deben considerar los siguentes valores para utilizarlos dentro del archivo de configuración main.tf
- proyect_id
- credenciales del proyecto
- nombre de la clave pública ssh
El "proyect_id" se puede obtener directamente al crear un nuevo proyecto en google cloud.
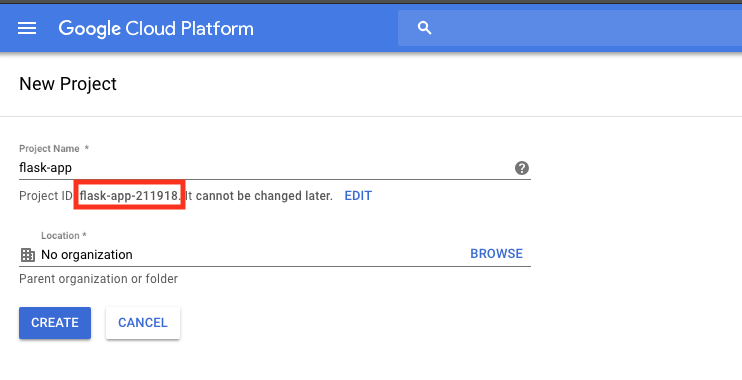
Luego de esto, se debe inicializar el archivo main.tf con los siguientes requerimientos:
provider "google" {
credentials = "${file("credenciales.json")}"
project = "proyect_id"
region = "us-west1"
}
Las configuraciones de la instancia de la VM van dentro del grupo de recurso, tales como el nombre, el tipo de máquina, la interfaz de red asi como la imagen del SO a utilizar.
resource "google_compute_instance" "default" {
...
}
Del mismo modo, la clave publica debe ser agregada dentro del grupo de recursos de la VM, donde el INSERT_USERNAME es el nombre asociado a la clave pública.
resource "google_compute_instance" "default" {
...
metadata {
sshKeys = "INSERT_USERNAME:${file("~/.ssh/id_rsa.pub")}"
}
}
Asi mismo se deben habilitar puertos:
resource "google_compute_firewall" "default" {
name = "flask-app-firewall"
network = "default"
allow {
protocol = "tcp"
ports = ["5000"]
}
}
y una variable para extraer la ip externa de la instancia:
output "ip" {
value = "${google_compute_instance.default.network_interface.0.access_config.0.nat_ip}"
}
Una vez configurado esto, se prodece a ejecutar los comandos de terraform para aplicar los cambios y crear la instancia de la VM en google cloud.
$ terraform init
$ terraform plan
$ terraform apply
Una vez creada la VM, se debe acceder a ella a traves de ssh:
- NOTA: se le solicitará la credencial de su clave publica o en su defecto su passphrase.
ssh INSERT_USERNAME@IP_EXTERNAL
En este punto se debe instalar jupyter siguiendo los siguientes comandos en la terminal ssh:
wget http://repo.continuum.io/archive/Anaconda3-4.0.0-Linux-x86_64.sh
bash Anaconda3-4.0.0-Linux-x86_64.sh
y siga las instrucciones en pantalla. Los valores predeterminados por lo general funcionan bien, pero responda sí a la última pregunta acerca de cómo anteponer la ubicación de instalación a PATH:
Do you wish the installer to prepend the
Anaconda3 install location to PATH
in your /home/haroldsoh/.bashrc ?
[yes|no][no] >>> yes
Ahora necesita compruebar si tiene un archivo de configuración de Jupyter:
ls ~/.jupyter/jupyter_notebook_config.py
si no existe, debe crear uno
jupyter notebook --generate-config
y agregue las siguientes lineas. Asegurese de colocar el mismo puerto que antepuso en el archivo de configuracion main.tf
c = get_config()
c.NotebookApp.ip = '*'
c.NotebookApp.open_browser = False
c.NotebookApp.port = <Port Number>
deberia quedar de la siguiente manera

Para iniciar Jupyter, ingrese el siguiente comando en la terminal ssh
jupyter-notebook --no-browser --port=5000
Ahora, para iniciar jupyter notebook, escriba lo siguiente en su navegador:
http://<External Static IP Address>:<Port Number>
donde, la dirección IP externa es la dirección IP de la VM y el número de puerto es el que permitimos el acceso al firewall

Para agregar un dataset de Big Query solo basta con agregar un nuevo recurso al archivo main.tf
resource "google_bigquery_dataset" "default" {
dataset_id = "my-dataset-name"
friendly_name = "test"
description = "my-description"
location = "EU"
labels = {
env = "default"
}
}
Y para agregar una tabla al dataset, se agrega lo siguiente. Se debe tener en consideración el archivo "schema.json" el cual provee la plantilla para definir los valores de la tabla.
resource "google_bigquery_table" "default" {
dataset_id = "${google_bigquery_dataset.default.dataset_id}"
table_id = "my-table-name"
time_partitioning {
type = "DAY"
}
labels = {
env = "default"
}
schema = "${file("schema.json")}"
}
Para consumir datos de algun schema en Big Query en primer lugar se requiere una clave de cuenta de servicios para Big Query. Esta se puede obtener dentro de las opciones en GoogleCloudPlatform -> API&Services -> Credentials -> new service account key.

Haga clic en "Crear", luego obtendrá la clave para esta cuenta de servicio en un archivo json. Coloque este archivo json en una carpeta que creó para su proyecto.
Instale las bibliotecas de cliente de BigQuery API de Google para Python en la VM. Las bibliotecas de python de Google BigQuery api client incluyen las funciones que necesita para conectar Jupyter a Big Query.
En la terminal ssh de la VM -> escribe el siguiente comando
$ pip install google-cloud-bigquery
Ahora debe establecer la variable de entorno llamada "GOOGLE_APPLICATION_CREDENTIALS" para apuntar a jupyter con la clave de su cuenta de servicio que acaba de crear. Esta variable le permite a Google saber dónde encontrar sus credenciales de autenticación. Ejecuta esto antes de ejecutar Jupyter Notebook.
export GOOGLE_APPLICATION_CREDENTIALS="/Users/~...~/<file-name>.json"
- Antes que nada, asegurese de tener instalado R-base-core en la VM
Para trabajar con R, deberá cargar el IRKernel y activarlo para comenzar a trabajar con R en el entorno de la notebook. Primero, necesitarás instalar algunos paquetes. Asegúrese de no hacer esto en su consola RStudio, pero en un terminal R regular
> install.packages(c('repr', 'IRdisplay', 'evaluate', 'crayon', 'pbdZMQ', 'devtools', 'uuid', 'digest'))
> devtools::install_github('IRkernel/IRkernel')
Hecho lo anterior, solo basta con hacer que el núcleo R sea visible para Jupyter:
> IRkernel::installspec()
Ahora abra jupyter notebook. Verá que R aparece en la lista de núcleos cuando cree un nuevo notebook.
- Antes que nada, asegures de tener instalado:
- JDK 1.8
- Apache Spark en su última versión estable
Para ejecutar Spark a través de jupyter notebook, se necesita un Jupyter Kernal para integrarlo con Apache Spark. En este caso se utilzará Apache Toree. Este paso consta de dos partes, instalar Apache Toree y configurarlo con Jupyter.
pip install -I https://pypi.anaconda.org/hyoon/simple toree
Ejecute el siguiente comando para configurar Apache Toree con Jupyter Notebook. Agregará los núcleos Scala, PySpark y SQL a jupyter.
jupyter toree install --spark_home /home/.../spark-2.2.0-bin-hadoop2.7/ --interpreters=Scala,PySpark --user
Ahora está listo para ejecutar su programa Spark en Jupyter notebook. Podra ver las 3 opciones (PySpark, Scala ,SQL) al crear un nuevo cuaderno.

🚀 📋 🔧 ⚙️ 🔩 ⌨️ 📦 🛠️ 🖇️ 📖 📌 ✒️ 📄 🎁 📢 🍺 🤓