模型的压缩(蒸馏、剪枝、量化)和部署,是模型在自动驾驶和物联网产业落地中的重要步骤。端上的设备
在实际工作过程中,我们遇到了很多的困难: 文档缺失、依赖库冲突、算子不支持、精度差、速度慢等。
因此,我将我在实际工作过程中的一些经验,整理成文档记录在这里,供其它开发者参考。同时,我会将过程中用到的一些脚本,整理成一些独立的工具脚本,方便大家使用。
模型部署的一般步骤为:
- 模型导出onnx
- onnx模型结构优化
- 模型量化,构建tensorRT的engine
- tensorRT模型部署
- 精度和速度测试
- 问题排查与分析
接下来,我将给出相关的工具,并对其中的关键步骤进行详细说明;
onnx是一种模型表示方式,能够将不同框架下的模型,统一表示为同一种形式;因此,尝尝被用来作为模型转换的中间节点;目前,tensorRT已经支持了直接用torch转成tensorRT的engine;但是其它的SDK框架,如MNN、TNN、Paddle-Lite、OpenVino等仍然只支持onnx格式的模型转换;并且,onnx本身也是一种很好用的模型框架,可以很方便地在上面做开发;
import torch
# 加载你的模型
model = build_model(config.model)
checkpoint = torch.load(model_path, map_location=lambda storage, loc: storage)
load_model_weight(model, checkpoint)
# 设置输入的大小
input_shape = (320, 192) # W H
dummy_input = torch.autograd.Variable(torch.randn(1, 3, input_shape[1],input_shape[0])) # N, C, H, W
# 设置输出节点名称,便于后续部署
output_names = ["s8_cls", "s8_reg", "s16_cls", "s16_reg"]
model.eval()
torch.onnx.export(
model,
dummy_input,
output_path,
verbose=True,
keep_initializers_as_inputs=False,
do_constant_folding=True,
training=False,
opset_version=11,
output_names=output_names,
)
其它常用框架基本都有导出为onnx模型的代码,可以通过搜索引擎很容易得到相关结果,在此不作介绍。
导出模型为onnx以后,如果不需要做模型量化,可以直接将onnx模型转换为所需的格式后进行模型部署;如果想快速完成部署,可以使用在线模型转换的工具来完成模型转换 https://convertmodel.com/;
onnx模型结构优化,一方面是为后续的模型量化做准备;另一方面是减少了输入和输出部分的计算,这部分计算对云端的算力而言可能是无关紧要的,但是对端上的微弱算力而言,这部分计算能省则省。
2.2.1 onnx-simplify和optimize
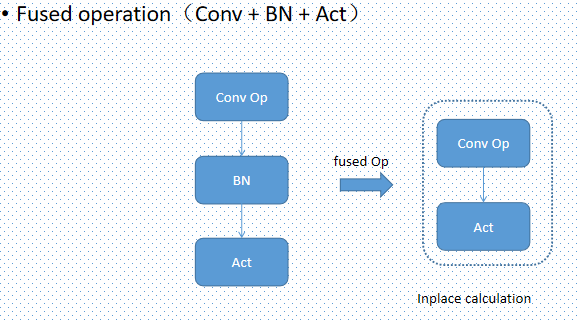
optimize的目的是进行算子的融合, 从而减少计算量;例如fuse_bn_into_conv, fuse_concat_into_reshape; 详见onnx-optimizer;
simplify的目的是消除onnx模型中的多余算子。从torch得到的onnx模型中,会存在一些从tensor计算出常量的操作,例如Reshape算子会从tensor中获取形状后给Resize算子;这就导致onnx模型中存在某些不必要的节点(最常见的是Gather节点);因此,[onnx-simplifier](https://github.com/daquexian/onnx-simplifier)会对整个网络进行一次推理,然后将这类多余的算子替换成常量.

使用在线网站,可以便捷地进行以上操作:https://www.convertmodel.com/#input=onnx&output=onnx;
2.2.2 预处理融合
在onnx-optimizer中,有一个操作是将Conv-BN结构中的BN层融合进Conv中,其原理可以简单理解为:
- Conv: Y = k * x + b
- BN: Z = (Y - m)/s
- Conv-BN: Z = (k * x + b - m)/s = k/s * x + (b - m)/s
- new Conv: k1 = k/s, b1 = (b-m)/s, Z = k1 * x + b1
那么,在某些模型中BN是放在Conv的,这种BN-Conv是否可以进行融合呢?答案是当Conv层没有padding(padding=0)时,也是可以融合的;但是当Conv层有padding时,BN-Conv的融合会导致输出的feature map与原始输出相比,在边界上存在diff;具体原理可以通过分析BN-Conv的计算过程得到,在此不作推导;
在将图片输入到模型前,常常会进行减均值除方差(normalize)的操作;基于BN-Conv层融合的原理,这个normalize过程也同样可以融合到Conv层中(需要Conv层不带padding);在端上硬件算力很小的情况下,这一融合也是十分有必要的;
2.2.3 sigmoid移除
sigmoid函数中的exp计算以及除法运算,是比较耗时的;当模型最后输出的feature map比较大时,这个过程的耗时就会更加明显;当这个feature map是输出一个置信度时,可以通过计算sigmoid的反函数,提前计算好置信度阈值,从而省掉这个sigmoid的计算;为此,在实际部署时,常常会去掉模型输出前的sigmoid节点;同时,一些transpose、resize等操作,也可以在后处理流程中通过直接访问相应位置的元素来实现,不需要在模型中进行这一步额外的计算;
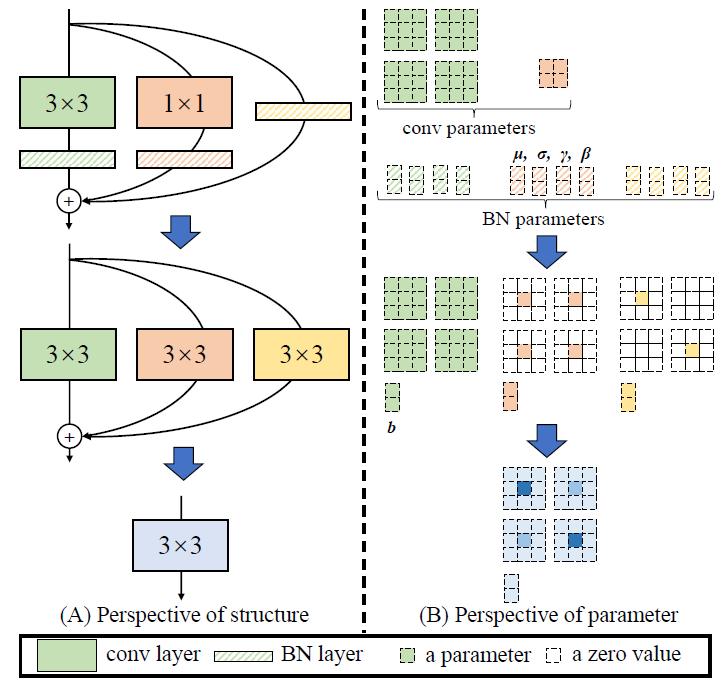
2.2.4 RepConv融合
RepConv是一种有效增加模型容量的技术。在训练时添加额外的卷积层,在部署时通过权重融合去掉这部分计算。通常情况下,RepConv的权重融合是在pytorch层面做的,但是当训练代码比较复杂或者重复代码较多时,在onnx层面进行权重的融合,可能是一个更好的选择;相关原理参见论文: RepVGG: Making VGG-style ConvNets Great Again.
2.3.1 量化的理论基础
2.3.2 量化的计算过程
2.3.3 常用的量化工具箱
2.3.4 PTQ量化
- 简单量化
- balance vector(weight equalization)
- bias correction
2.3.5 QAT量化
- QDQ模式介绍
- QDQ流程优化
- tiny-tensorRT: https://github.com/zerollzeng/tiny-tensorrt
- micronet: https://github.com/666DZY666/micronet
- ppq: https://github.com/openppl-public/ppq
- onnx-runtime quantization: https://onnxruntime.ai/docs/performance/quantization.html
- polygraphy: https://github.com/NVIDIA/TensorRT/tree/main/tools/Polygraphy