conda create -n ppo python=3.9
conda activate ppoIf you have GPU, Please install pytorch corresponding to the CUDA version because it could faster your training.
If you only have CPU for training, That's OK
I have tried the
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113 #for CUDA 11.4and torch==2.1.0+cu118, both could Work
git clone https://github.com/Elapsedf/FrozenLake.git
pip install -r requirements.txtWhen you want to train a new model in Stochasitic Mode, Please make sure your GPU memory is Enough, If you find CUDA out of memroy, Try to decline the update_freq. As this parameter gets larger, it will consume more memory
This file contain the train and test mode, you only need to change this file in the file end and run it
Main Algorithm
Please change the work dir to your own path
save_gif_images(env_name, has_continuous_action_space, max_ep_len, action_std, pretrained)
save_gif(env_name)
list_gif_size(env_name)Note that Remember to change the test_num when you want to train a new model
test()
save_gif(env_name)
list_gif_size(env_name)
Note that Remember to change the pre-trained model and the gif_num when you want to test a new model
I trained 2 Model:Determinstic and Stochastic, both are in the PreTrained dir
They correspond to different settings of a parameter of the environment, As the following
env = gym.make("FrozenLake-v1", is_slippery=False) #Deterministic
env = gym.make("FrozenLake-v1") # StochasticDeterministic Mode: The State Transition is depend on the Action which is chosen by the Actor Network
Stochastic Mode:State transfer in the environment is a stochastic process, i.e. the final outcome of the state transition does not depend only on the action but is also influenced by the environment
The following are the train result, and the ideal result is 1
 |
| Figure1: Deterministic Result |
but in the Stochastic mode the result is not so good for the environment effect
So I Training in two phases
- In the First phases,I train a model and save it
- In the Second phases, I train a new model base on the previous model in first phases
So the Results are the following
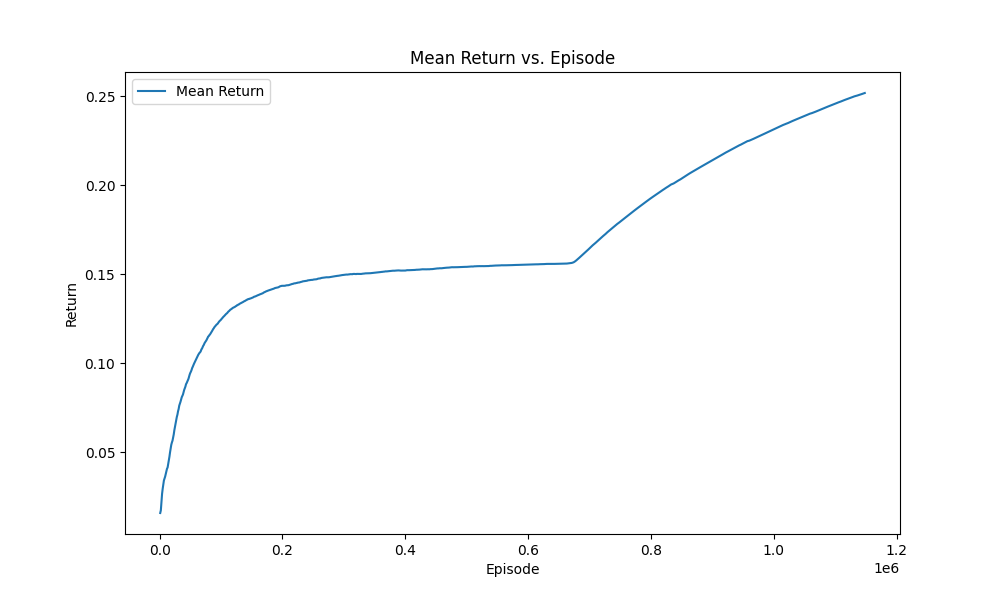 | 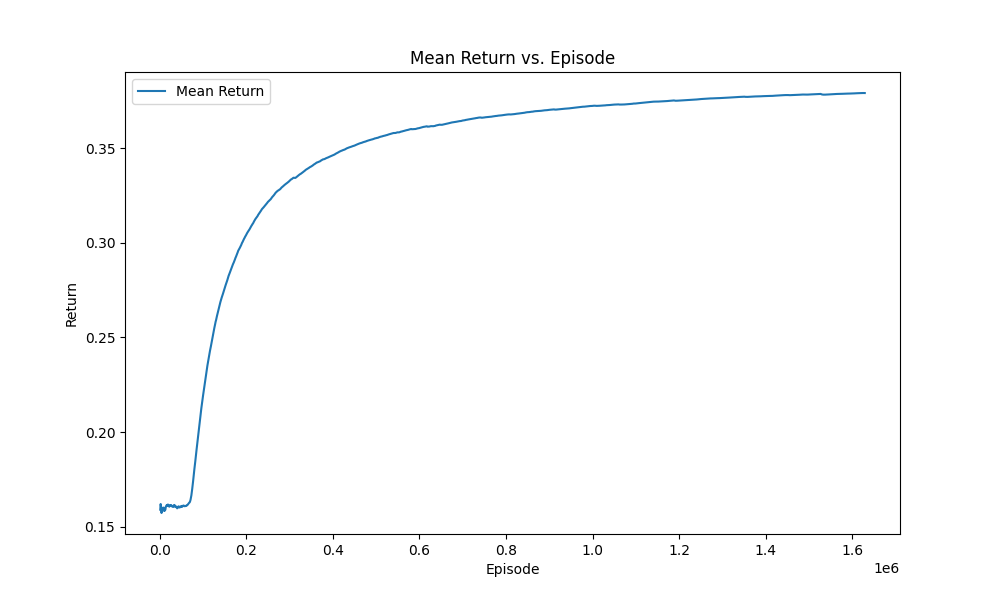 |
| Figure2:First Phase | Figure3:Second Phase(Final Result) |
The gif result please see the gif dir