
- What is Large Language Model?
- Applications
- Types of Language Models
- Evaluation of LMs
- Transformer-Based Language Models
- Generative configuration parameters for inference
- Computational challenges and Quantization
- Prompt Engineering
- Fine-Tuning
- RAG (Retrieval-Augmented Generation)
- LangChain
- LLM Model Evaluation
- AI Agents
- Refrences
Language model in simple words is a type of Machine Learning models that can perform a variety of NLP tasks such as generating and classifying text, translation and Q&A. With a main goal which is to assign probablities to a sentece.
-
The term large refers to the number of parameters that model has.
-
LLMs are trained with huge amount of data and use self-supervised learning to predict the next token in a sentence, given the surrounding context, this process is repeated until the model reaches an acceptable level of accuracy.
- Text Generation
- Machine Translation
- Summarization
- Q&A, dialogue bots, etc.....
Statistical LM is the development of probabilistic models that predict the next word in a sentece given the words the precede it.
N-gram can be defined as the contigous sequence of n items (can be letters, words or base pairs according to the application) from a given sample of text (A long text dataset).
- An n-gram model predicts the probability of a given n-gram within any sequence of words in the language.
- A good n-gram model can predict the next word in the sentence i.e the value of p(w|h) where w is the word and h is the history or the previos words.
This repo is about LLMs
Unigram ("This", "repo", "is", "about", "LLMs")
bigrams ("This repo", "repo is", "is about", "about LLMs")
- You can think of n-gram model as counting frequncies as follows: consider the previos example
P(LLMs|This repo is about) = count(This repo is about LLMs) / count(This repo is about)
- To find the next word in a sentence we need to calculate the p(w|h), let's consider the above example
P(LLMs|This repo is about)
After generalization: P(wn|w1,w2,.....,wn-1)
But how we calculate it?
P(A|B) = P(A,B)/P(B)
P(A,B) = P(A|B)P(B)
After generalization:
P(x1,x2,x3,....,xn) = P(x1)P(x2|x1)P(x3/x1,x2)......P(xn|x1,x2,....,xn-1) # Chain Rule
P(w1w2w3....wn) = ΠP(wi|w1w2....wn)
Simplifying using Markov assumption:
P(wi|w1,w2,...,wi-1) = P(wi|wi-k,....,wi-1)
For Unigram: P(w1w2,....wn) = ΠP(wi)
For Bigram: P(wi|w1w2,....wi-1) = P(wi|wi-1)
- We can extend to trigrams, 4-grams, 5-grams.
In general this is an insufficient model of language because language has long distance dependecies
e.g. The computer(s) which I had just put into the machine room on the fifth floor is (are) crashing.
Exponential (Maximum entropy) LM encode the relationship between a word and the n-gram history using feature functions. The equation is

The log-bilinear model is another example of an exponential language model.
- Sparsity probelm:
- Count(n-gram) = 0 --> Solution: Smoothing (adding small alpha)
- Count(n-1 gram) = 0 --> Solution: Backoff
- Exponential growth: The number of n-grams grows as an nth exponent of the vocabulary size. A 10,000-word vocabulary would have 10¹² tri-grams and a 100,000 word vocabulary will have 10¹⁵ trigrams.
- Generalization: Lack of generalization. If the model sees the term ‘white horse’ in the training data but does not see ‘black horse’, the MLE will assign zero probability to ‘black horse’. (Thankfully, it will assign zero probability to Purple horse as well)
NLM mainly uses RNNs (/LSTMs/GRUs)
A recurrent neural network (RNN) processes sequences by iterating through the sequence elements and maintaining a state containing information relative to what it has seen so far. In effect, an RNN is a type of neural network that has an internal loop.
- RNNs solve the sparsity problem
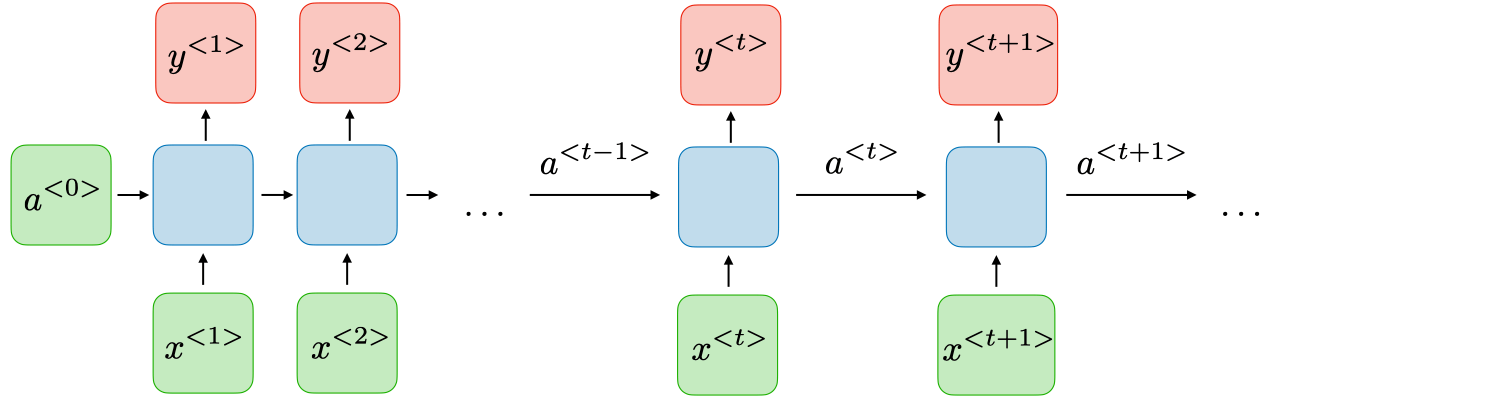
- Types of RNNs

- Disadvantages of RNNs
- Vanishing Gradiients --> Solution: LSTMs/GRUs.
- Exploding Gradients --> Solution: Truncation or squashing the gradients.
- Sequential processing/ slow.
- Can't capture information for longer sequences.
LSTMs are a special kind of RNN, capable of learning long-term dependencies.
- LSTM is made up of 3 gates.
- Input Gate: We decide to add new stuff from the present input to our present cell state scaled by how much we wish to add them.
- Forget Gate: After getting the output of previous state, h(t-1), Forget gate helps us to take decisions about what must be removed from h(t-1) state and thus keeping only relevant stuff.
- Output Gate: Finally we’ll decide what to output from our cell state which will be done by our sigmoid function.

Extrinsic evaluation is the best way to evaluate the performance of a language model by embedding it in an application and measuring how much the application improves.
- End-to-end evaluation where we can understand if a particular improvement in a component is really going to help the task at hand, however it's time consuming
An intrinsic evaluation metric is one that measures the quality of a model-independent of any application.
- Perplexity: It is a measure of how well a probability model predicts a sample.
- Perplexity is the inverse of probability and lower perplexity is better
Previosly we discussed some of the RNNs (LSTMs) Challenges: like slow computations due to sequential processing, and they can't capture contextual information for longer sequences.
- The Solution was found when the paper Attention is All You Need which introduced the Transformer architecture came to life.
It is a bidirectional transformer network that encodes inputs, it takes in text, produces a feature vector representation for each word in the sentence.
- Encoder Models: Masked Language Modeling (auto-encoders) like BERT, ALBERT, ....etc.
- Use cases: Sentiment analysis, NER, and Word classification
It is a uni-directional transformer network that generates output.
- Decoder Models: Causal Language Modeling (Autoregressive) like GPT, BLOOM.
- Use cases: Text generation.
- Span corruption modes like T5, BART.
- Use cases: Translation, Text summarization, and Question answering.
Note
Transformers has two main components: Encoder and Decoder (explained with code here)

- Max new tokens: the number of generated tokens.
- Greedy vs. random sampling:
- Greedy search: the word/token with the highest probability is selected.
- Random sampling: select a token using a random-weighted strategy across the probabilities of all tokens.

- Top-k sampling: select an output of the top-k results after applying random-weighted strategy using the probabilities.
- Top-p sampling: select an output using the random-weighted strategy with the top-ranked consecutive results by probability and cumulative probability <= p.
- Temperature: you can think of temperature as how creative out model is?
- Lowwer-temp: means strongly peaked probability distribution with more certain and realistic outputs.
- Higher-temp: means broader, flatter probability distribution with creative output but less certain.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
model_name,
# add other parameters
)
generation_config = model.generation_config
generation_config.max_new_tokens = 200
generation_config.temperature = 0.7
generation_config.top_p = 0.7
generation_config.top_k = 0.3
generation_config.num_return_sequences = 1
Approximate GPU RAM needed to store/train 1B parameters
- To store 1 parameter = 4 bytes(FP32) --> 1B parameters = 4GB
- To train 1 parameter = 24 bytes(FP32) --> 1B paramters = 80GB
This huge usage of GPU RAM will result in Out Of Memory problem: as a solution Quantization was introduced
- Instead of full precision we can use lower precision. The following image shows how to store paramters using different data types:

-
Post-Training Quantization (PTQ)
- Is a straightforward technique where the weights of an already trained model are converted to lower precision without necessitating any retraining.
- Although easy to implement, PTQ is associated with potential performance degradation.
-
Quantization-Aware Training (QAT)
- incorporates the weight conversion process during the pre-training or fine-tuning stage, resulting in enhanced model performance. However, QAT is computationally expensive and demands representative training data.
- We will focus on PTQ only.
Note
GPTQ, AutoGPTQ, GGML, Pruning, and Distillation explained in the directory Quantization
Prompt engineering improve the capacity of LLMs in wide range of common and complex tasks such as question answering and arithmetic reasoning.
In-context learning (ICL) is a specific method of prompt engineering where demonstrations of the task are provided to the model as part of the prompt (in natural language).
- LLMs demonstrate an in-context learning (ICL) ability, that is, learning from a few examples in the context.
- Many studies have shown that LLMs can perform a series of complex tasks through ICL, such as solving mathematical reasoning problems.
Classify this review:
I love chelsea
Sentiment:
Answer: The sentiment of the review "I love Chelsea" is positive.
Classify this review:
I love chelsea.
Sentiment: Positive
Classify this review:
I don't like Tottenham.
Sentiment:
Answer: The sentiment of the review "I don't like Tottenham" is negative.
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each van has 3 balls. How many tennis balls does he have now?
A: The answer is 11.
Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
A: The answer is 27.
- It is observed that standard prompting techniques (also known as general input-output prompting) do not perform well on complex reasoning tasks, such as arithmetic reasoning, commonsense reasoning, and symbolic reasoning.
CoT is an improved prompting strategy to boost the performance of LLMs such non-trivial cases involving reasoning.
- CoT incorporates intermediate reasoning steps that can lead to the final output into the prompts.

In Zero-shot CoT, LLM is first prompted by “Let’s think step by step” to generate reasoning steps and then prompted by “Therefore, the answer is” to derive the final answer.
- They find that such a strategy drastically boosts the performance when the model scale exceeds a certain size, but is not effective with small-scale models, showing a significant pattern of emergent abilities.

- While Zero-shot-CoT is conceptually simple, it uses prompting twice to extract both reasoning and answer, as explained in the figure below.

- The process involves two steps:
- First “reasoning prompt extraction” to extract a full reasoning path from a language model.
- Then use the second “answer prompt extraction” to extract the answer in the correct format from the reasoning text.
Instead of using the greedy decoding strategy in COT, the authors propose another decoding strategy called self-consistency to replace the greedy decoding strategy used in chain-of-thought prompting.
- First, prompt the language model with chain-of-thought prompting.
- Then instead of greedily decoding the optimal reasoning path, authors propose “sample-and-marginalize” decoding procedure.

Tree of thoughts which generalizes over the “Chain of Thoughts” approach to prompting language models and enables exploration over coherent units of text (“thoughts”) that serve as intermediate steps toward problem-solving.
- ToT allows LMs to perform decision-making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices.
- The results/experiments show that ToT significantly enhances language model's problem-solving abilities on three novel tasks requiring non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords.

- The ToT does 4 things:
- Thought decomposition
- Thought generator
- State evaluator
- Search algorithm.
Self-Ask Prompting is a progression from Chain Of Thought Prompting, which improves the ability of language models to answer complex questions.

ReAct is a framework allows LLMs to:
- Reason.
- Then take action.

HtT is a frame work that can improve reasoning and reduce hallucinations of LLMs.
- Implementation of HtT
- Induction Stage: LLM is used to generate and verify rules over a set of training examples. Rules that appear frequently and lead to correct answers are collected into a rule library/dataset.
- Deduction Stage: LLM is used to generate and verify rules over a set of training examples. Rules that appear frequently and lead to correct answers are collected into a rule library/dataset.
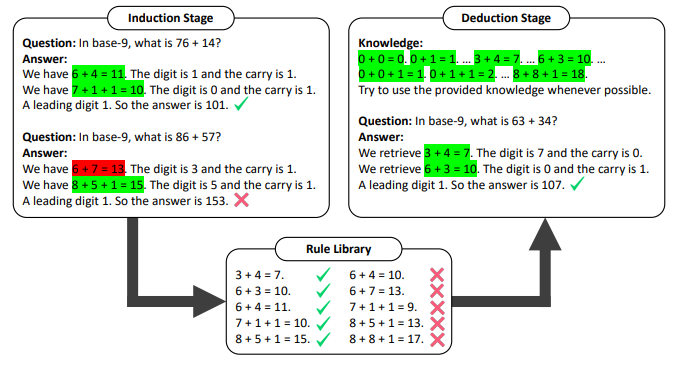
This is an active research area and the following section discusses some attempts towards automatic prompt design approaches.
1. Automatic Prompt Augmentation and Selection COT:
Prompt Augmentation and Selection COT is a three step process:
- Augment: Generate multiple pseudo-chains of thought given question using few-shot or zero-shot CoT prompts;
- Prune: Prune pseudo chains based on whether generated answers match ground truths.
- Select: Apply a variance-reduced policy gradient strategy to learn the probability distribution over selected examples, while considering the probability distribution over examples as policy and the validation set accuracy as reward.
2. Auto-CoT: Automatic Chain-of-Thought Prompting:
In Automatic Chain-of-Thought Prompting in Large Language Models, the authors propose Auto-CoT paradigm to automatically construct demonstrations with questions and reasoning chains. In this technique, authors adopted clustering techniques to sample questions and then generates chains.

- Auto-CoT consists of the following main stages:
- Question clustering: Perform cluster analysis for a given set of questions Q. First compute a vector representation for each question in Q by Sentence-BERT.
- Demonstration selection: Select a set of representative questions from each cluster; i.e. one demonstration from one cluster.
- Rationale generation: Use zero-shot CoT to generate reasoning chains for selected questions and construct few-shot prompt to run inference.

1. In-context learning: Explained above
When we have access to full LLM model.
- There are 2 ways we can do this feature based finetuning:
- Updating only Output Layer.
- Updating all Layers (Full Finetuning )
PEFT tends to fine-tune a small number of (extra) parameters while maintaining pretrained parameters frozen. Which result in decreasing computational and storage costs.
- Types of PEFT:
-
Adapters: This module is added to the existing pretrained model . By inserting adapters after the multi-head attention and feed-forward layers in the transformer architecture, we can update only the parameters in the adapters during fine-tuning while keeping the rest of the model parameters frozen.
-
LoRA: Freezing the pre-trained model weights and injecting trainable rank decomposition matrices into each layer of the transformer architecture which reduces number of trainable parameters .
-
Prompt Tuning Prompt tuning prepends the model input embeddings with a trainable tensor (known as “soft prompt”) that would learn the task specific details.
- The prompt tensor is optimized through gradient descent. In this approach rest of the model architecture remains unchanged.

-
Prefix Tuning Prefix Tuning is a similar approach to Prompt Tuning. Instead of adding the prompt tensor to only the input layer, prefix tuning adds trainable parameters are prepended to the hidden states of all layers.
- Soft prompts are parametrized through a feed-forward network and added to all the hidden states of all layers. Pre-trained transformer’s parameters are frozen and only the prefix’s parameters are optimized.
-
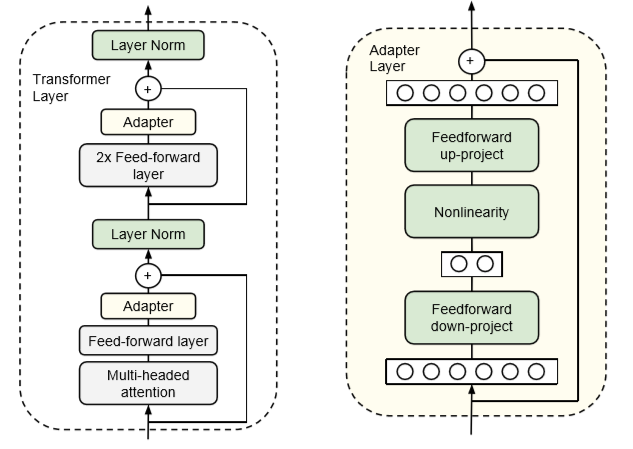

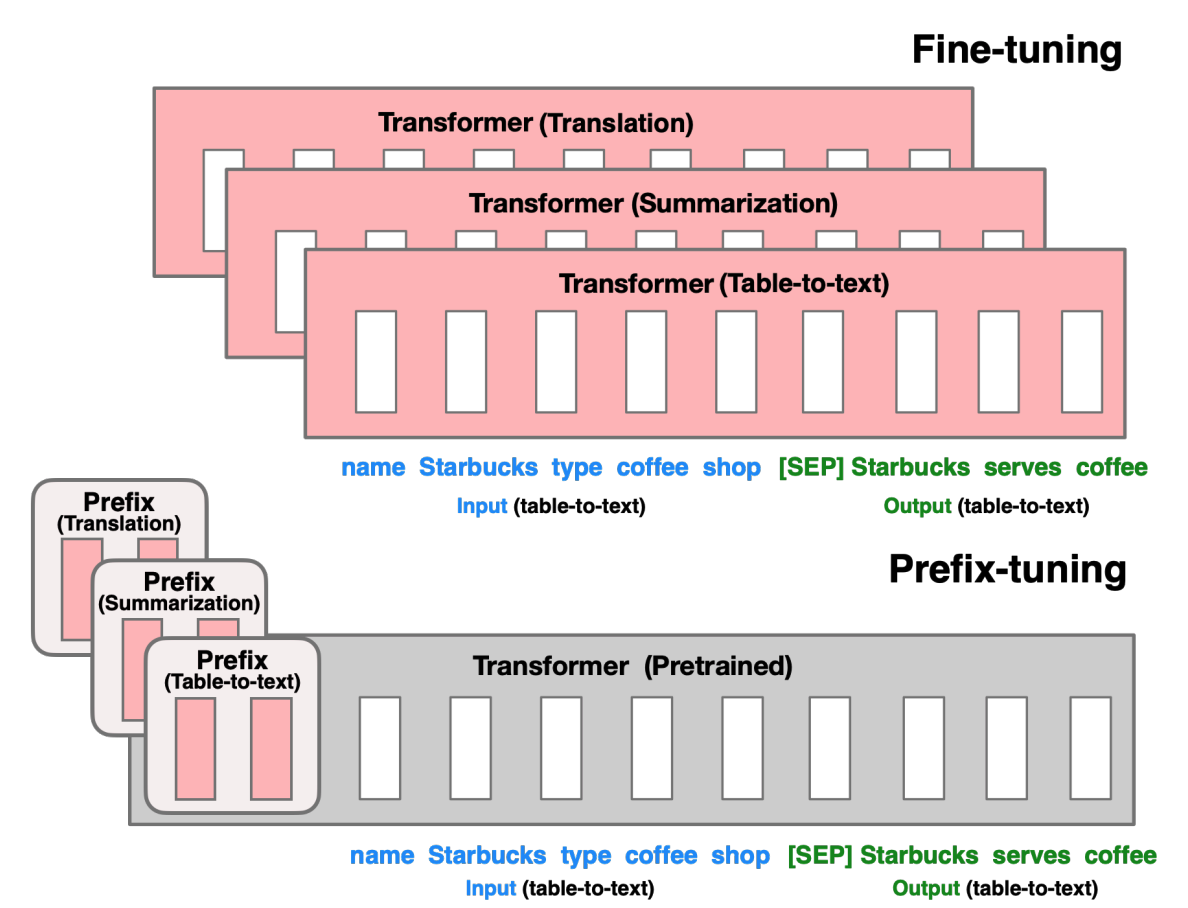
In this approach LLM is finetuned using both supervised learning and reinforcement learning. It allows LLM to learn from human feedback. RLHF can efficiently train LLMs with less labelled data and improve their performance on specific tasks.
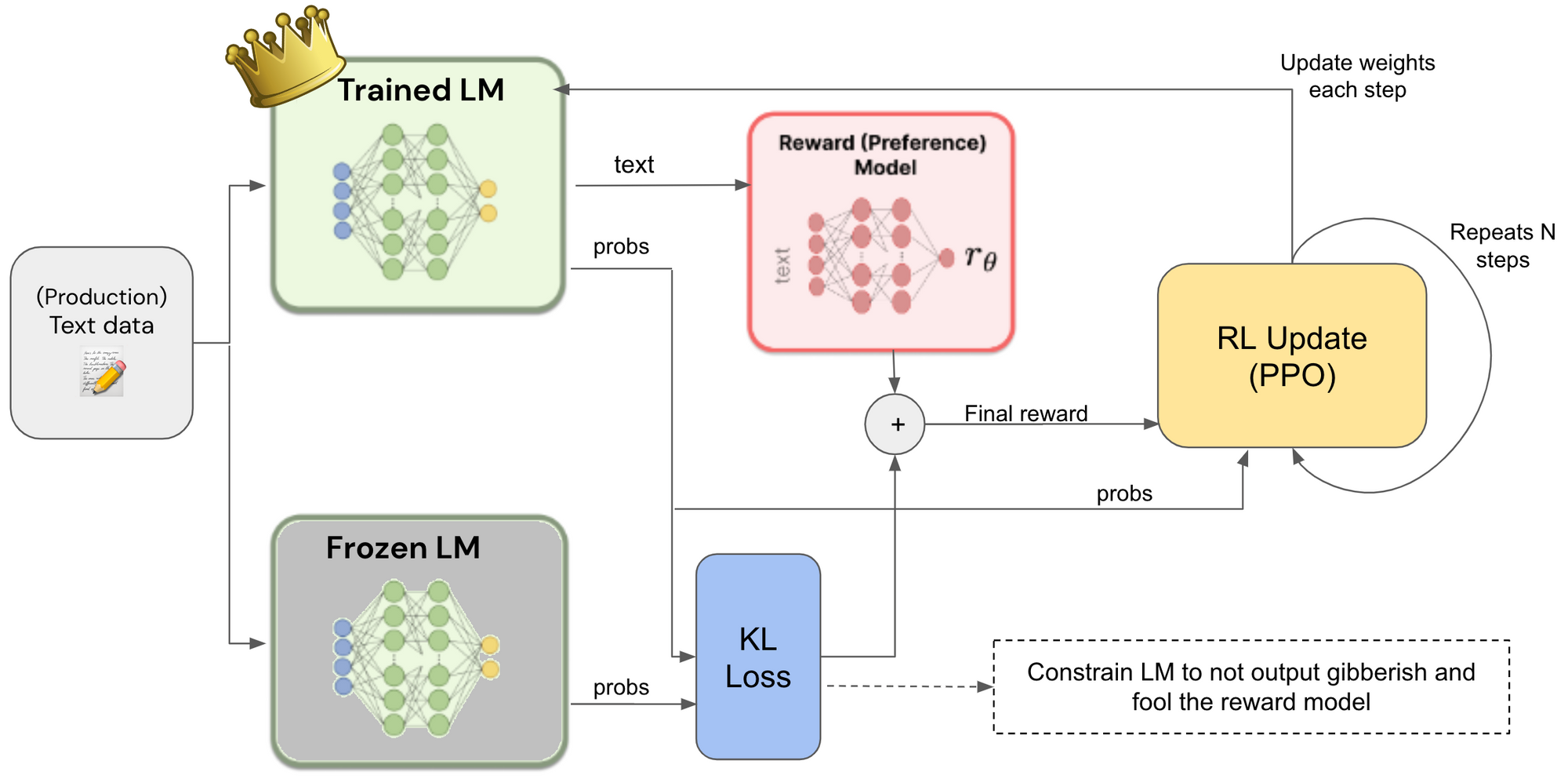
Note
For further details about theory and implementation of fine-tuning check the directory Fine-Tuning.
Retrieval-augmented generation is a technique used in natural language processing that combines the power of both retrieval-based models and generative models to enhance the quality and relevance of generated text.
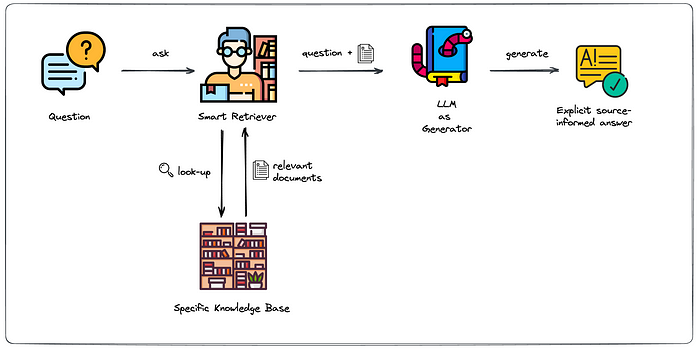
- Retrieval-augmented generation has 2 main componenets:
- Retrieval models: These models are designed to retrieve relevant information from a given set of documents or a knowledge base. (for further details check Information Retrieval Lecture from Stanford here)
- Generative models: Generative models, on the other hand, are designed to generate new content based on a given prompt or context.
Retrieval-augmented generation combines these two approaches to overcome their individual limitations. In this framework, a retrieval-based model is used to retrieve relevant information from a knowledge base or a set of documents based on a given query or context. The retrieved information is then used as input or additional context for the generative model. The generative model can leverage the accuracy and specificity of the retrieval-based model to produce more relevant and accurate text. It helps the generative model to stay grounded in the available knowledge and generate text that aligns with the retrieved information.
- Building your own RAG engine: There are a few solutions out there where you can test building your own RAG engine Langchain and llama-index are the most recommended (You will find notebooks of how to do that in LangChain and llama-index directories and also u will find the work flow explained in LangChain part)
- Source data: This data serves as the knowledge reservoir that the retrieval model scans through to find relevant information.
- Data chunking: Data is divided into manageable “chunks” or segments. This chunking process ensures that the system can efficiently scan through the data and enables quick retrieval of relevant content.
- Text-to-vector conversion (Embeddings): Converting the textual data into a format that the model can readily use. When using a vector database, this means transforming the text into mathematical vectors via a process known as “embedding.”
- Links between source data and embeddings: The link between the source data and embeddings is the linchpin of the RAG architecture. A well-orchestrated match between them ensures that the retrieval model fetches the most relevant information, which in turn informs the generative model to produce meaningful and accurate text.
There is no reason for a question to be semantically similar to its answer. RAG can lead to many irrelevant documents being fed to the LLM without being provided the right context for an answer. One solution to that is to use the Hypothetical Document Embeddings (HyDE) technique.
The idea is to use the LLM to generate a hypothetical answer, embed that answer, and use this embedding to query the vector database. The hypothetical answer will be wrong, but it has more chance to be semantically similar to the right answer.

LangChain is an opne-source framework designed to create applications using LLMs (Large Language Models), langchain has 6 building blocks as shown in the following image.

- Prerequisites
!pip install -q langchain, openai
import openai, os
os.environ["OPENAI_API_KEY"] = "Your-API-Key"
# or an alternative
openai.api_key = "Enter Your OpenAI key"
- Models
LangChain serves as a standard interface that allows for interactions with a wide range of Large Language Models (LLMs).

from langchain.llms import OpenAI
llm = OpenAI(temperature=0.8)
Question = "What is the capital of Egypt?"
print(llm(Question))
- Prompts
A prompt refers to the statement or question provided to the LLM to request information.

from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables= ["input"],
template = "What is the {input} of Egypt?",
)
print(prompt.format(input = "capital"))
- Chains
While using a single LLM may be sufficient for simpler tasks, LangChain provides a standard interface and some commonly used implementations for chaining LLMs together for more complex applications, either among themselves or with other specialized modules. Or you can think simple chain can be defined as sequence of calls.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
llm = OpenAI(temperature = 0.8)
prompt = PromptTemplate(
input_variables= ["input"],
template = "What is the largest {input} in the world?",
)
chain = LLMChian(llm = llm, prompt = prompt)
chain.run("USA")
chain.run("Germany")
- Memory
The Memory module in LangChain is designed to retain a concept of the state throughout a user’s interactions with a language model.

from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.save_context(
{"input": "Describe LSTM"},
{"output": "LSTM is a type of recurrent neural network architecture that is widely used for sequential and time series data processing."}
)
memory.load_memory_variables({})
from langchain import ConversationChain, OpenAI, PromptTemplate, LLMChain
from langchain.memory import ConversationBufferWindowMemory
# Creating LLM template
template = """Assistant is a large language model trained by OpenAI.
{history}
Human: {human_input}
Assistant:"""
prompt = PromptTemplate(input_variables=["history", "human_input"], template= template)
chat_chain = LLMChain(
llm= OpenAI(openai_api_key= "YOUR-API-KEY",temperature=0),
rompt= prompt,
verbose= True,
memory= ConversationBufferWindowMemory(k= 2),
)
output = chat_chain.predict(
human_input= "What is the capital of Egypt?"
)
print(output)
- Types of Memory

- Agents
The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
from langchain.agents import load_tools, initialize_agent, AgentType
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature= 0)
tools = load_tools(["llm-math","wikipedia"], llm=llm)
agent= initialize_agent(
tools,
llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose = True
)
agent("What is the 10% of 400?")
-
Indexes
Indexes refer to ways to structure documents so that LLMs can best interact with them. Most of the time when we talk about indexes and retrieval we are talking about indexing and retrieving data. The primary index and retrieval types supported by LangChain are currently centered around vector databases, and therefore a lot of the functionality we dive deep on those topics.- Document Loaders: Classes responsible for loading documents from various sources.
- Text Splitters: Classes responsible for splitting text into smaller chunks.
- VectorStores: The most common type of index. One that relies on embeddings.
- Retrievers: Interface for fetching relevant documents to combine with language models.
Note
You will find further details in LangChain directory
LLM model evals are focused on the overall performance of the foundational models.
-
LLM Evaluation Metrics
-
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) Score: ROUGE score is a set of metrics commonly used for text summarization tasks, where the goal is to automatically generate a concise summary of a longer text. ROUGE was designed to evaluate the quality of machine-generated summaries by comparing them to
reference summaries provided by humans.ROUGE = ∑ (Recall of n-grams)
- Recall of n-grams is the number of n-grams that appear in both the machine-generated summary and the reference summaries divided by the total number of n-grams in the reference summaries.
- Code
import evaluate rouge = evaluate.load('rouge') predictions = ["hello there", "general kenobi"] references = ["hello there", "general kenobi"] results = rouge.compute(predictions=predictions, references=references) print(results)- Results
{'rouge1': 1.0, 'rouge2': 1.0, 'rougeL': 1.0, 'rougeLsum': 1.0} -
BLEU (Bilingual Evaluation Understudy) Score: BLEU score is a widely used metric for machine translation tasks, where the goal is to automatically translate text from one language to another. It was proposed as a way to assess the quality of machine-generated translations by comparing them to a set of reference translations provided by human translators.
BLEU = BP * exp(∑pn)
- BP (Brevity Penalty) is a penalty term that adjusts the score for translations that are shorter than the reference translations. It is calculated as min(1, (reference_length / translated_length)), where reference_length is the total number of words in the reference translations, and translated_length is the total number of words in the machine-generated translation.
- pn is the precision of n-grams, which is calculated as the number of n-grams that appear in both the machine-generated translation and the reference translations divided by the total number of n-grams in the machine-generated translation.
- Code
import evaluate predictions = ["hello there general kenobi", "foo bar foobar"] references = [["hello there general kenobi", "hello there !"],["foo bar foobar"]] bleu = evaluate.load("bleu") results = bleu.compute(predictions=predictions, references=references) print(results)- Results
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.1666666666666667, 'translation_length': 7, 'reference_length': 6} -
perplexity
-
Human Evaluations
-
etc...
-
-
Benchmarks
| Benchmark | Factors Considered for Evaluation |
|---|---|
| GLUE | Grammar, Paraphrasing, Text Similarity, Inference, Textual Entailment, Resolving Pronoun References |
| SuperGLUE | Natural Language Understanding, Reasoning, Understanding complex sentences beyond training data, Coherent and Well-Formed Natural Language Generation, Dialogue with Human Beings, Common Sense Reasoning (Everyday Scenarios and Social Norms and Conventions), Information Retrieval, Reading Comprehension |
| Big Bench | Generalization abilities |
| MMLU | Language understanding across various tasks and domains |
| OpenAI Evals | Accuracy, Diversity, Consistency, Robustness, Transferability, Efficiency, Fairness of text generated |
| ANLI | Robustness, Generalization, Coherent explanations for inferences, Consistency of reasoning across similar examples, Efficiency in terms of resource usage (memory usage, inference time, and training time) |
| MultiNLI | Understanding relationships between sentences across different genres |
| SQUAD | Reading comprehension tasks |
| etc... | .................... |
There is difference between LLM model evals and LLM system evals.
- LLM model evals focuses on the overall performance.
- LLM system evals is the complete evaluation of components that you have control of in your system.
For ML practitioners, the task also starts with model evaluation. One of the first steps in developing an LLM system is picking a model (i.e. GPT 3.5 vs 4 vs Palm, etc.). The LLM model eval for this group, however, is often a one-time step. Once the question of which model performs best in your use case is settled, the majority of the rest of the application’s lifecycle will be defined by LLM system evals. Thus, ML practitioners care about both LLM model evals and LLM system evals but likely spend much more time on the latter.
Benchmarks can not be always applied to evaluate LLMs since the corect or most helpful answer can be formulated in different ways. Which would give limitations in real-world performance.
- How we can evaluate performance of LLMs if the previos methods are no longer valid?
- Leveraging human evaluations: Human evals gives the most natural measure of quality, but it does't scale well, relatively slow and costly.
- LLMs as judges:
Using LLMs as judges to evaluate other LLMs, GPT-4 can match human prefrences with over 80% agreement when evaluating conversational chatbots.
- Practical examples using langchain (check note-book)
- Types of evaluation
- Conciseness evaluation: measures if the the submission concise and to the point.
- Correctness using an additional reference: This might not be the best choice as we are not sure if the LLM has the correct knowledge. It also requires reference.
- Custom criteria: Deifne your own criteria to evaluate teh generations.
- Pairwise comparison and scoring: asks the model to choose from two generations or generate scores for the quality.
- Types of evaluation
# Load your model model_name = "meta-llama/Llama-2-13b-chat-hf" # Load your Evaluator from langchain.chat_models import ChatOpenAI os.environ["OPENAI_API_KEY"] = "Enter Your API-KEY" evaluation_llm = ChatOpenAI(model="gpt-4") # Generate text with your model prompt = "What is the capital of Egypt?" pred = generate(prompt) # Evaluation 1-Conciseness evaluation from langchain.evaluation import load_evaluator evaluator = load_evaluator("criteria", criteria="conciseness", llm=evaluation_llm) eval_result = evaluator.evaluate_strings( prediction=pred, input=prompt, ) # Evaluation 2-Correctness using additional reference evaluator = load_evaluator("labeled_criteria", criteria="correctness", llm=evaluation_llm,requires_reference=True) eval_result = evaluator.evaluate_strings( prediction=pred, input=prompt, reference="The capital of Egypt is Alexandria." ) ## Evaluation 3-Custom criteria custom_criterion = {"eli5": "Is the output explained in a way that a 5 yeard old would unterstand it?"} evaluator = load_evaluator("criteria", criteria=custom_criterion, llm=evaluation_llm) eval_result = evaluator.evaluate_strings( prediction=pred, input=prompt, ) # Evaluation 4-Pairwise comparison and scoring prompt = "Write a short email to your boss about the meeting tomorrow." pred_a = generate(prompt) prompt = "Write a short email to your boss about the meeting tomorrow" # remove the period to not use cached results pred_b = generate(prompt) evaluator = load_evaluator("pairwise_string", llm=evaluation_llm) eval_result = evaluator.evaluate_string_pairs( prediction=pred_a, prediction_b=pred_b, input=prompt, )- RAG evaluation check langchain directory
- Practical examples using langchain (check note-book)
Will be upadated later