
You can also find all 54 answers here 👉 Devinterview.io - Computer Vision
Computer Vision, a branch of Artificial Intelligence, aims to enable computers and machines to interpret and understand visual information such as images and videos. The field draws inspiration from the human visual system to replicate similar functions in machines.
By emulating the visual faculties present in humans, Computer Vision tasks can be broken down into several steps, each corresponding to a particular function or mechanism observed in the human visual system.
These steps include:
-
Visual Perception: Taking in visual information from the environment. In the case of machines, data is acquired through devices like cameras.
-
Feature Extraction: Identifying distinctive patterns or characteristics in the visual data. In humans, this involves encoding visual information in the form of object contours, textures, and colors. For machines, this may involve techniques such as edge detection or region segregation.
-
Feature Representation and Recognition: This encompasses grouping relevant features and recognizing objects or scenes based on these features. In the context of artificial systems, this is achieved through sophisticated algorithms such as neural networks and support vector machines.
-
Data Analysis and Interpretation: Understanding objects, actions, and situations in the visual context. This step can involve multiple layers of processing to extract detailed insights from visual data, similar to how the human brain integrates visual input with other sensory information and prior knowledge.
| Human Vision | Computer Vision | |
|---|---|---|
| Data Input | Sensed by eyes, then registered and processed by the brain | Captured through cameras and video devices |
| Hardware | Eyes, optic nerves, and the visual cortex | Cameras, storage devices, and processors (such as CPUs or GPUs) |
| Perception | Real-time visual comprehension with recognized patterns, depth, and motion | Data-driven analysis to identify objects, classify scenes, and extract features |
| Object Recognition | Contextual understanding with the ability to recognize familiar or unfamiliar objects based on prior knowledge | Recognition based on statistical models, trained on vast amounts of labeled data |
| Robustness | Adapts to varying environmental conditions, such as lighting changes and occlusions | Performance affected by factors like lighting, image quality, and occlusions |
| Educative Process | Gradual learning and refinement of vision-related skills from infancy to adult stages | Continuous learning through exposure to diverse visual datasets and feedback loops |
While modern-day Computer Vision systems have made significant strides in understanding visual information, they still fall short of replicating the speed, flexibility, and generalization observed in human vision.
Researchers in the field continue to work on developing innovative algorithms and improving hardware capabilities to address challenges like visual clutter, three-dimensional scene understanding, and complex context recognition, aiming for systems that are not only efficient but also reliable and adaptable in diverse real-world scenarios.
A Computer Vision (CV) system processes and interprets visual data to make decisions or disambiguate tasks. These systems perceive, understand, and act on visual information, much like the human visual system.
The components of a Computer Vision System generally include tasks such as Image Acquisition, Pre-processing, Feature Extraction, Image Segmentation, Object Recognition, and Post-processing.
The Image Acquisition module typically interfaces with devices such as smartphones, digital cameras, or webcams. In some cases, it may access pre-recorded video or static images.
This stage standardizes the input data for robust processing. Techniques like noise reduction, contrast enhancement, and geometric normalization ensure quality data.
The system identifies key visual attributes for analyzing images. Methods can range from basic edge detection and corner detection to more advanced techniques powered by deep neural networks.
This component divides the image into meaningful segments or regions for clearer analysis, doing tasks such as identifying individual objects or distinguishing regions of interest.
-
Object Recognition: Utilizes advanced algorithms for detecting and classifying objects within the image. Common methods include template matching, cascade classifiers, or deep learning networks such as R-CNN, YOLO, or SSD.
-
3D Modeling: This optional step constructs a 3D representation of the scene or object.
Upon analyzing the visual input, the system makes decisions or takes actions based on its interpretation of the data.
The Post-Processing module cleans, clarifies, and enhances the identified information or assessed scene, to improve task performance or user interpretation.
Image Segmentation involves dividing a digital image into multiple segments (sets of pixels) to simplify image analysis.
- Intensity-based Segmentation: Segments based on pixel intensity.
- Histogram Thresholding: Segments via pixel intensity histograms.
- Color-based Segmentation: Segments based on color.
- Edge Detection: Segments by identifying edges.
- Region Growing: Segments by adjacent pixel similarity.
- Over-segmentation: Too many segments making analysis complex.
- Under-segmentation: Loss of detail.
- Noise Sensitivity: Sensitive to image noise.
- Shadow and Highlight Sensitivity: Segments shaded and highlighted areas inconsistently.
- Jaccard Index: Measures similarity between sets.
- Dice Coefficient: Measures the spatial overlap between two segments.
- Relative Segmentation Accuracy: Quantifies success based on correctly segmented pixels.
- Probabilistic Rand Index: A statistical measure of the similarity between two data clusters.
Here is the Python code:
import numpy as np
import cv2
# Load image
image = cv2.imread('example.png')
# Convert to RGB (if necessary)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Flatten to 2D array
pixels = image.reshape(-1, 3).astype(np.float32)
# Define K-means parameters
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.2)
k = 3
# Apply K-means
_, labels, centers = cv2.kmeans(pixels, k, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
# Reshape labels to the size of the original image
labels = labels.reshape(image.shape[0], image.shape[1])
# Create k segments
segmented_image = np.zeros_like(image)
for i in range(k):
segmented_image[labels == i] = centers[i]
# Display segments
plt.figure()
plt.imshow(image)
plt.title('Original Image')
plt.show()
plt.figure()
plt.imshow(segmented_image)
plt.title('Segmented Image')
plt.show()While Image Processing and Computer Vision share some common roots and technologies, they serve distinct purposes.
- Definition: Image processing involves the processing of an image to enhance or extract information.
- Objective: The goal here is to improve image data for human interpretation or storage efficiency.
- Focus: Image processing is typically concerned with pixel-level manipulations.
- Main Tools: Image processing often uses techniques such as filtering, binarization, and noise reduction.
- Applications: Common applications include photo editing, document scanning, and medical imaging.
- Definition: Computer vision encompasses the automatic extraction, analysis, and understanding of information from images or videos.
- Objective: The aim is to make meaning from visual data, enabling machines to comprehend and act based on what they "see."
- Focus: Computer vision works at a higher level, processing information from an entire image or video frame.
- Main Tools: Computer vision makes use of techniques such as object detection, feature extraction, and deep learning for image classification and segmentation.
- Applications: Its applications are diverse, ranging from self-driving cars and augmented reality to systems for industrial quality control.
Edge detection methods aim to find the boundaries in images. This step is vital in various computer vision tasks, such as object recognition, where edge pixels help define shape and texture.
Modern edge detection methods are sensitive to various types of image edges:
- Step Edges: Rapid intensity changes in the image.
- Ramp Edges: Gradual intensity transitions.
- Roof Edges: Unidirectional edges associated with a uniform image region.
The Sobel operator is one of the most popular edge detection methods. It calculates the gradient of the image intensity by convolving the image with small[ square 3x3 convolution kernels][4]. One for detecting the x-gradient and the other for the y-gradient.
These kernels are:
The magnitude
The calculated
The Canny edge detector is a multi-step algorithm which can be outlined as follows:
- Noise Reduction: Apply a Gaussian filter to smooth out the image.
- Gradient Calculation: Use the Sobel operator to find the intensity gradients.
- Non-Maximum Suppression: Thins down the edges to one-pixel width to ensure the detection of only the most distinct edges.
- Double Thresholding: To identify "weak" and "strong" edges, pixels are categorized based on their gradient values.
- Edge Tracking by Hysteresis: This step defines the final set of edges by analyzing pixel gradient strengths and connectivity.
Here is the Python code:
import cv2
# Load the image in grayscale
img = cv2.imread('image.jpg', 0)
# Apply Canny edge detector
edges = cv2.Canny(img, 100, 200)
# Display the original and edge-detected images
cv2.imshow('Original Image', img)
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()import cv2
import numpy as np
from matplotlib import pyplot as plt
# Load the image in grayscale
img = cv2.imread('image.jpg', 0)
# Compute both G_x and G_y using the Sobel operator
G_x = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=3)
G_y = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=3)
# Compute the gradient magnitude and direction
magnitude, direction = cv2.cartToPolar(G_x, G_y)
# Display the results
plt.subplot(121), plt.imshow(magnitude, cmap='gray')
plt.title('Gradient Magnitude'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(direction, cmap='gray')
plt.title('Gradient Direction'), plt.xticks([]), plt.yticks([])
plt.show()Convolutional Neural Networks (CNNs) have revolutionized the field of computer vision with their ability to automatically and adaptively learn spatial hierarchies of features. They are at the core of many modern computer vision applications, from image recognition to object detection and semantic segmentation.
- Input Layer: Often a matrix representation of pixel values.
- Convolutional Layer: Utilizes a series of learnable filters for feature extraction.
- Activation Layer: Typically employs ReLU, introducing non-linearity.
- Pooling Layer: Subsambles spatial data, reducing dimensionality.
- Fully Connected Layers: Classic neural network architecture for high-level reasoning.
- Local Receptive Field: Small portions of the image are convolved with the filter, which is advantageous for capturing local features.
- Parameter Sharing: A single set of weights is employed across the entire image, reducing the model's training parameters significantly.
- Downsampling: This process compresses the spatial data, making the model robust to variations in scale and orientation.
- Invariance: By taking, for instance, the average or maximum pixel intensity in a pooling region, pooling layers display invariance toward small translations.
Each convolutional layer, in essence, stacks its learned features from preceding layers. Early layers are adept at edge detection, while deeper layers can interpret these edges as shapes or even complex objects.
With every subsequent convolutional layer, the receptive field—the portion of the input image influencing a neuron's output—expands. This expansion enables the network to discern global relationships from intricate local features.
CNNs inherently offer overfitting avoidance through techniques like pooling and, more importantly, data augmentation, thereby enhancing their real-world adaptability. Moreover, dropout and weight decay are deployable regularizers to curb overfitting, particularly in tasks with limited datasets.
CNNs distinctly differ from traditional computer vision methods that require manual feature engineering. CNNs automate this process, a characteristic vital for intricate visual tasks like object recognition.
CNNs undergird a profusion of practical implementations ranging from predictive policing with video data to hazard detection in autonomous vehicles. Their efficacy in these real-time scenarios is primarily due to their architecture's efficiency at processing visual information.
Depth perception is crucial in various computer vision tasks, improving localization precision, object recognition, and 3D reconstruction.
Depth assists in separating foreground objects from the background, crucial in immersive multimedia, robotics, and precision motion detection.
Incorporating depth enhances the precision of object recognition, especially in cluttered scenes, by offering valuable spatial context.
Depth data enables the accurate arrangement and orientation of objects within a scene.
Computing depth can lead to image enhancements such as depth-based filtering, super-resolution, and scene orientation corrections.
Understanding depth leads to more user-friendly interfaces, especially in augmented reality and human-computer interaction applications.
Depth contributes to realistic rendering of virtual objects in live-action scenes. Its role in producing immersive 3D experiences in movies, games, and virtual reality is undeniable.
Monocular depth is classified into five categories:
- From cues: Depth is inferred from indications like occlusions and textures.
- From defocus: Depth is assessed from changes in focus, observed in systems like light field cameras.
- From focus: Depth is deduced based on varying sharpness.
- From behavioral cues: Depth is gauged using prior knowledge about object attributes like size or motion.
- Features: Modern methods often leverage CNN-based estimators.
Binocular vision includes:
- Disparity: Depth is inferred from discrepancies in object position between the left and right camera perspectives.
- Shape from shading: Depth is extracted by assessing object surface topography from differing lighting angles.
By fusing depth observations from various viewpoints, multiview methods offer improved depth precision and can often address occlusion challenges.
The combination of depth data from sensors like the Kinect with traditional RGB images.
These approaches include sensors that estimate depth based on the time light takes to travel to an object and back, or the deformation of projected light patterns.
LiDAR scans scenes with laser light, while stereo vision systems ascertain depth from the discrepancy between paired camera views.
Object recognition, which involves identifying and categorizing objects in images or videos, can be challenging in several ways, especially with variations in lighting and object orientation.
-
Occlusion: Objects might be partially or completely hidden, making accurate identification difficult.
-
Varying Object Poses: Different orientations, such as tilting, rotating, or turning, can make it challenging to recognize objects.
-
Background Clutter: Contextual noise or cluttered backgrounds can interfere with identifying objects of interest.
-
Intra-Class Variability: Objects belonging to the same class can have significant variations, making it hard for the model to discern common characteristics.
-
Inter-Class Similarities: Objects from different classes can share certain visual features, leading to potential misclassifications.
-
Lighting Variations: Fluctuations in ambient light, such as shadows or overexposure, can distort object appearances, affecting their recognition.
-
Perspective Distortions: When objects are captured from different viewpoints, their 2D representations can deviate from their 3D forms, challenging recognition.
-
Visual Obstructions: Elements like fog, rain, or steam can obscure objects in the visual field, hindering their identification.
-
Resolution and Blurring: Images with low resolution or those that are blurry might not provide clear object details, impacting recognition accuracy.
-
Semantic Ambiguity: Subtle visual cues, or semantic ambiguities, can make it challenging to differentiate and assign the correct label among visually similar objects.
-
Mirror Images: Object recognition systems should ideally be able to distinguish between an object and its mirror image.
-
Textured Surfaces: The presence of intricate textures can sometimes confuse recognition algorithms, especially when shapes are:
- 3D
- Convex
- Large in size
-
Speed and Real-Time Constraints: The requirement for rapid object recognition, such as in automated manufacturing or self-driving cars, poses a challenge in ensuring quick and accurate categorization.
-
Data Augmentation: Generating additional training data by applying transformations like rotations, flips, and slight brightness or contrast adjustments.
-
Feature Detectors and Descriptors: Utilizing algorithms like SIFT, SURF, or ORB for reliable feature extraction and matching, enabling robustness against object orientation and background clutter.
-
Pose Estimation: Using methods like the Perspective-n-Point (PnP) algorithm, which takes 2D-3D correspondences to estimate the pose (position and orientation) of an object.
-
Advanced Learning Architectures: Employing state-of-the-art convolutional neural networks (CNNs), such as ResNets and Inception Net, that are adept at learning hierarchical features, leading to better recognition in complex scenarios.
-
Ensemble Methods: Harnessing the collective wisdom of multiple models, which can be beneficial in addressing challenges such as lighting variations and partial occlusions.
-
Transfer Learning: Leveraging the knowledge acquired from pre-trained models on vast datasets to kick-start object recognition tasks. This can be instrumental in reducing the need for prohibitively large datasets for training.
Image pre-processing involves a series of techniques tailored to optimize images for computer vision tasks such as classification, object detection, and more.
-
Image Acquisition: Retrieving high-quality images from various sources, including cameras and databases.
-
Image Normalization: Standardizing image characteristics like scale, orientation, and color.
-
Noise Reduction: Strategies for minimizing noise or distorted information that affects image interpretation.
-
Image Enhancement: Techniques to improve visual quality and aid in feature extraction.
-
Image Segmentation: Dividing images into meaningful segments, simplifying their understanding.
-
Feature Extraction: Identifying and isolating critical features within an image.
-
Feature Selection: Streamlining models by pinpointing the most relevant features.
-
Data Splitting: Partitioning data into training, validation, and test sets.
-
Dimensionality Reduction: Techniques for lowering feature space dimensions, particularly valuable for computationally intensive models.
-
Image Compression: Strategies to reduce image storage and processing overheads.
Here is the Python code:
from sklearn.model_selection import train_test_split
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(images, labels, test_size=0.2, random_state=42)- Resizing: Compressing images to uniform dimensions.
- Filtering: Using various filters to highlight specific characteristics, such as edges.
- Binarization: Converting images to binary format based on pixel intensity, simplifying analysis.
- Thresholding: Dividing images into clear segments, often useful in object detection.
- Image Moments: Abstract data to describe various properties of image data, such as the center or orientation.
- Feature Detection: Automatically identifying and marking key points or structures, like corners or lines.
- Histogram Equalization: Improving image contrast by altering intensity distributions.
- ROI Identification: Locating regions of interest within images, helping focus computational resources where they're most needed.
-
Classification: Tasks images into predefined classes.
- Techniques: Center-cropping, mean subtraction, PCA color augmentation.
-
Object Detection: Identifies and locates objects within an image.
- Techniques: Resizing to anchor boxes, data augmentation.
-
Semantic Segmentation: Assigns segments of an image to categories.
- Techniques: Image resizing to match the model's input size, reprojection of results.
-
Instance Segmentation: Identifies object instances in an image while categorizing and locating pixels related to each individual object.
- Techniques: Scaling the image, padding to match network input size.
Image resizing has substantial implications for both computational efficiency and model performance in computer vision applications. Let's delve into the details.
Convolutional Neural Networks (CNNs) are the cornerstone of many computer vision models due to their ability to learn and detect features hierarchically.
- Computational Efficiency: Resizing reduces the number of operations. Fewer pixels mean a shallower network may suffice without losing visual context.
- Memory Management: Smaller images require less memory, often fitting within device constraints.
- Information Loss: Shrinking images discards fine-grained details crucial in image understanding.
- Sparse Receptive Field Coverage: Small input sizes can limit receptive fields, compromising global context understanding.
- Overfitting Risk: Extreme reductions can cause overfitting, especially with simpler models and limited data.
- Data Augmentation: Introduce image variations during training.
- Progressive Resizing: Start with smaller images, progressing to larger ones.
- Mixed Scaled Batches: Train using a mix of image scales in each batch.
Establishing an optimal input size involves considering computational constraints and the need for high-resolution feature learning.
For real-time applications, such as self-driving cars, quick diagnostic systems, or embedded devices, practicality often demands smaller image sizes. Conversely, for image-specific tasks where detailed information is crucial, such as in pathology or astronomical image analysis, larger sizes are essential.
Here is the Python code:
import cv2
# Load an image
image = cv2.imread('path_to_image.jpg')
# Resize to specific dimensions
resized_image = cv2.resize(image, (new_width, new_height))
# Display
cv2.imshow("Original Image", image)
cv2.imshow("Resized Image", resized_image)
cv2.waitKey(0)
cv2.destroyAllWindows()Image noise can disrupt visual information and hinder both human and machine perception. Employing effective noise reduction techniques can significantly improve the quality of images.
- Gaussian Noise: Results from the sum of many independent, tiny noise sources. Noise values follow a Gaussian distribution.
- Salt-and-Pepper Noise: Manifests as random white and black pixels in an image.
The median filter replaces the pixel value with the median of the adjacent pixels. This method is especially effective for salt-and-pepper noise.
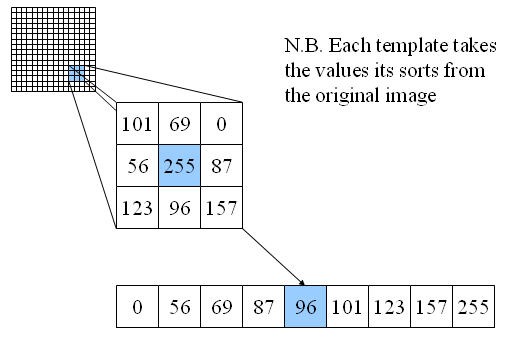
The Gaussian filter uses a weighted averaging mechanism, giving more weight to pixels closer to the center.
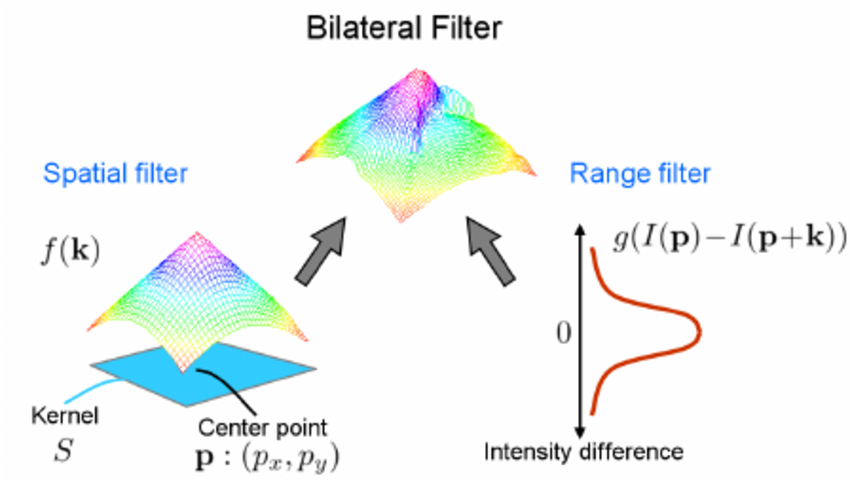
The bilateral filter also uses a weighted averaging technique, with two key distinctions: it considers spatial closeness and relative intensities.
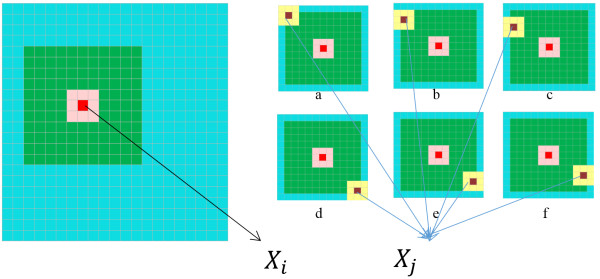
The NLM filter compares similarity between patches in an image to attenuate noise.
Here is the Python code:
import cv2
import matplotlib.pyplot as plt
# Read image and convert to grayscale
image = cv2.imread('noisy_image.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply different noise reduction filters
median_filtered = cv2.medianBlur(gray, 5)
gaussian_filtered = cv2.GaussianBlur(gray, (5, 5), 0)
bilateral_filtered = cv2.bilateralFilter(gray, 9, 75, 75)
# Display all images
plt.figure(figsize=(10, 5))
plt.subplot(2, 2, 1), plt.imshow(gray, cmap='gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(2, 2, 2), plt.imshow(median_filtered, cmap='gray')
plt.title('Median Filter'), plt.xticks([]), plt.yticks([])
plt.subplot(2, 2, 3), plt.imshow(gaussian_filtered, cmap='gray')
plt.title('Gaussian Filter'), plt.xticks([]), plt.yticks([])
plt.subplot(2, 2, 4), plt.imshow(bilateral_filtered, cmap='gray')
plt.title('Bilateral Filter'), plt.xticks([]), plt.yticks([])
plt.show()Image augmentation is a technique used to artificially enlarge a dataset by creating modified versions of the original images. It helps in improving the accuracy of computer vision models, especially in scenarios with limited or unbalanced data.
-
Improved Generalization: By exposing the model to a range of transformed images, it becomes better at recognizing and extracting features from the input data, making it more robust against variations.
-
Data Balancing: Augmentation techniques can be tailored to mitigate class imbalances, ensuring more fair and accurate predictions across different categories.
-
Reduced Overfitting: Diverse augmented data presents a variety of input patterns to the model, which can help in preventing the model from becoming overly specific to the training set, thereby reducing overfitting.
-
Geometric transformations: These include rotations, translations, flips, and scaling. For example, a slightly rotated or flipped image can still represent the same object.
-
Color and contrast variations: Introducing color variations, changes in brightness, and contrast simulates different lighting conditions, making the model more robust.
-
Noise addition: Adding random noise can help the model in handling noise present in real-world images.
-
Cutout and occlusions: Randomly removing patches of images or adding occlusions (e.g., a random black patch) can help in making the model more robust to occlusions.
-
Mixup and CutMix: Techniques like mixup and CutMix involve blending images from different classes to create more diverse training instances.
-
Grid Distortion: This advanced technique involves splitting the image into a grid and then perturbing the grid points to create the distorted image.
Here is the Python code:
from keras.preprocessing.image import ImageDataGenerator
# Initialize the generator with specific augmentation parameters
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
vertical_flip=True,
brightness_range=[0.8, 1.2],
shear_range=0.2,
zoom_range=0.2,
fill_mode='nearest')
# Apply the augmentation to an image
import numpy as np
from keras.preprocessing.image import load_img, img_to_array
import matplotlib.pyplot as plt
# Load an example image
img = load_img('path_to_image.jpg')
# Transform the image to a numpy array
data = img_to_array(img)
samples = np.expand_dims(data, 0)
# Create a grid of 10x10 augmented images
plt.figure(figsize=(10, 10))
for i in range(10):
for j in range(10):
# Generate batch of images
batch = datagen.flow(samples, batch_size=1)
# Convert to unsigned integers for viewing
image = batch[0].astype('uint8')
# Define subplot
plt.subplot(10, 10, i*10+j+1)
# Plot raw pixel data
plt.imshow(image[0])
# Show the plot
plt.show()Color spaces are mathematical representations designed for capturing and reproducing colors in digital media, such as images or video. They can have different characteristics, making them better suited for specific computational tasks.
-
Computational Efficiency: Certain color spaces expedite image analysis and algorithms like edge detection.
-
Human Perceptual Faithfulness: Some color spaces mimic the way human vision perceives color more accurately than others.
-
Device Independence: Color spaces assist in maintaining consistency when images are viewed on various devices like monitors and printers.
-
Channel Separation: Storing color information distinct from luminance can be beneficial. For example, in low-light photography, one may prioritize the brightness channel, avoiding the graininess inherent in the color channels.
-
Specialized Uses: Unique color representations are crafted explicitly for niche tasks such as skin tone detection in image processing.
By navigating between color spaces, tailored methods for each step of image processing can be implemented, leading to optimized visual results.
This is the basic color space for images on electronic displays. It defines colors in terms of how much red, green, and blue light they contain.
RGB is device-dependent and not human-intuitive.
- Hue: The dominant wavelength in the color (e.g., red, green, blue).
- Saturation: The "purity" of the color or its freedom from white.
- Value: The brightness of the color.
This color space is often used for segmenting object colors. For example, for extracting a specific colored object from an image.
This color system is specifically designed for use with printers. Colors are defined in terms of the amounts of cyan, magenta, yellow and black inks needed to reproduce them.
- C is for cyan
- M is for magenta
- Y is for yellow
- K is for black
This color space represents colors as a combination of a luminance (Y) channel and chrominance (Cb, Cr, or U, V in some variations) channels.
It's commonly used in image and video compression, as it separates the brightness information from the color information, allowing more efficient compression.
Several libraries and image processing tools offer mechanisms to convert between color spaces. For instance, OpenCV in Python provides the cvtColor() function for this purpose.
Here is the Python code:
import cv2
# Load the image
image = cv2.imread('path_to_image.jpg')
# Convert from BGR to RGB
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Convert from RGB to Grayscale
image_gray = cv2.cvtColor(image_rgb, cv2.COLOR_RGB2GRAY)
# Display the images
cv2.imshow('RGB Image', image_rgb)
cv2.imshow('Grayscale Image', image_gray)
# Close with key press
cv2.waitKey(0)
cv2.destroyAllWindows()In Computer Vision, Feature Descriptors provide a compact representation of the information within an image or an object. They are an essential element in many tasks, such as object recognition, image matching, and 3D reconstruction.
-
Identification: These descriptors help differentiate features (keypoints or interest points) from the background or other irrelevant points.
-
Invariance: They provide robustness against variations like rotation, scale, and illumination changes.
-
Localization: They offer spatial information that pinpoints the exact location of the feature within the image.
-
Matching: They enable efficient matching between features from different images.
-
Harris Corner Detector: Identifies key locations based on variations in intensity.
-
Shi-Tomasi Corner Detector: A refined version of the Harris Corner Detector.
-
SIFT (Scale-Invariant Feature Transform): Detects keypoints that are invariant to translation, rotation, and scale. SIFT is also a descriptor itself.
-
SURF (Speeded-Up Robust Features): A faster alternative to SIFT, also capable of detecting keypoints and describing them.
-
FAST (Features from Accelerated Segment Test): Used to detect keypoints, particularly helpful for real-time applications.
-
ORB (Oriented FAST and Rotated BRIEF): Combines the capabilities of FAST keypoint detection and optimized descriptor computation of BRIEF. It is also an open-source alternative to SIFT and SURF.
-
AKAZE (Accelerated-KAZE): Known for being faster than SIFT and able to operate under various conditions, such as viewpoint changes, significant background clutter, or occlusions.
-
BRISK (Binary Robust and Invariant Scalable Keypoints): Focuses on operating efficiently and providing robustness.
-
MSER (Maximally Stable Extremal Regions): Used for detecting regions that stand out in terms of stability across different views or scales. Stood out for its adaptability to various settings.
-
HOG (Histogram of Oriented Gradients): Brings in information from local intensity gradients, often used in conjunction with Machine Learning algorithms.
-
LBP (Local Binary Pattern): Another method for incorporating texture-related details into feature representation.
- SIFT: Combines orientation and magnitude histograms.
- SURF: Deploys a grid-based approach and features a speed boost by using Integral Images.
- BRIEF (Binary Robust Independent Elementary Features): Produces binary strings.
- ORB: Uses FAST for keypoint detection and deploys a modified version of BRIEF for descriptor generation.
Here is the Python code:
import cv2
import numpy as np
# Load the image in grayscale
image = cv2.imread('house.jpg', 0)
# Set minimum threshold for Harris corner detector
thresh = 10000
# Detect corners using Harris Corner Detector
corner_map = cv2.cornerHarris(image, 2, 3, 0.04)
# Mark the corners on the original image
image[corner_map > 0.01 * corner_map.max()] = [0, 0, 255]
# Display the image with corners
cv2.imshow('Harris Corner Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()Scale-Invariant Feature Transform (SIFT) is a widely-used method for keypoint detection and local feature extraction. It's robust to changes like scale, rotation, and illumination, making it effective for tasks such as object recognition, image stitching, and 3D reconstruction.
-
Scale-space Extrema Detection: Identify potential keypoints across multi-scale image pyramids to be robust to scale changes. The algorithm detects extrema in the DoG function.
-
Keypoint Localization: Refine the locations of keypoints using a Taylor series expansion, allowing for sub-pixel accuracy. This step also filters out low-contrast keypoints and poorly-localized ones.
-
Orientation Assignment: Assigns an orientation to each keypoint. This makes the keypoints invariant to image rotation.
-
Keypoint Descriptor: Compute a feature vector, referred to as the SIFT descriptor, which encodes the local image gradient information in keypoint neighborhoods. This step enables matching despite changes in viewpoint, lighting, or occlusion.
-
Descriptor Matching: Compares feature vectors among different images to establish correspondences.
While SIFT has long been a staple in the computer vision community, recent years have introduced alternative methods. For instance, convolutional neural networks (CNNs) are increasingly being used to learn discriminative image features, especially due to their effectiveness in large-scale, real-world applications.
Deep learning-based methods have shown superior performance in various tasks, challenging SIFT's historical dominance. The effectiveness of SIFT, however, endures in many scenarios, particularly in instances with smaller datasets or specific requirements for computational efficiency.
Here is the Python code:
# Import the required libraries
import cv2
# Load the image in grayscale
image = cv2.imread('image.jpg', 0)
# Create an SIFT object
sift = cv2.SIFT_create()
# Detect keypoints and descriptors
keypoints, descriptors = sift.detectAndCompute(image, None)
# Visualize the keypoints
image_with_keypoints = cv2.drawKeypoints(image, keypoints, None)
cv2.imshow('Image with Keypoints', image_with_keypoints)
cv2.waitKey(0)
cv2.destroyAllWindows()Explore all 54 answers here 👉 Devinterview.io - Computer Vision