Real Time User Search Query Analysis Using Spark Structured Streaming, Delta Lake and Amazon Kinesis
AMOD-5410 - Big Data
A client/company has developed their website and want to analyze and store their user's search query to analyze what users are looking for and generate daily reports which can help them to solve several business questions. This project will demonstrate how to use Spark Structured Streaming, Delta lake and Kinesis to store and analyze data in the best possible way. Additionally, we would also cover several Spark configurational details which is very important for writing an optimized code.
Apache Spark Structured Streaming
Delta Lake - Developed by Databricks
Amazon Kinesis DataStreams
AWS Glue - Data Catlog
AWS Kinesis Firehouse
AWS Kinesis DataStreams
AWS S3
Django - Python Web Devlopement Framework
This is the first architecture of our project. The various componenets of this architecture and the choice of those components is explained below:
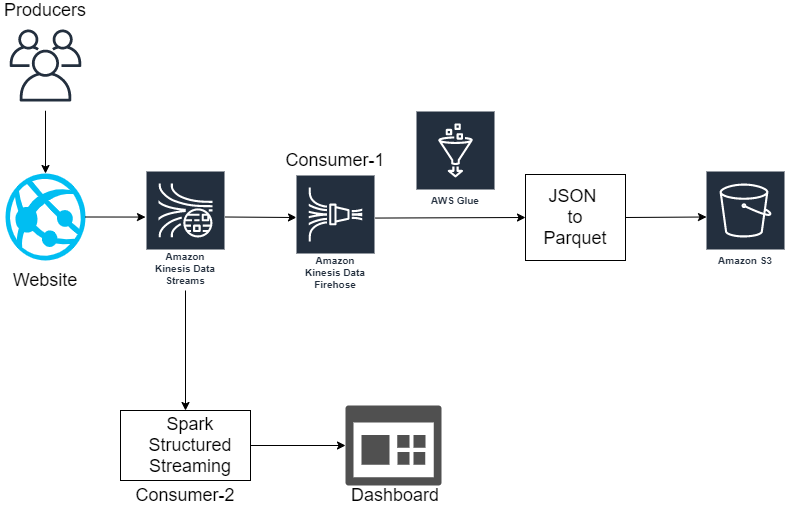
There is just one producer which is a website that is deployed on AWS EC2 instance and built using Django.

-> KDS can continuously capture gigabytes of data per second from hundreds of thousands of sources such as website clickstreams, database event streams, financial transactions, social media feeds, IT logs, and location-tracking events.
-> Shards: Currently we have used only one shard. (Shard is basically the base throughput unit of Kinesis. One shard provides a capacity of 1MB/sc data input and 2MB/sec data output. To get more throughput units we can initalize more shards.)
There are two consumers in out architecture. One is the Spark Structured Streaming Job and the other one is the Kinesis Firehose.
- Spark Structured Streaming Job - Perform transformations and aggregations for data analysis
- Kinesis Firehose
Let us suppose our streaming job is cancelled or a cluster is down due to any reason and we have multiple jobs running up. Example, one writestream() for storing records and another writestream which performs several queries for data analysis. Kinesis Firehose is the easiest way to reliably load streaming data into data lakes, data stores and analytics tools. Finally, this stored data into S3 in parquet format with defaault compression- Snappy
[https://docs.aws.amazon.com/firehose/latest/dev/record-format-conversion.html]
In big data world, we always want to store data in the most effective way. File formats like JSON/CSV are not recommended if we are using SparK Or Hive to perform analysis. Hence, in our case as we are dealing with Spark, we transform all records from JSON to Parquet format and store the data that is partitioned by Date. (ORC can be used when using Hive)
Configurations and code for Spark structured streaming will be covered in further sections.
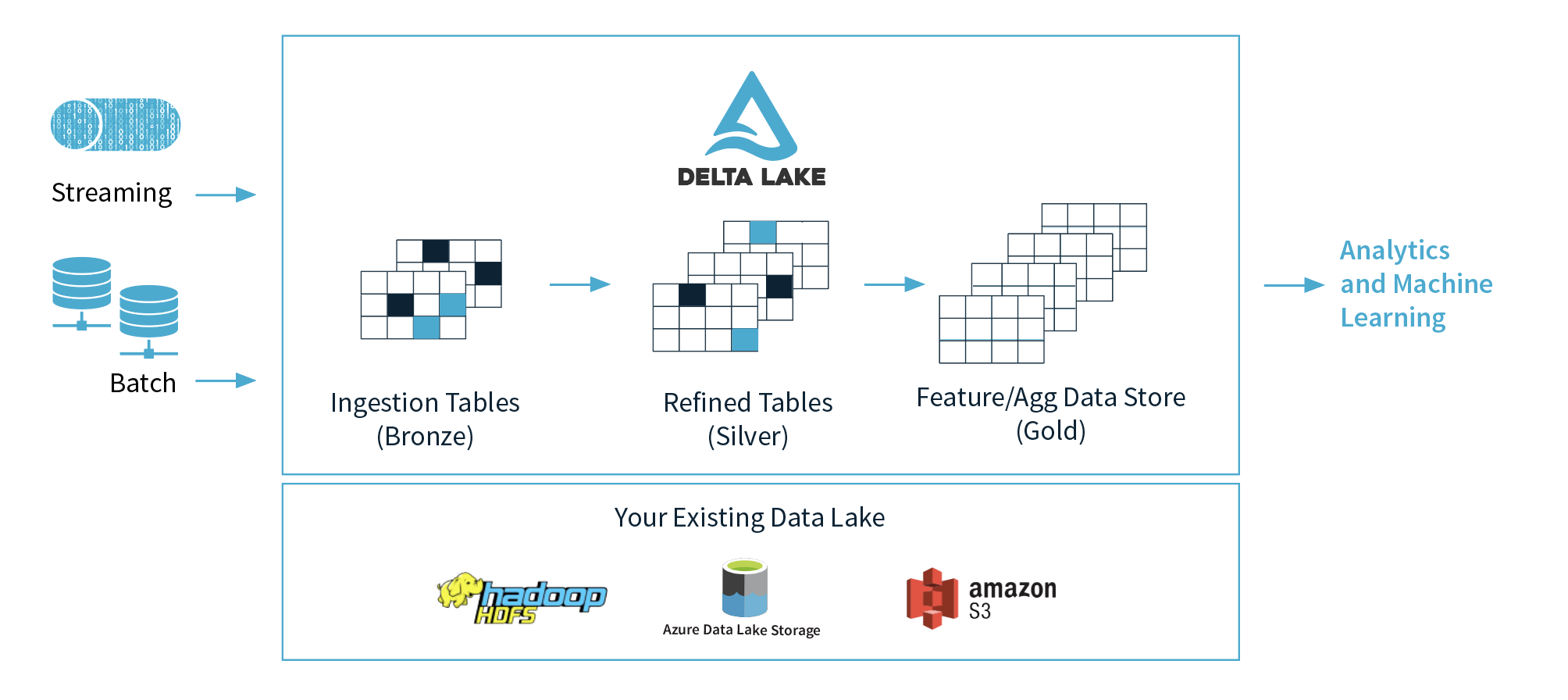
The most exciting and interesting Part of this project "Welcome to the world of Data Lakehouse - Delta Lake
- Schema enforcement when new tables are introduced.
- Table repairs when any new data is inserted into the data lake.
- Frequent refreshes of metadata.
- Bottlenecks of small file sizes for distributed computations.
- Difficulty re-sorting data by an index (i.e. userID) if data is spread across many files and partitioned by i.e. eventTime.
- First of all, it is 10-100x faster than spark on Parquet.
- ACID transactions - Multiple writers can simultaneously modify a data set and see consistent views.
- DELETES/UPDATES/UPSERTS - Writers can modify a data set without interfering with jobs reading the data set.
- Automatic file management - Data access speeds up by organizing data into large files that can be read efficiently.
- Statistics and data skipping - Reads are 10-100x faster when statistics are tracked about the data in each file, allowing Delta to avoid reading irrelevant information.
To overcome the limitations when using Data Lake(Amazon S3), we chose a different and a fairly new approcah. The architecture of that approach is given below:

OPTIMIZATION Mechanisms to speed up queries
Partition Pruning is a performance optimization that speeds up queries by limiting the amount of data read.
Data Skipping is a performance optimization that aims at speeding up queries that contain filters (WHERE clauses).
ZOrdering is a technique to colocate related information in the same set of files. ZOrdering maps multidimensional data to one dimension while preserving locality of the data points. Algorithm: [https://en.wikipedia.org/wiki/Z-order_curve]
.png)
Step 1: Clone this Github repository for getting code for website. [https://github.com/Aayushpatel007/Real-Time-User-Search-Analysis]
Step 2: Create a Kinesis stream on AWS with as many shards as you want according to your usecase.
Step 3: Create an AWS Secret access key and Access key from IAM. - My security credentials
Step 4. Configure aws-cli on your machine for storing aws credentials.
Step 5. Under views.py replace kinesis_stream variable and the region respectively.
Step 6. Optional = Create a Kinesis Firehose for the input source as "Kinesis Data Streams" and sink as "Amazon S3".
Step 7. Optional = Create a Glue table for transforming data to parquet/orc partitoned by "Date".
Step 8. Use the below Spark structured streaming code to analyze data.
Note: Instructions for setting up and using Delta lake is given below.
Before going through the code, the default number of partitions(sparks' default parallelism) = 8 needs to be changed. Hence for performance optimization, we can lower the number of partitions.
Too few partitions – Cannot utilize all cores available in the cluster.
Too many partitions – Excessive overhead in managing many small tasks.
sc.defaultParallelism
#spark.conf.set("spark.default.parallelism",2)
#We set default parallelism to "2" as there are two cores and we don't want to more than 2 partitions to avoid internal shuffle and
sort. Changing and adjusting this parameter can make a huge difference when there is a huge cluster. Also shuffle.partitons =200 , we can change that value to tune performance
kinesisDF = spark \
.readStream \
.format("kinesis") \
.option("streamName", "search-queries-ingestion") \
.option("initialPosition", "earliest") \
.option("region", "us-east-1") \
.option("awsAccessKey", "") \
.option("awsSecretKey", "") \
.load()
from pyspark.sql.types import *
from pyspark.sql.functions import *
pythonSchema = (StructType()
.add("Query", StringType())
.add("Timestamp", StringType())
.add("Name", StringType())
.add ("No_of_words", IntegerType())
.add ("Browser", StringType())
.add("Device", StringType())
.add ("Date", StringType()))
#If you want only one writestream which stores data in memory and then perform several queries on top of that table
"""
dataDF = (kinesisDF
.selectExpr("cast (data as STRING) jsonData")
.select(from_json("jsonData", pythonSchema).alias("data"))
.select("data.*")
.writeStream
.format("memory")
.outputMode("append")
.queryName("searchdata")
.start())
"""
If you want to see all incoming data from Kinesis stream - (Need to uncomment the code above with dataDF)
from time import sleep
while True:
spark.sql("SELECT * FROM searchdata").show()
sleep(2)
Max_queries_per_user = (kinesisDF.selectExpr("cast (data as STRING) jsonData")
.select(from_json("jsonData", pythonSchema).alias("data"))
.select("data.Name")
.groupBy("Name").count().sort(desc("count")).limit(5))
display(Max_queries_per_user)
Performing what "word" users searches the most. Note stop words have been removed before sending data from website using NLTK
words = (kinesisDF.selectExpr("cast (data as STRING) jsonData")
.select(from_json("jsonData", pythonSchema).alias("data"))
.select("data.Query")
.select(
#explode turns each item in an array into a separate row
explode(
split("Query", ' ')
).alias('word')))
#Generate a running word count
wordCounts = words.groupBy('word').count().sort(desc("count")).limit(10)
display(wordCounts)
#Generating Individual Report
User_report_df = (kinesisDF.selectExpr("cast (data as STRING) jsonData")
.select(from_json("jsonData", pythonSchema).alias("data"))
.select("data.Name")
.where("Name == aayush"))
no_of_queries = User_report_df.count()
avg_no_of_words_per_query = User_report_df.select(avg(User_report_df["No_of_words"]))
unique_browser = User_report_df.select("Browser").distinct()
unique_device = User_report_df.select("Device").distinct()
top_5_words = (User_report_df.select("data.Query")
.select(
#explode turns each item in an array into a separate row
explode(
split(lines.value, ' ')
).alias('word')) )
#Generate a running word count
wordCounts = top_5_words.groupBy('word').withColumnRenamed("count","distinct_words").sort(desc("count"))
print("No of queries:", no_of_queries)
Before starting implementation, we need to know the configuration setting and packages required to use delta lake.
S3 as a storage system:
bin/pyspark \
--packages io.delta:delta-core_2.11:0.2.0, \
org.apache.hadoop:hadoop-aws:2.7.7 \
--conf spark.delta.logStore.class=org.apache.spark.sql.delta.storage.S3SingleDriverLogStore \
--conf spark.hadoop.fs.s3a.access.key=<your-s3-access-key> \
--conf spark.hadoop.fs.s3a.secret.key=<your-s3-secret-key>
HDFS as a storage system:
spark.delta.logStore.class=org.apache.spark.sql.delta.storage.HDFSLogStore
Azure Data Lake Gen1 as a storage system
bin/spark-shell \
--packages io.delta:delta-core_2.11:0.2.0,org.apache.hadoop:hadoop-azure-datalake:2.9.2 \
--conf spark.delta.logStore.class=org.apache.spark.sql.delta.storage.AzureLogStore \
--conf spark.hadoop.dfs.adls.oauth2.access.token.provider.type=ClientCredential \
--conf spark.hadoop.dfs.adls.oauth2.client.id=<your-oauth2-client-id> \
--conf spark.hadoop.dfs.adls.oauth2.credential=<your-oauth2-credential> \
--conf spark.hadoop.dfs.adls.oauth2.refresh.url=https://login.microsoftonline.com/<your-directory-id>/oauth2/token
Path: /delta/events/_checkpoints/searchdata
If the job fails due to some reason, we don't have to read or write the data again.
from pyspark.sql.types import *
from pyspark.sql.functions import *
#ACCESS_KEY = dbutils.secrets.get(scope = "aws", key = "")
#SECRET_KEY = dbutils.secrets.get(scope = "aws", key = "")
sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", "")
sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", "")
pythonSchema = (StructType()
.add("Query", StringType())
.add("Timestamp", StringType())
.add("Name", StringType())
.add ("No_of_words", IntegerType())
.add ("Browser", StringType())
.add("Device", StringType())
.add ("Date", StringType()))
dataDevicesDF = (kinesisDF
.selectExpr("cast (data as STRING) jsonData")
.select(from_json("jsonData", pythonSchema).alias("data"))
.select("data.*")
.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/delta/events/_checkpoints/searchdata")
.start("/mnt/delta/data"))
#delta_stream = spark.readStream.format("delta").load("/mnt/delta/data")
#Now we can use the same code above to perform several analysis.