
开始的时候想复杂了,其实就是一个排序好的数组,把前边的若干的个数,一起移动到末尾就行了。然后在 log (n) 下找到给定数字的下标。
总的来说,log(n),我们肯定得用二分的方法了。
参考这里首先我们想一下变化前,正常的升序。我们怎么找给定的数字。

我们每次只关心中间位置的值(这一点很重要),也就是上图 3 位置的数值,如果 target 小于 3 位置的值,我们就把 3 4 5 6 抛弃。然后看新的中间的位置,也就是 1 位置的数值。 3 位置, 1 位置的值是多少呢?我们有一个数组。
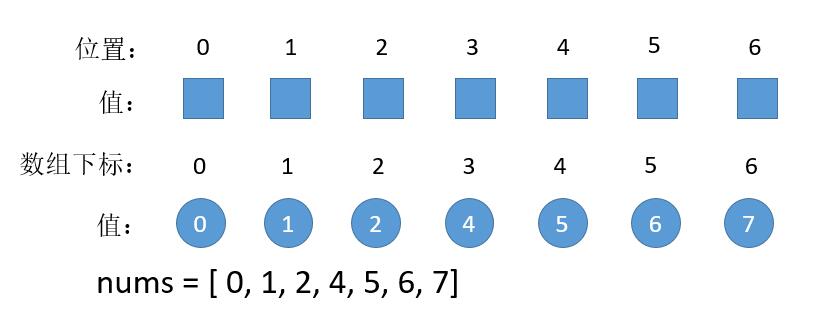
3 位置的值,刚好就是数组下标为 3 的值,1 位置的值刚好就是下标为 1 的值。
那么如果,按题目要求的,变化后,3 位置 和 1 位置的值怎么求呢? 此时我们的数组变成下边这样,我们依旧把值从小到大排列。
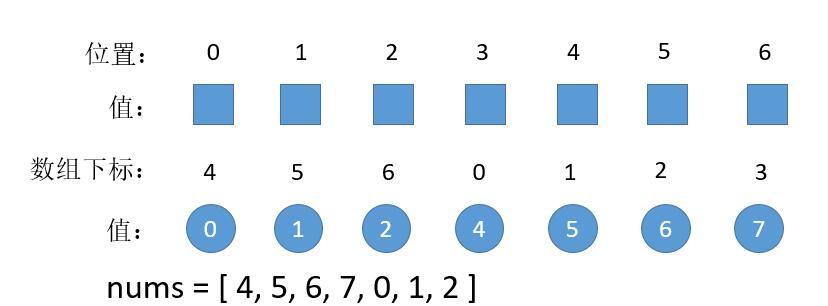
此时 3 位置的数值对应为数组下标是 0 的值,1 位置的值对应数组下标是 5 的值。任意位置的对应规则是什么呢?0 -> 4, 1 - > 5,4 ->1,就是就是 (位置 + 偏移 )% 数组的长度。这里就是加上 4 模 7。
问题转换为怎么去求出这个偏移。
我们只要知道任意一个位置对应的数组下标就可以了,为了方便我们可以求位置为 0 的值对应的下标(数组中最小的数对应的下标),0 位置对应的下标就是我们要求的偏移了(0 + 偏移 = 数组下标)。这里 nums = [ 4, 5, 6, 7, 0, 1, 2] ,我们就需要去求数值 0 的下标。
求最小值的下标,因为题目要求时间复杂度是 O(log ( n )),所以我们必须采取二分的方法去找,二分的方法就要保证每次比较后,去掉一半的元素。这里我们去比较中点和端点值的情况,那么是根据中点和起点比较,还是中点和终点比较呢?我们来分析下。
-
mid 和 start 比较
mid > start : 最小值在左半部分。
mid < start: 最小值在左半部分。
无论大于小于,最小值都在左半部分,所以 mid 和 start 比较是不可取的。
-
mid 和 end 比较
mid < end:最小值在左半部分。
mid > end:最小值在右半部分。
所以我们只需要把 mid 和 end 比较,mid < end 丢弃右半部分(更新 end = mid),mid > end 丢弃左半部分(更新 start = mid)。直到 end 等于 start 时候结束就可以了。

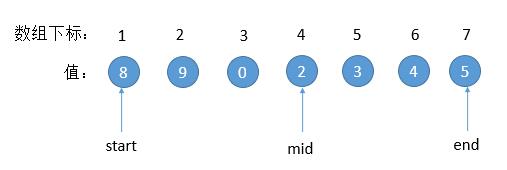
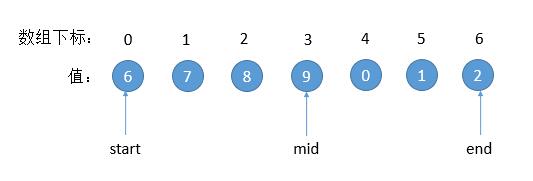
但这样会有一个问题的,对于下边的例子,就会遇到死循环了。
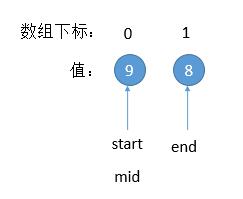
问题出在,当数组剩偶数长度的时候,mid = (start + end)/ 2,mid 取的是左端点。上图的例子, mid > end, 更新 start = mid,start 位置并不会变化。那么下一次 mid 的值也不会变,就死循环了。所以,我们要更新 start = mid + 1。
综上,找最小值的下标的代码就出来了,同时,由于我们找的是位置 0 对应的下标,所以偏移就是最小值的下标。
while (start < end) {
int mid = (start + end) / 2;
if (nums[mid] > nums[end]) {
start = mid + 1 ;
} else {
end = mid;
}
}
int bias = start;当然,我们是找最小值对应的下标,然后求出了偏移。我们也可以找最大值的对应的下标,分析思路和之前是一样的,主要还是要注意一下边界的情况,然后就可以求出偏移。
while (start < end) {
int mid = Math.round(((float)start + end) / 2);
if (nums[mid] < nums[start]) {
end = mid - 1;
} else {
start = mid;
}
}
int n = nums.length;
bias = (start + n) - (n - 1); //此时 start 是最大值的数组下标,加上模长 n,减去最大值的位置 n - 1 ,就得到了偏移。因为 (位置 + 偏移)% n = 数组下标,即 (n - 1 + 偏移)% n = start,n - 1 加偏移超过了 n,所以取模理解成减 n 。有了偏移,我们就可以愉快的找目标值的数组下标了。
public int search (int[] nums, int target) {
int start = 0;
int end = nums.length - 1;
//找出最小值的数组下标
/* while (start < end) {
int mid = (start + end) / 2;
if (nums[mid] > nums[end]) {
start = mid + 1 ;
} else {
end = mid;
}
}
int bias = start;*/
//找出最大值的数组下标
while (start < end) {
int mid = Math.round(((float)start + end) / 2);
if (nums[mid] < nums[start]) {
end = mid - 1;
} else {
start = mid;
}
}
int n = nums.length;
int bias = (start + n) - (n - 1); //得到偏移
start = 0;
end = nums.length - 1;
while (start <= end) {
int mid = (start + end) / 2;//中间的位置
int mid_change = (mid + bias) % nums.length;//中间的位置对应的数组下标
int value = nums[mid_change];//中间位置的值
if (target == value) {
return mid_change;
}
if (target < value) {
end = mid - 1;
} else {
start = mid + 1;
}
}
return -1;
}时间复杂度:O(log(n))。
空间复杂度:O(1)。
参考这里,题目中的数组,其实是两段有序的数组。例如
[ 4 5 6 7 1 2 3 ] ,[ 4 5 6 7 ] 和 [ 1 2 3 ] 两段有序。
而对于 [ 1 2 3 4] 这种,可以看做 [ 1 2 3 4 ] 和 [ ] 特殊的两段有序。
而对于我们要找的 target , target 不在的那一段,所有数字可以看做无穷大,这样整个数组就可以看做有序的了,可以用正常的二分法去找 target 了,例如
[ 4 5 6 7 1 2 3] ,如果 target = 5,那么数组可以看做 [ 4 5 6 7 inf inf inf ]。
[ 4 5 6 7 1 2 3] ,如果 target = 2,那么数组可以看做 [ -inf -inf - inf -inf 1 2 3]。
和解法一一样,我们每次只关心 mid 的值,所以 mid 要么就是 nums [ mid ],要么就是 inf 或者 -inf。
什么时候是 nums [ mid ] 呢?
当 nums [ mid ] 和 target 在同一段里边。
-
怎么判断 nums [ mid ] 和 target 在同一段?
把 nums [ mid ] 和 target 同时与 nums [ 0 ] 比较,如果它俩都大于 nums [ 0 ] 或者都小于 nums [ 0 ],那么就代表它俩在同一段。例如
[ 4 5 6 7 1 2 3],如果 target = 5,此时数组看做 [ 4 5 6 7 inf inf inf ]。nums [ mid ] = 7,target > nums [ 0 ],nums [ mid ] > nums [ 0 ],所以它们在同一段 nums [ mid ] = 7,不用变化。
-
怎么判断 nums [ mid ] 和 target 不在同一段?
把 nums [ mid ] 和 target 同时与 nums [ 0 ] 比较,如果它俩一个大于 nums [ 0 ] 一个小于 nums [ 0 ],那么就代表它俩不在同一段。例如
[ 4 5 6 7 1 2 3],如果 target = 2,此时数组看做 [ - inf - inf - inf - inf 1 2 3]。nums [ mid ] = 7,target < nums [ 0 ],nums [ mid ] > nums [ 0 ],一个大于,一个小于,所以它们不在同一段 nums [ mid ] = - inf,变成了负无穷大。
看下代码吧
public int search(int[] nums, int target) {
int lo = 0, hi = nums.length - 1;
while (lo <= hi) {
int mid = lo + (hi - lo) / 2;
int num = nums[mid];
//nums [ mid ] 和 target 在同一段
if ((nums[mid] < nums[0]) == (target < nums[0])) {
num = nums[mid];
//nums [ mid ] 和 target 不在同一段,同时还要考虑下变成 -inf 还是 inf。
} else {
num = target < nums[0] ? Integer.MIN_VALUE : Integer.MAX_VALUE;
}
if (num < target)
lo = mid + 1;
else if (num > target)
hi = mid - 1;
else
return mid;
}
return -1;
}时间复杂度:O(log(n))。
空间复杂度:O(1)。
参考这里,算法基于一个事实,数组从任意位置劈开后,至少有一半是有序的,什么意思呢?
比如 [ 4 5 6 7 1 2 3] ,从 7 劈开,左边是 [ 4 5 6 7] 右边是 [ 7 1 2 3],左边是有序的。
基于这个事实。
我们可以先找到哪一段是有序的 (只要判断端点即可),然后看 target 在不在这一段里,如果在,那么就把另一半丢弃。如果不在,那么就把这一段丢弃。
public int search(int[] nums, int target) {
int start = 0;
int end = nums.length - 1;
while (start <= end) {
int mid = (start + end) / 2;
if (target == nums[mid]) {
return mid;
}
//左半段是有序的
if (nums[start] <= nums[mid]) {
//target 在这段里
if (target >= nums[start] && target < nums[mid]) {
end = mid - 1;
} else {
start = mid + 1;
}
//右半段是有序的
} else {
if (target > nums[mid] && target <= nums[end]) {
start = mid + 1;
} else {
end = mid - 1;
}
}
}
return -1;
}时间复杂度:O(log(n))。
空间复杂度:O(1)。
三种解法是从不同的思路去理解题意,但本质上都是找到丢弃一半的规则,从而达到 log (n) 的时间复杂度,对二分查找的本质的理解更加深刻了。