[TOC]
阻塞与非阻塞是描述进程在访问某个资源时,数据是否准备就绪的的一种处理方式。当数据没有准备就绪时:
- 阻塞:线程持续等待资源中数据准备完成,直到返回响应结果。
- 非阻塞:线程直接返回结果,不会持续等待资源准备数据结束后才响应结果。
- 同步与异步是指访问数据的机制,同步一般指主动请求并等待IO操作完成的方式。
- 异步则指主动请求数据后便可以继续处理其它任务,随后等待IO操作完毕的通知。
老王烧开水: 1、普通水壶煮水,站在旁边,主动的看水开了没有?同步的阻塞 2、普通水壶煮水,去干点别的事,每过一段时间去看看水开了没有,水没开就走人。 同步非阻塞 3、响水壶煮水,站在旁边,不会每过一段时间主动看水开了没有。如果水开了,水壶自动通知他。 异步阻塞 4、响水壶煮水,去干点别的事,如果水开了,水壶自动通知他。异步非阻塞
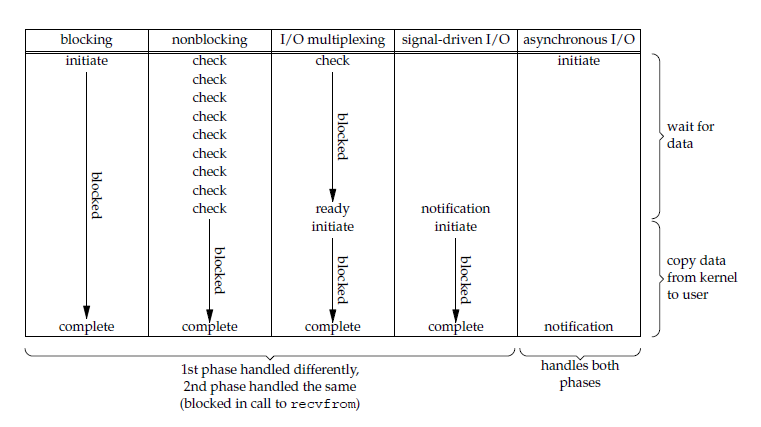
一个输入操作通常包括两个阶段:
- 等待数据准备好
- 从内核向进程复制数据
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待数据到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
Unix 有五种 I/O 模型:
- 阻塞式 I/O
- 非阻塞式 I/O
- I/O 复用(select 和 poll)
- 信号驱动式 I/O(SIGIO)
- 异步 I/O(AIO)
应用进程被阻塞,直到数据从内核缓冲区复制到应用进程缓冲区中才返回。
应该注意到,在阻塞的过程中,其它应用进程还可以执行,因此阻塞不意味着整个操作系统都被阻塞。因为其它应用进程还可以执行,所以不消耗 CPU 时间,这种模型的 CPU 利用率会比较高。
下图中,recvfrom() 用于接收 Socket 传来的数据,并复制到应用进程的缓冲区 buf 中。这里把 recvfrom() 当成系统调用。
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);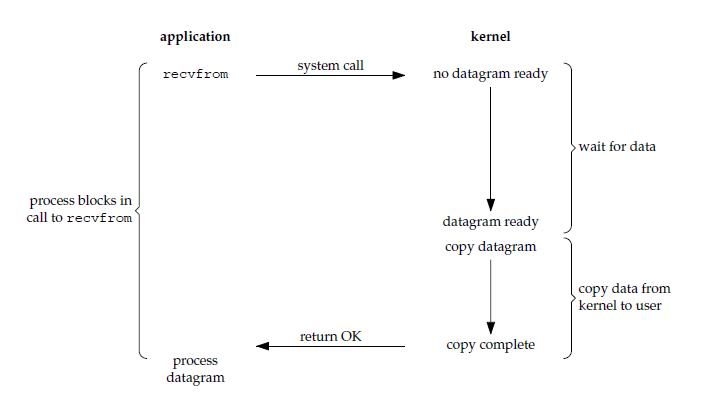
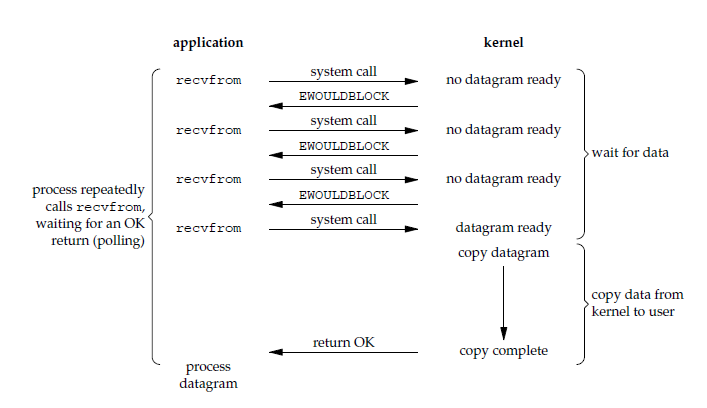
应用进程执行系统调用之后,内核返回一个错误码。应用进程可以继续执行,但是需要不断的执行系统调用来获知 I/O 是否完成,这种方式称为轮询(polling)。
由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低。
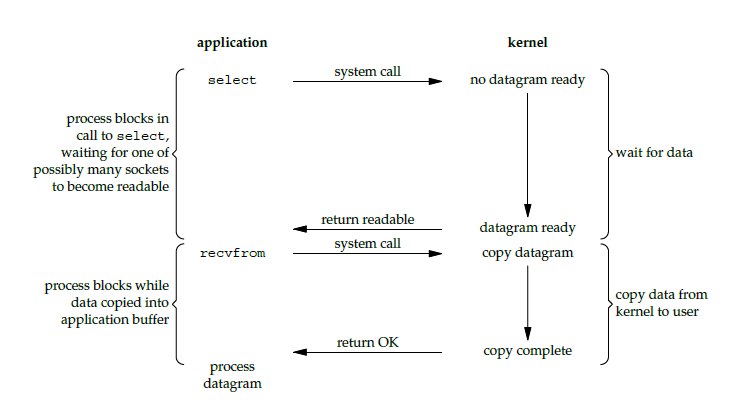
使用 select 或者 poll 等待数据,并且可以等待多个套接字中的任何一个变为可读。这一过程会被阻塞,当某一个套接字可读时返回,之后再使用 recvfrom 把数据从内核复制到进程中。
它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven I/O,即事件驱动 I/O。
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小。
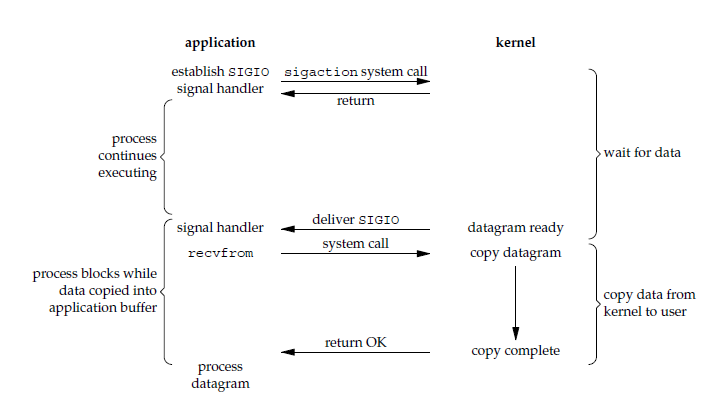
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中。
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。
应用进程执行 aio_read 系统调用会立即返回,应用进程可以继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。
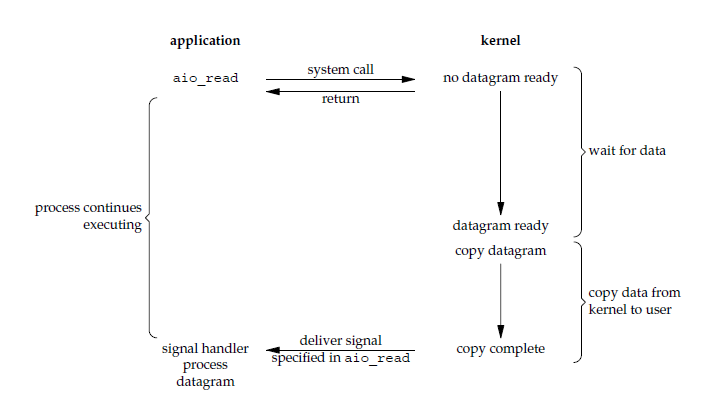
- 同步 I/O:将数据从内核缓冲区复制到应用进程缓冲区的阶段(第二阶段),应用进程会阻塞。
- 异步 I/O:第二阶段应用进程不会阻塞。
同步 I/O 包括阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O ,它们的主要区别在第一个阶段。
非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞。
select/poll/epoll 都是 I/O 多路复用的具体实现,select 出现的最早,之后是 poll,再是 epoll。
文件描述符,当应用程序请求内核打开/新建一个文件时,内核会返回一个文件描述符用于对应这个打开/新建的文件,其fd本质上就是一个非负整数,读写文件也是需要使用这个文件描述符来指定待读写的文件
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);select 允许应用程序监视一组文件描述符,等待一个或者多个描述符成为就绪状态,从而完成 I/O 操作。
-
fd_set 使用数组实现,数组大小使用 FD_SETSIZE 定义,所以只能监听少于 FD_SETSIZE 数量的描述符。有三种类型的描述符类型:readset、writeset、exceptset,分别对应读、写、异常条件的描述符集合。
-
timeout 为超时参数,调用 select 会一直阻塞直到有描述符的事件到达或者等待的时间超过 timeout。
-
成功调用返回结果大于 0,出错返回结果为 -1,超时返回结果为 0。
fd_set fd_in, fd_out;
struct timeval tv;
// Reset the sets
FD_ZERO( &fd_in );
FD_ZERO( &fd_out );
// Monitor sock1 for input events
FD_SET( sock1, &fd_in );
// Monitor sock2 for output events
FD_SET( sock2, &fd_out );
// Find out which socket has the largest numeric value as select requires it
int largest_sock = sock1 > sock2 ? sock1 : sock2;
// Wait up to 10 seconds
tv.tv_sec = 10;
tv.tv_usec = 0;
// Call the select
int ret = select( largest_sock + 1, &fd_in, &fd_out, NULL, &tv );
// Check if select actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
if ( FD_ISSET( sock1, &fd_in ) )
// input event on sock1
if ( FD_ISSET( sock2, &fd_out ) )
// output event on sock2
}int poll(struct pollfd *fds, unsigned int nfds, int timeout);poll 的功能与 select 类似,也是等待一组描述符中的一个成为就绪状态。
poll 中的描述符是 pollfd 类型的数组,pollfd 的定义如下:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};// The structure for two events
struct pollfd fds[2];
// Monitor sock1 for input
fds[0].fd = sock1;
fds[0].events = POLLIN;
// Monitor sock2 for output
fds[1].fd = sock2;
fds[1].events = POLLOUT;
// Wait 10 seconds
int ret = poll( &fds, 2, 10000 );
// Check if poll actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
// If we detect the event, zero it out so we can reuse the structure
if ( fds[0].revents & POLLIN )
fds[0].revents = 0;
// input event on sock1
if ( fds[1].revents & POLLOUT )
fds[1].revents = 0;
// output event on sock2
}select 和 poll 的功能基本相同,不过在一些实现细节上有所不同。
- select 会修改描述符,而 poll 不会;
- select 的描述符类型使用数组实现,FD_SETSIZE 大小默认为 1024,因此默认只能监听少于 1024 个描述符。如果要监听更多描述符的话,需要修改 FD_SETSIZE 之后重新编译;而 poll 没有描述符数量的限制;
- poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高。
- 如果一个线程对某个描述符调用了 select 或者 poll,另一个线程关闭了该描述符,会导致调用结果不确定。
select 和 poll 速度都比较慢,每次调用都需要将全部描述符从应用进程缓冲区复制到内核缓冲区。
几乎所有的系统都支持 select,但是只有比较新的系统支持 poll。
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);epoll_ctl() 用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,通过回调函数内核会将 I/O 准备好的描述符加入到一个链表中管理,进程调用 epoll_wait() 便可以得到事件完成的描述符。
从上面的描述可以看出,epoll 只需要将描述符从进程缓冲区向内核缓冲区拷贝一次,并且进程不需要通过轮询来获得事件完成的描述符。
epoll 仅适用于 Linux OS。
epoll 比 select 和 poll 更加灵活而且没有描述符数量限制。
epoll 对多线程编程更有友好,一个线程调用了 epoll_wait() 另一个线程关闭了同一个描述符也不会产生像 select 和 poll 的不确定情况。
// Create the epoll descriptor. Only one is needed per app, and is used to monitor all sockets.
// The function argument is ignored (it was not before, but now it is), so put your favorite number here
int pollingfd = epoll_create( 0xCAFE );
if ( pollingfd < 0 )
// report error
// Initialize the epoll structure in case more members are added in future
struct epoll_event ev = { 0 };
// Associate the connection class instance with the event. You can associate anything
// you want, epoll does not use this information. We store a connection class pointer, pConnection1
ev.data.ptr = pConnection1;
// Monitor for input, and do not automatically rearm the descriptor after the event
ev.events = EPOLLIN | EPOLLONESHOT;
// Add the descriptor into the monitoring list. We can do it even if another thread is
// waiting in epoll_wait - the descriptor will be properly added
if ( epoll_ctl( epollfd, EPOLL_CTL_ADD, pConnection1->getSocket(), &ev ) != 0 )
// report error
// Wait for up to 20 events (assuming we have added maybe 200 sockets before that it may happen)
struct epoll_event pevents[ 20 ];
// Wait for 10 seconds, and retrieve less than 20 epoll_event and store them into epoll_event array
int ready = epoll_wait( pollingfd, pevents, 20, 10000 );
// Check if epoll actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
// Check if any events detected
for ( int i = 0; i < ret; i++ )
{
if ( pevents[i].events & EPOLLIN )
{
// Get back our connection pointer
Connection * c = (Connection*) pevents[i].data.ptr;
c->handleReadEvent();
}
}
}epoll 的描述符事件有两种触发模式:LT(level trigger)和 ET(edge trigger)。
当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程。是默认的一种模式,并且同时支持 Blocking 和 No-Blocking。
和 LT 模式不同的是,通知之后进程必须立即处理事件,下次再调用 epoll_wait() 时不会再得到事件到达的通知。
很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。只支持 No-Blocking,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
很容易产生一种错觉认为只要用 epoll 就可以了,select 和 poll 都已经过时了,其实它们都有各自的使用场景。
select 的 timeout 参数精度为微秒,而 poll 和 epoll 为毫秒,因此 select 更加适用于实时性要求比较高的场景,比如核反应堆的控制。
select 可移植性更好,几乎被所有主流平台所支持。
poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select。
只需要运行在 Linux 平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接。
需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势。
需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内核,不容易调试。
传统BIO是一种同步的阻塞IO,IO在进行读写时,该线程将被阻塞,线程无法进行其它操作。 IO流在读取时,会阻塞。直到发生以下情况:1、有数据可以读取。2、数据读取完成。3、发生异常
以传统BIO模型为基础,通过线程池的方式维护所有的IO线程,实现相对高效的线程开销及管理。
NIO(JDK1.4)模型是一种同步非阻塞IO,主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector(多路复用器)。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(多路复用器)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。 NIO和传统IO(一下简称IO)之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
- 通过Channel注册到Selector上的状态来实现一种客户端与服务端的通信。
- Channel中数据的读取是通过Buffer , 一种非阻塞的读取方式。
- Selector 多路复用器 单线程模型, 线程的资源开销相对比较小。
传统IO操作对read()或write()方法的调用,可能会因为没有数据可读/可写而阻塞,直到有数据响应。也就是说读写数据的IO调用,可能会无限期的阻塞等待,效率依赖网络传输的速度。最重要的是在调用一个方法前,无法知道是否会被阻塞。
NIO的Channel抽象了一个重要特征就是可以通过配置它的阻塞行为,来实现非阻塞式的通道。
Channel是一个双向通道,与传统IO操作只允许单向的读写不同的是,NIO的Channel允许在一个通道上进行读和写的操作。
FileChannel:文件
SocketChannel:
ServerSocketChannel:
DatagramChannel: UDP
Bufer顾名思义,它是一个缓冲区,实际上是一个容器,一个连续数组。Channel提供从文件、网络读取数据的渠道,但是读写的数据都必须经过Buffer。

Buffer缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该模块内存。为了理解Buffer的工作原理,需要熟悉它的三个属性:capacity、position和limit。
position和limit的含义取决于Buffer处在读模式还是写模式。不管Buffer处在什么模式,capacity的含义总是一样的。见下图:

-
capacity:作为一个内存块,Buffer有固定的大小值,也叫作“capacity”,只能往其中写入capacity个byte、long、char等类型。一旦Buffer满了,需要将其清空(通过读数据或者清楚数据)才能继续写数据。
-
position:当你写数据到Buffer中时,position表示当前的位置。初始的position值为0,当写入一个字节数据到Buffer中后,position会向前移动到下一个可插入数据的Buffer单元。position最大可为capacity-1。当读取数据时,也是从某个特定位置读,讲Buffer从写模式切换到读模式,position会被重置为0。当从Buffer的position处读取一个字节数据后,position向前移动到下一个可读的位置。
-
limit:在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。 写模式下,limit等于Buffer的capacity。当切换Buffer到读模式时, limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值在写模式下就是position。
对Buffer对象的操作必须首先进行分配,Buffer提供一个allocate(int capacity)方法分配一个指定字节大小的对象。 向Buffer中写数据:写数据到Buffer中有两种方式: 1.从channel写到Buffer
int bytes = channel.read(buf); //将channel中的数据读取到buf中2.通过Buffer的put()方法写到Buffer
buf.put(byte); //将数据通过put()方法写入到buf中- flip()方法:将Buffer从写模式切换到读模式,调用flip()方法会将position设置为0,并将limit设置为之前的position的值。
从Buffer中读数据:从Buffer中读数据有两种方式:
1.从Buffer读取数据到Channel
int bytes = channel.write(buf); //将buf中的数据读取到channel中2.通过Buffer的get()方法读取数据
byte bt = buf.get(); //从buf中读取一个byte- rewind()方法:Buffer.rewind()方法将position设置为0,使得可以重读Buffer中的所有数据,limit保持不变。
- clear()与compact()方法:一旦读完Buffer中的数据,需要让Buffer准备好再次被写入,可以通过clear()或compact()方法完成。如果调用的是clear()方法,position将被设置为0,limit设置为capacity的值。但是Buffer并未被清空,只是通过这些标记告诉我们可以从哪里开始往Buffer中写入多少数据。如果Buffer中还有一些未读的数据,调用clear()方法将被"遗忘 "。compact()方法将所有未读的数据拷贝到Buffer起始处,然后将position设置到最后一个未读元素的后面,limit属性依然设置为capacity。可以使得Buffer中的未读数据还可以在后续中被使用。
- mark()与reset()方法:通过调用Buffer.mark()方法可以标记一个特定的position,之后可以通过调用Buffer.reset()恢复到这个position上。
Selector与Channel是相互配合使用的,将Channel注册在Selector上之后,才可以正确的使用Selector,但此时Channel必须为非阻塞模式。Selector可以监听Channel的四种状态(Connect、Accept、Read、Write),当监听到某一Channel的某个状态时,才允许对Channel进行相应的操作。
- Connect:某一个客户端连接成功后
- Accept:准备好进行连接s
- Read:可读
- Write:可写
- Stevens W R, Fenner B, Rudoff A M. UNIX network programming[M]. Addison-Wesley Professional, 2004.
- http://man7.org/linux/man-pages/man2/select.2.html
- http://man7.org/linux/man-pages/man2/poll.2.html
- Boost application performance using asynchronous I/O
- Synchronous and Asynchronous I/O
- Linux IO 模式及 select、poll、epoll 详解
- poll vs select vs event-based
- select / poll / epoll: practical difference for system architects
- Browse the source code of userspace/glibc/sysdeps/unix/sysv/linux/ online
- 林亚希
- CS-Notes