In recent years, with the revival of the concept of "artificial intelligence", in addition to the hot term "deep learning", "knowledge graph" is undoubtedly another "silver bullet" in the eyes of researchers, industry and investors. To put it simply, "knowledge Graph" is a data model that displays "entities", "attributes" and "relationships" among entities in the form of Graph. Below is an example from Google's knowledge Graph introduction page. There are four entities in the example, "Da Vinci", "Italian", "Monlarissa" and "Michelangelo". This diagram clearly shows the individual attributes and attribute values of "Da Vinci" (e.g., name, date of birth, time of death, etc.) as well as the relationships between them (e.g., Monlarissa is a painting by Da Vinci, Da Vinci was born in Italy, etc.).

At present, the knowledge graph generally uses RDF(Resource Description Framework) model in semantic Web Framework to represent data. The Semantic Web is a concept proposed by Tim Berners-Lee, the father of the World Wide Web, in 1998. Its core is to build a data-centric network, namely the Web of Data. RDF is the standard for data description in the SEMANTIC Web framework of W3C. It is often called RDF triples (Subject, predicate, object). Where the principal must be a described resource, represented by a URI. A predicate can represent an attribute of a subject or a relationship between a subject and an object. When representing an attribute, the object is the attribute value, usually a literal. Otherwise the object is another resource represented by a URI. The figure below shows a knowledge graph dataset for RDF triples of a people encyclopedia. For example: y Abraham_Lincoln said an entity URI prefix (y = http://en.wikipedia.org/wiki/), it has three properties (hasName, BornOdate DiedOnDate) and a relationship (DiedIn).
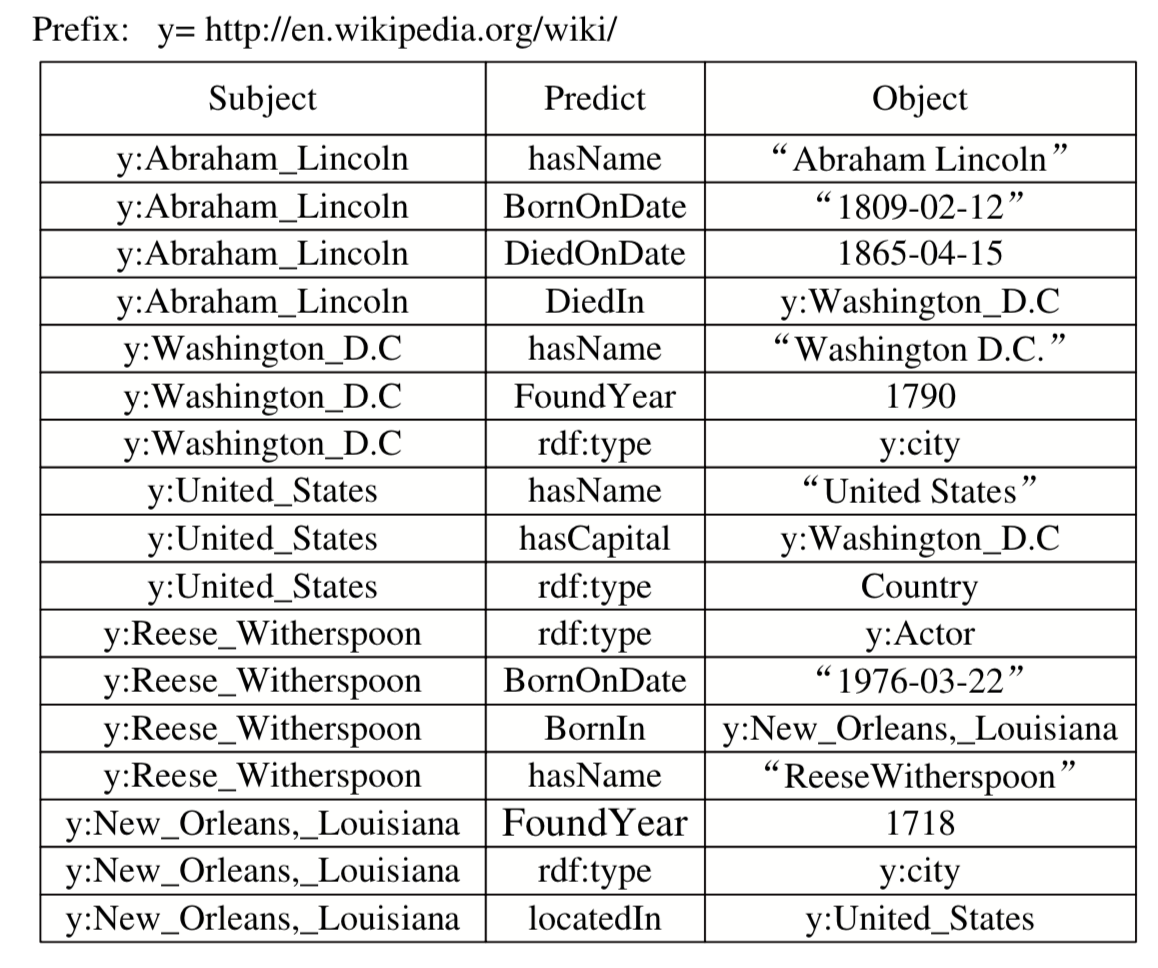
For RDF data set, W3C proposes a structured query language SPARQL. It is similar to SQL, the query language for relational databases. Like SQL, SPARQL is also a descriptive structured query language. That is, users only need to describe the information they want to query according to the syntax rules defined by SPARQL, without specifying the steps of the computer to perform the query. SPARQL became an official W3C standard in January 2008. The WHERE clause in SPARQL defines the query criteria, which are also represented by triples. We do not cover much syntax detail, but interested readers may refer to [1]. The following example illustrates the SPARQL language. Suppose we need to query the RDF data above for "the name of a person born on February 12, 1809 and who died on April 15, 1865?" This query can be represented as a SPARQL statement as shown below. The figure below shows a knowledge graph dataset for RDF triples of a people encyclopedia. For example: y Abraham_Lincoln said an entity URI prefix (y = http://en.wikipedia.org/wiki/), it has three properties (hasName, BornOdate DiedOnDate) and a relationship (DiedIn).
SELECT ?name
WHERE
{
?m <hasName> ?name.
?m <BornOnDate> "1809-02-12".
?m <DiedOnDate> "1865-04-15".
} A core problem of knowledge graph data management is how to efficiently store RDF datasets and quickly answer SPARQL queries. In general, there are two completely different sets of thinking. First, we can use existing mature database management systems (such as relational database systems) to store knowledge graph data. SPARQL queries oriented to RDF knowledge graph can be converted into queries oriented to such mature database management systems, such as SQL queries oriented to relational databases. Use existing relational database products or related technologies to answer queries. The core research problem is how to build relational tables to store RDF knowledge graph data and make the transformed SQL query statement query performance higher. The other is to directly develop a knowledge graph data storage and query system (Native RDF graph database system) for RDF knowledge graph data. Considering the characteristics of RDF knowledge graph management, optimization is carried out from the bottom of the database system.
The gStore system developed by us belongs to the latter. gStore is an open source graph database system (commonly known as Triple Store) for RDF data model developed by data Management Laboratory (PKUMOD) of Wangxuan Institute of Computer Technology of Peking University after ten years. Different from traditional relational database based knowledge graph data management method , gStore Native Graph Model, maintains the Graph structure of the original RDF knowledge graph; Its data model is labeled, directed polygon graph, each vertex corresponds to a subject or object. We convert SPARQL queries for RDF to ** Subgraph matching queries for RDF graphs, the graph structure-based index (VS-tree) proposed by us is used to speed up query performance. Figure 1-3 shows the structure of the RDF graph and SPARQL query graph corresponding to the above example. Answering SPARQL queries is essentially finding the matching position of the subgraph of a SPARQL query graph in an RDF graph, which is the theoretical basis of answering SPARQL queries based on graph databases. In the example in Figure 1-3, the subgraph derived from nodes 005,009,010 and 011 is a match of the query graph, from which it is easy to know that the SPARQL query result is "Abraham Lincoln." For the core academic ideas of gStore, please refer to the published papers of Development Resources - Papers and Patents.
gStore begin withdata Management Laboratory (PKUMOD) of Wangxuan Institute of Computer Technology of Peking University (Lei Zou, Jinghui Mo, Lei Chen,M. Tamer Ozsu, Dongyan Zhao, gStore: Answering SPARQL Queries Via Subgraph Matching, Proc. VLDB 4(8): 482-493, 2011), VLDB 2011 paper by Prof. Lei Zou, Prof. Tamer Ozsu, University of Waterloo, and Prof. Lei Chen, Hong Kong University of Science and Technology , proposes a query execution scheme using subgraph matching to answer Basic Graph Pattern (BGP) statements in SPARQL. Since the publication of this paper, PKUMOD Laboratory has been continuously engaged in the open source, maintenance and system optimization of gStore system under the funding of the National Natural Science Foundation of China and the key RESEARCH and development projects of the Ministry of Science and Technology of China. At present, the open source gStore system on Github can support SPARQL 1.1 standard defined by W3C (see SPARQL Query Language for details).
After a series of tests, the results showed that gStore was faster than other database systems at answering complex queries (for example, containing circles). For simple queries, gStore and other database systems work fine. The standalone version of gStore can support more than 5 billion RDF triples and SPARQL queries. The distributed system gStore (distributed version, not open source at present) has very good scalability. According to the test report given by "China Software Evaluation Center", The distributed gStore system has second query times on ten billion RDF triplet datasets.
Since the gStore system was opened on Github, BSD 3-clause, which is widely used in the open source community, has been adopted to promote the construction of gStore related knowledge graph technology ecology. According to this agreement, we require users to allow users to modify and redistribute codes freely on the premise of fully respecting the copyright of code authors, and also allow users to develop, distribute and sell commercial software freely on the basis of gStore codes. However, the above conditions must meet the relevant legal provisions stipulated in Chapter 10 "Legal Provisions" according to the BSD 3-clause open source agreement. We strictly require users to mark "powered by gStore" and the gStore logo (see gStore Logo for details) on the software they distribute based on the gStore code. We strongly recommend that users refer to the "Open Source and Legal Provisions" before using gStore.