原文:How JavaScript works: an overview of the engine, the runtime, and the call stack
译者:neal1991
welcome to star my articles-translator, providing you advanced articles translation. Any suggestion, please issue or contact me
LICENSE: MIT
随着 JavaScript 变得越来越流行,团队在多个层级都对它进行利用-前端,后端,混合应用,嵌入式设备以及更多。
正如 GitHut stats 所展示的那样,JavaScript 是 Github 上面最活跃以及总 Push 次数最多的语言。在其它类别中也不会落后太多。

(获取最新的 GitHub language stats).
如果项目对于 JavaScript越来越依赖,这意味着为了构建好的软件开发者必须利用这个 JS 提供的一切并且对于生态系统的内部有着更深的理解。
因此,尽管每天有很多开发者在使用 JavaScript,但并不知道内部到底发生了什么。
几乎每个人都已经听说过V8引擎的概念,并且很多知道 JavaScript 是单线程的或者它是使用一个回调队列的。
在这篇博文中,我们将会详细讲述所有概念并且解释 JavaScript 是如何真正运行的。在了解这些细节之后,你将能够写出能够适宜地利用提供的 API 的更好的,非阻塞的 app。
如果对于 JavaScript 来说还不是很了解,这篇博文将会帮助你理解为什么 JavaScript 和别的语言相比如此“奇怪”。
如果你是一个有经验的 JavaScript 开发者,希望这篇文章能够让你对你每天使用的 JavaScript Runtime 是如何真正工作的。
最流行的 JavaScript 引擎的例子之一就是谷歌的 V8 引擎。比如 Chrome 以及 Node.js 内部就是使用 V8 引擎。下面是一个简单的视图示例:
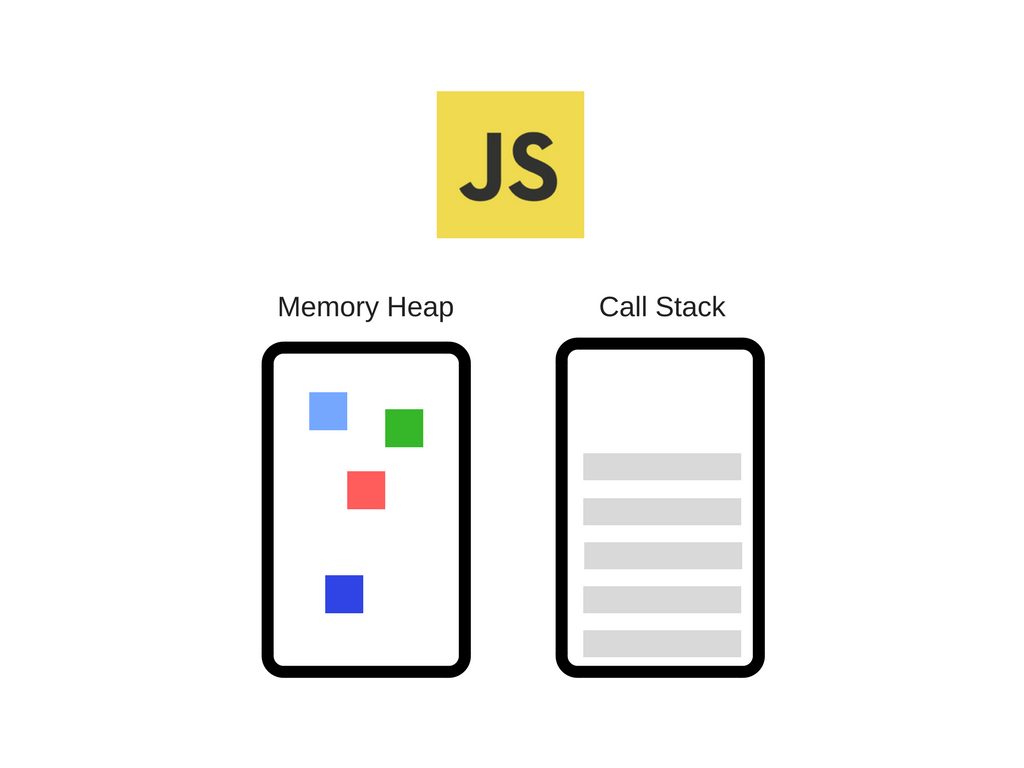
引擎主要由两个部分组成:
- 内存堆——这是内存分配发生的地方
- 回调——这是你代码执行时的栈帧。
有很多浏览器中的API几乎都被JavaScript开发者使用过(比如:'setTimeout')。然而这些API并不是由引擎提供的。
那么,它们是从哪来的呢?
事实证明这有一点复杂。
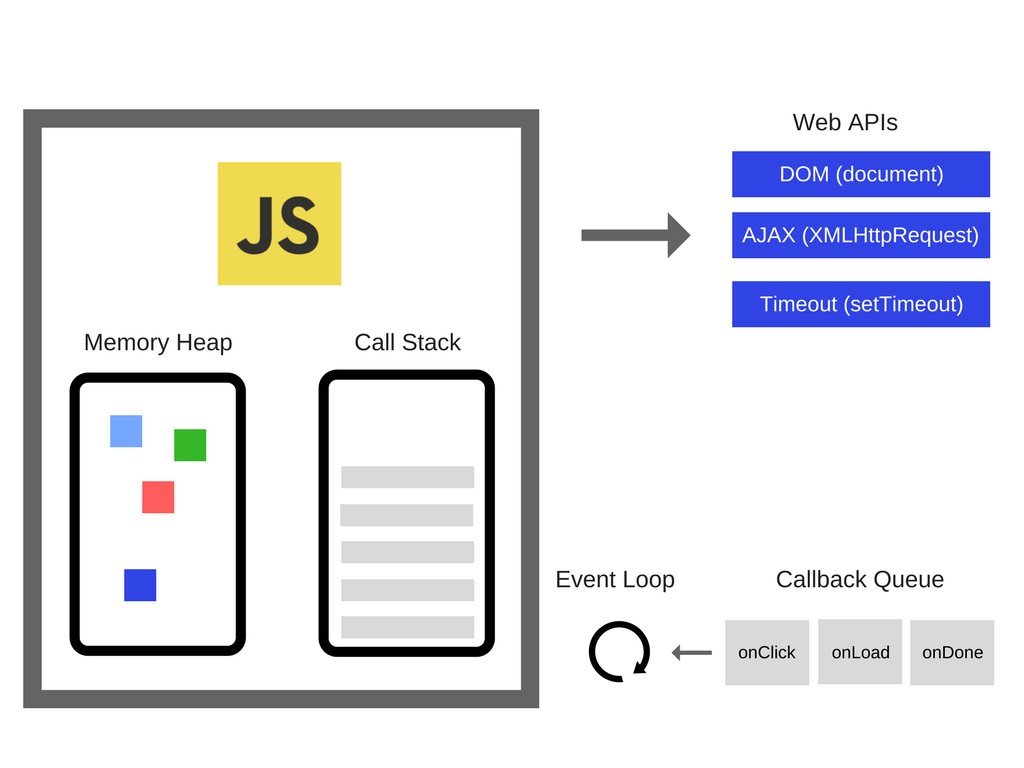
因此,虽然我们有引擎但实际上是有更多。我们有那些由浏览器提供的 Web API,像 DOM, AJAX, setTimeout 以及更多。
接着,我们还有非常流行的事件循环(event loo)以及回调队列(callback queue)。
JavaScript 是一种单线程的编程语言,这意味着它只拥有一个单独的调用栈。因此它一次只能做一件事情。
调用栈是一种数据结构记录着我们正在程序的什么地方。如果我们步入一个函数,我们就将这个函数放在栈的顶部。如果我们从一个函数返回,我们则是将这个函数从栈顶弹出。这就是这个栈所做的一切。
让我们看一个例子。参看如下代码:
function multiply(x, y) {
return x * y;
}
function printSquare(x) {
var s = multiply(x, x);
console.log(s);
}
printSquare(5);当引擎执行这段代码的时候,调用栈首先将会是空的。然后,将会按照以下步骤进行:
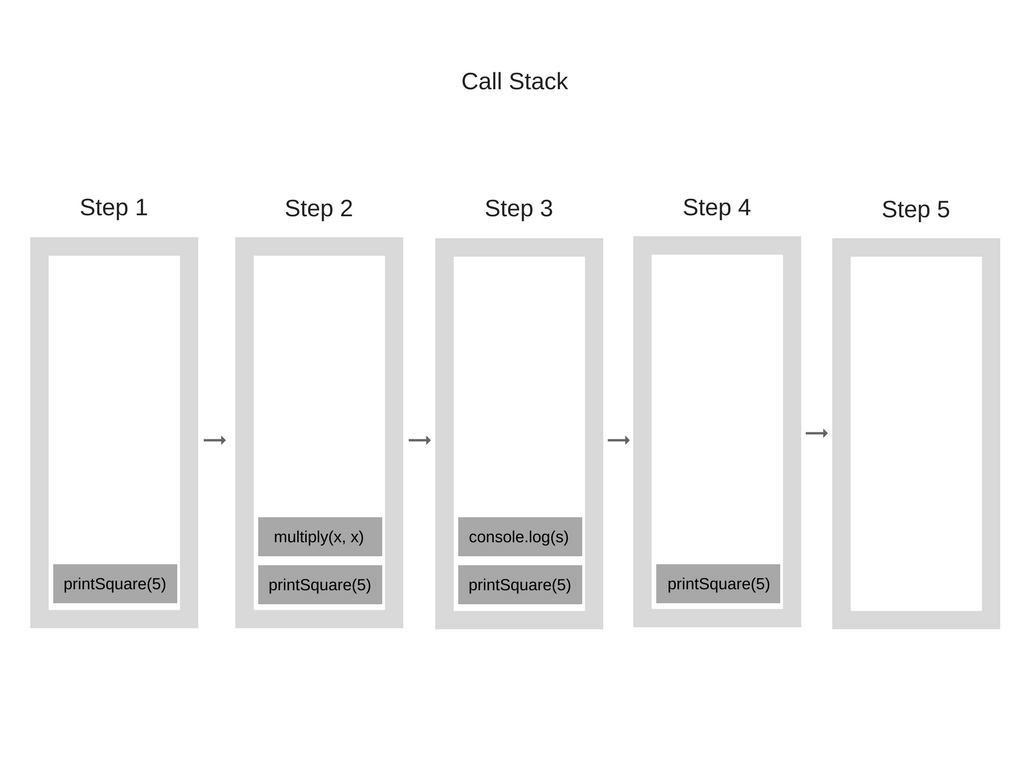
调用栈中的每一项都被称为栈帧(Stack Frame)。
并且这正是都异常被抛出的时候栈追踪是如何构建的——这基本就是异常发生时调用栈的状态。请看如下代码:
function foo() {
throw new Error('SessionStack will help you resolve crashes :)');
}
function bar() {
foo();
}
function start() {
bar();
}
start();如果这段代码在Chrome中执行(假设代码是在一个叫做foo.js的文件中),接下来的栈追踪将会产生:

“爆栈"——当你达到最大调用栈的大小的时候就会发生这种情况。并且这种情况很容易产生,特别是你没有对你的代码做全面的测试的时候。请看下面的示例代码:
function foo() {
foo();
}
foo();当引擎开始执行这段代码的时候,它一开始调用函数”foo“。然而,这个函数递归调用本身并且没有终止条件。因此在每一个执行的步骤中,相同的函数都会一次又一次地被添加到调用栈中。看起来就像这样:
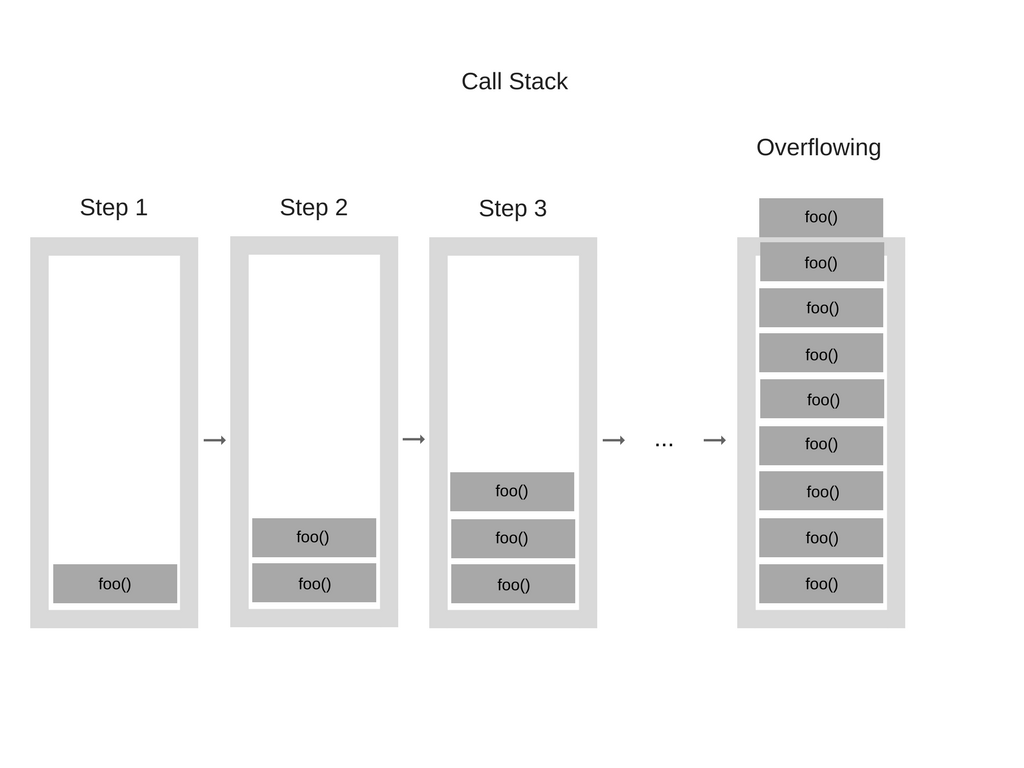
在某个点,然而函数调用的数量就超过调用栈的实际尺寸,那么浏览器就决定采取行动,抛出一个错误,看起来是这个样子的:

在单线程环境中运行代码可能相当容易因为你不需要处理多线程环境中复杂的情形——比如,死锁。
但是在单线程环境中也可能遇到种种限制。因为 JavaScript 具有一个单独的调用栈,当事情变得缓慢的时候到底发生了什么?
当你的函数调用在调用栈中花了大量的时间来进行到底发生了什么?比如,想象一下假如你想在浏览器中使用 JavaScript 来做一些复杂的图像转换。
你可能会问——为什么这也会是一个问题?问题是尽管调用栈具有函数来执行,但是浏览器实施中不能做任何其他的事——它被阻塞了。这意味着浏览器不能渲染,它不能运行其他的代码,它就是歇菜了。如果你希望你的 app 能够具有流畅的 UI 的时候就会产生问题。
并且这不是唯一的问题。一旦你的浏览器开始处理调用栈中的大量任务,他将在很长时间内都无法响应。大多数浏览器通过抛出错误来采取行动,询问你是否想中止网页。
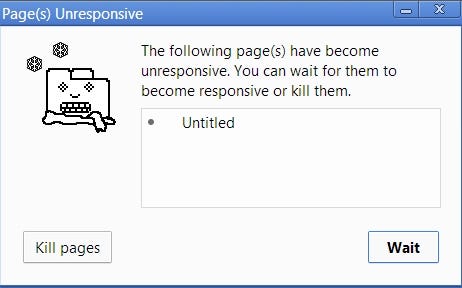
现在,这并不是一种最好的用户体验,是不是?
因此,我们如何在不阻塞UI并且让浏览器保持响应的情况下执行大量的代码?解决方案就是异步回调。
这个将会在”JavaScript是如何工作的"的第二部分进一步解释。
同时,如果你很难在你的JavaScript重现并且理解问题的时候,可以看看 SessionStack。SessionStack记录了你的web应用中的一切:所有的DOM变化,用户交互,JavaScript异常,栈追踪,失败的网络请求以及调试消息。
使用 SessionStack,你可以重现你的web应用中的问题就像录像一样,并且可以看到用户交互的一切。
现在有一个免费的计划能够允许你可以开始免费试用