| title | date | order | categories | tags | permalink | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
Elasticsearch 简介 |
2022-02-22 13:01:01 -0800 |
3 |
|
|
/pages/0fb506/ |
Elasticsearch 是一个基于 Lucene 的搜索和数据分析工具,它提供了一个分布式服务。Elasticsearch 是遵从 Apache 开源条款的一款开源产品,是当前主流的企业级搜索引擎。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
- 维基百科使用 Elasticsearch 提供全文搜索并高亮关键字,以及**输入实时搜索(search-as-you-type)和搜索纠错(did-you-mean)**等搜索建议功能。
- 英国卫报使用 Elasticsearch 结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
- StackOverflow 结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
- Github 使用 Elasticsearch 检索 1300 亿行的代码。
- 分布式的实时文件存储,每个字段都被索引并可被搜索;
- 分布式的实时分析搜索引擎;
- 可弹性扩展到上百台服务器规模,处理 PB 级结构化或非结构化数据;
- 开箱即用(安装即可使用),它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。只需很少的学习既可在生产环境中使用。
-
2010 年 2 月 8 日,Elasticsearch 第一个公开版本发布。
-
2010 年 5 月 14 日,发布第一个具有里程碑意义的初始版本 0.7.0 ,具有如下特征:
-
Zen Discovery 自动发现模块;
- 支持 Groovy Client;
-
简单的插件管理机制;
- 更好地支持 icu 分词器;
-
更多的管理 api。
-
2013 年初,GitHub 抛弃了 Solr,采取 ElasticSearch 来做其 PB 级的搜索。
-
2014 年 2 月 14 日,发布 1.0.0 版本,增加如下重要特性:
-
支持 Snapshot/Restore API 备份恢复 API;
- 支持聚合分析 Aggregations;
-
支持 cat api;
- 支持断路器;
-
引入 Doc values。
-
2015 年 10 月 28 日,发布 2.0.0 版本,有如下重要特性:
-
增加了 Pipleline Aggregations;
- query/filter 查询合并,都合并到 query 中,根据不同的上下文执行不同的查询;
-
压缩存储可配置;
- Rivers 模块被移除;
-
Multicast 组播发现被移除,成为一个插件,生产环境必须配置单播地址。
-
2016 年 10 月 26 日,发布 5.0.0 版本,有如下重大特性变化:
-
Lucene 6.x 的支持,磁盘空间少一半;索引时间少一半;查询性能提升 25%;支持 IPV6;
- Internal Engine 级别移除了用于避免同一文档并发更新的竞争锁,带来 15%-20% 的性能提升;
-
Shrink API,它可将分片数进行收缩成它的因数,如之前你是 15 个分片,你可以收缩成 5 个或者 3 个又或者 1 个,那么我们就可以想象成这样一种场景,在写入压力非常大的收集阶段,设置足够多的索引,充分利用 shard 的并行写能力,索引写完之后收缩成更少的 shard,提高查询性能;
- 提供了第一个 Java 原生的 REST 客户端 SDK;
-
IngestNode,之前如果需要对数据进行加工,都是在索引之前进行处理,比如 logstash 可以对日志进行结构化和转换,现在直接在 es 就可以处理了;
- 提供了 Painless 脚本,代替 Groovy 脚本;
- 移除 site plugins,就是说 head、bigdesk 都不能直接装 es 里面了,不过可以部署独立站点(反正都是静态文件)或开发 kibana 插件;
- 新增 Sliced Scroll 类型,现在 Scroll 接口可以并发来进行数据遍历了。每个 Scroll 请求,可以分成多个 Slice 请求,可以理解为切片,各 Slice 独立并行,利用 Scroll 重建或者遍历要快很多倍;
- 新增了 Profile API;
- 新增了 Rollover API;
- 新增 Reindex;
- 引入新的字段类型 Text/Keyword 来替换 String;
- 限制索引请求大小,避免大量并发请求压垮 ES;
- 限制单个请求的 shards 数量,默认 1000 个。
-
2017 年 8 月 31 日,发布 6.0.0 版本,具有如下重要特性:
-
稀疏性 Doc Values 的支持;
- Index Sorting,即索引阶段的排序;
-
顺序号的支持,每个 es 的操作都有一个顺序编号(类似增量设计);
- 无缝滚动升级;
-
从 6.0 开始不支持一个 index 里面存在多个 type;
- Index-template inheritance,索引版本的继承,目前索引模板是所有匹配的都会合并,这样会造成索引模板有一些冲突问题, 6.0 将会只匹配一个,索引创建时也会进行验证;
- Load aware shard routing, 基于负载的请求路由,目前的搜索请求是全节点轮询,那么性能最慢的节点往往会造成整体的延迟增加,新的实现方式将基于队列的耗费时间自动调节队列长度,负载高的节点的队列长度将减少,让其他节点分摊更多的压力,搜索和索引都将基于这种机制;
- 已经关闭的索引将也支持 replica 的自动处理,确保数据可靠。
-
2019 年 4 月 10 日,发布 7.0.0 版本,具有如下重要特性:
-
集群连接变化:TransportClient 被废弃,es7 的 java 代码,只能使用 restclient;对于 java 编程,建议采用 High-level-rest-client 的方式操作 ES 集群;
- ES 程序包默认打包 jdk:7.x 版本的程序包大小变成 300MB+,对比 6.x,包大了 200MB+,这正是 JDK 的大小;
-
采用基于 Lucene 9.0;
- 正式废除单个索引下多 Type 的支持,es6 时,官方就提到了 es7 会删除 type,并且 es6 时,已经规定每一个 index 只能有一个 type。在 es7 中,使用默认的 _doc 作为 type,官方说在 8.x 版本会彻底移除 type。api 请求方式也发送变化,如获得某索引的某 ID 的文档:GET index/_doc/id 其中 index 和 id 为具体的值;
-
引入了真正的内存断路器,它可以更精准地检测出无法处理的请求,并防止它们使单个节点不稳定;
- Zen2 是 Elasticsearch 的全新集群协调层,提高了可靠性、性能和用户体验,变得更快、更安全,并更易于使用。
下列有一些概念是 Elasticsearch 的核心。从一开始就理解这些概念将极大地帮助简化学习 Elasticsearch 的过程。
Elasticsearch 是一个近乎实时的搜索平台。这意味着从索引文档到可搜索文档的时间有一点延迟(通常是一秒)。
索引在不同语境,有着不同的含义
- 索引(名词):一个 索引 类似于传统关系数据库中的一个 数据库 ,是一个存储关系型文档的容器。 索引 (index) 的复数词为 indices 或 indexes 。索引实际上是指向一个或者多个物理分片的逻辑命名空间 。
- 索引(动词):索引一个文档 就是存储一个文档到一个 索引 (名词)中以便被检索和查询。这非常类似于 SQL 语句中的
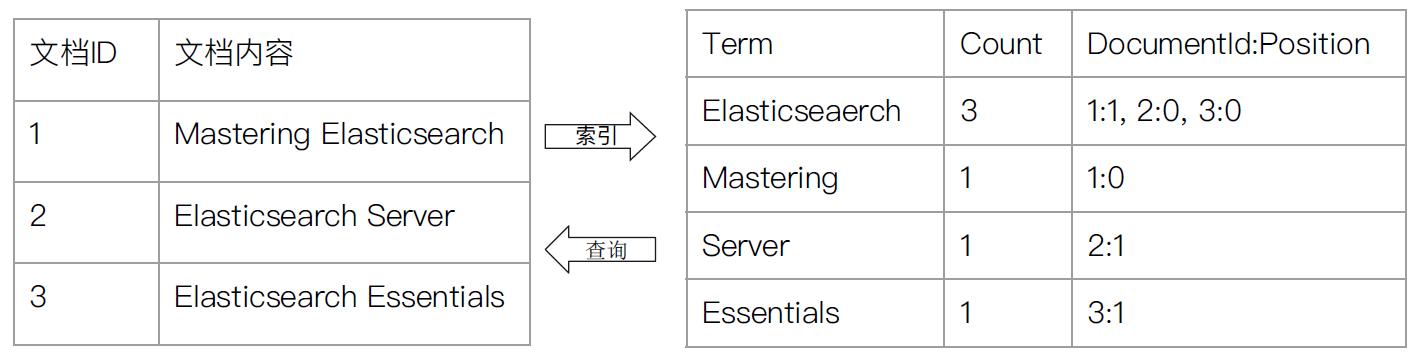
INSERT关键词,除了文档已存在时,新文档会替换旧文档情况之外。 - 倒排索引:关系型数据库通过增加一个索引比如一个 B 树索引到指定的列上,以便提升数据检索速度。Elasticsearch 和 Lucene 使用了一个叫做 倒排索引 的结构来达到相同的目的。
索引的 Mapping 和 Setting
Mapping定义文档字段的类型Setting定义不同的数据分布
示例:
{
"settings": { ... any settings ... },
"mappings": {
"type_one": { ... any mappings ... },
"type_two": { ... any mappings ... },
...
}
}
index template(索引模板)帮助用户设定 Mapping 和 Setting,并按照一定的规则,自动匹配到新创建的索引之上。
- 模板仅在一个索引被创建时,才会产生作用。修改模板不会影响已创建的索引。
- 你可以设定多个索引模板,这些设置会被 merge 在一起。
- 你可以指定 order 的数值,控制 merge 的过程。
当新建一个索引时
- 应用 ES 默认的 Mapping 和 Setting
- 应用 order 数值低的 index template 中的设定
- 应用 order 数值高的 index template 中的设定,之前的设定会被覆盖
- 应用创建索引是,用户所指定的 Mapping 和 Setting,并覆盖之前模板中的设定。
示例:创建默认索引模板
PUT _template/template_default
{
"index_patterns": ["*"],
"order": 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT /_template/template_test
{
"index_patterns": ["test*"],
"order": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 2
},
"mappings": {
"date_detection": false,
"numeric_detection": true
}
}
# 查看索引模板
GET /_template/template_default
GET /_template/temp*
#写入新的数据,index以test开头
PUT testtemplate/_doc/1
{
"someNumber": "1",
"someDate": "2019/01/01"
}
GET testtemplate/_mapping
GET testtemplate/_settings
PUT testmy
{
"settings":{
"number_of_replicas":5
}
}
PUT testmy/_doc/1
{
"key": "value"
}
GET testmy/_settings
DELETE testmy
DELETE /_template/template_default
DELETE /_template/template_test- 根据 ES 识别的数据类型,结合字段名称,来动态设定字段类型
- 所有的字符串类型都设定成 Keyword,或者关闭 keyword 字段。
- is 开头的字段都设置成 boolean
- long_ 开头的都设置成 long 类型
- dynamic template 是定义在某个索引的 Mapping 中
- template 有一个名称
- 匹配规则是一个数组
- 为匹配到字段设置 Mapping
示例:
#Dynaminc Mapping 根据类型和字段名
DELETE my_index
PUT my_index/_doc/1
{
"firstName": "Ruan",
"isVIP": "true"
}
GET my_index/_mapping
DELETE my_index
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean": {
"match_mapping_type": "string",
"match": "is*",
"mapping": {
"type": "boolean"
}
}
},
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
GET my_index/_mapping
DELETE my_index
#结合路径
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
GET my_index/_mapping
PUT my_index/_doc/1
{
"name": {
"first": "John",
"middle": "Winston",
"last": "Lennon"
}
}
GET my_index/_search?q=full_name:John
DELETE my_indextype 是一个逻辑意义上的分类或者叫分区,允许在同一索引中建立多个 type。本质是相当于一个过滤条件,高版本将会废弃 type 概念。
6.0.0 版本及之后,废弃 type
Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位。
Elasticsearch 使用 JSON 作为文档的序列化格式。
在索引/类型中,可以根据需要存储任意数量的文档。
每个文档都有一个 Unique ID
- 用户可以自己指定
- 或通过 Elasticsearch 自动生成
一个文档不仅仅包含它的数据 ,也包含元数据 —— 有关文档的信息。
_index:文档在哪存放_type:文档表示的对象类别_id:文档唯一标识_source:文档的原始 Json 数据_all:整合所有字段内容到该字段,已被废除_version:文档的版本信息_score:相关性打分
示例:
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": ["sports", "music"]
}
}一个运行中的 Elasticsearch 实例称为一个节点。
Elasticsearch 实例本质上是一个 Java 进程。一台机器上可以运行多个 Elasticsearch 进程,但是生产环境建议一台机器上只运行一个 Elasticsearch 进程
每个节点都有名字,通过配置文件配置,或启动时通过 -E node.name=node1 指定。
每个节点在启动后,会分配一个 UID,保存在 data 目录下。
- 主节点(master node):每个节点都保存了集群的状态,只有 master 节点才能修改集群的状态信息(保证数据一致性)。集群状态,维护了以下信息:
- 所有的节点信息
- 所有的索引和其相关的 mapping 和 setting 信息
- 分片的路由信息
- 候选节点(master eligible node):master eligible 节点可以参加选主流程。第一个启动的节点,会将自己选举为 mater 节点。
- 每个节点启动后,默认为 master eligible 节点,可以通过配置
node.master: false禁止
- 每个节点启动后,默认为 master eligible 节点,可以通过配置
- 数据节点(data node):负责保存分片数据。
- 协调节点(coordinating node):负责接收客户端的请求,将请求分发到合适的接地那,最终把结果汇集到一起。每个 Elasticsearch 节点默认都是协调节点(coordinating node)。
- 冷/热节点(warm/hot node):针对不同硬件配置的数据节点(data node),用来实现 Hot & Warm 架构,降低集群部署的成本。
- 机器学习节点(machine learning node):负责执行机器学习的 Job,用来做异常检测。
| 配置参数 | 默认值 | 说明 |
|---|---|---|
| node.master | true | 是否为主节点 |
| node.data | true | 是否为数据节点 |
| node.ingest | true | |
| node.ml | true | 是否为机器学习节点(需要开启 x-pack) |
建议
开发环境中一个节点可以承担多种角色。但是,在生产环境中,节点应该设置为单一角色。
拥有相同 cluster.name 配置的 Elasticsearch 节点组成一个集群。 cluster.name 默认名为 elasticsearch,可以通过配置文件修改,或启动时通过 -E cluster.name=xxx 指定。
当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为主节点时,它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量增加,它也不会成为瓶颈。 任何节点都可以成为主节点。
作为用户,我们可以将请求发送到集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 集群健康 , 它在 status 字段中展示为 green 、 yellow 或者 red 。
在一个不包含任何索引的空集群中,它将会有一个类似于如下所示的返回内容:
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 5,
"active_shards" : 5,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}status 字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
green:所有的主分片和副本分片都正常运行。yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行。red:有主分片没能正常运行。
索引实际上是指向一个或者多个物理分片的逻辑命名空间 。
一个分片是一个底层的工作单元 ,它仅保存了全部数据中的一部分。一个分片可以视为一个 Lucene 的实例,并且它本身就是一个完整的搜索引擎。 我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
分片分为主分片(Primary Shard)和副分片(Replica Shard)。
主分片:用于解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内不同节点上。
- 索引内任意一个文档都归属于一个主分片。
- 主分片数在索引创建时指定,后序不允许修改,除非 Reindex
副分片(Replica Shard):用于解决数据高可用的问题。副分片是主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
- 副分片数可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
对于生产环境中分片的设定,需要提前做好容量规划
分片数过小
- 无法水平扩展
- 单个分片的数量太大,导致数据重新分配耗时
分片数过大
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单节点上过多的分片,会导致资源浪费,同时也会影响性能
副本主要是针对主分片(Shards)的复制,Elasticsearch 中主分片可以拥有 0 个或多个的副本。
副本分片的主要目的就是为了故障转移。
分片副本很重要,主要有两个原因:
- 它在分片或节点发生故障时提供高可用性。因此,副本分片永远不会在与其复制的主分片相同的节点;
- 副本分片也可以接受搜索的请求,可以并行搜索,从而提高系统的吞吐量。
每个 Elasticsearch 分片都是 Lucene 索引。单个 Lucene 索引中可以包含最大数量的文档。截止 LUCENE-5843,限制是 2,147,483,519(=
Integer.MAX_VALUE- 128)文档。您可以使用_cat/shardsAPI 监控分片大小。