
MAE
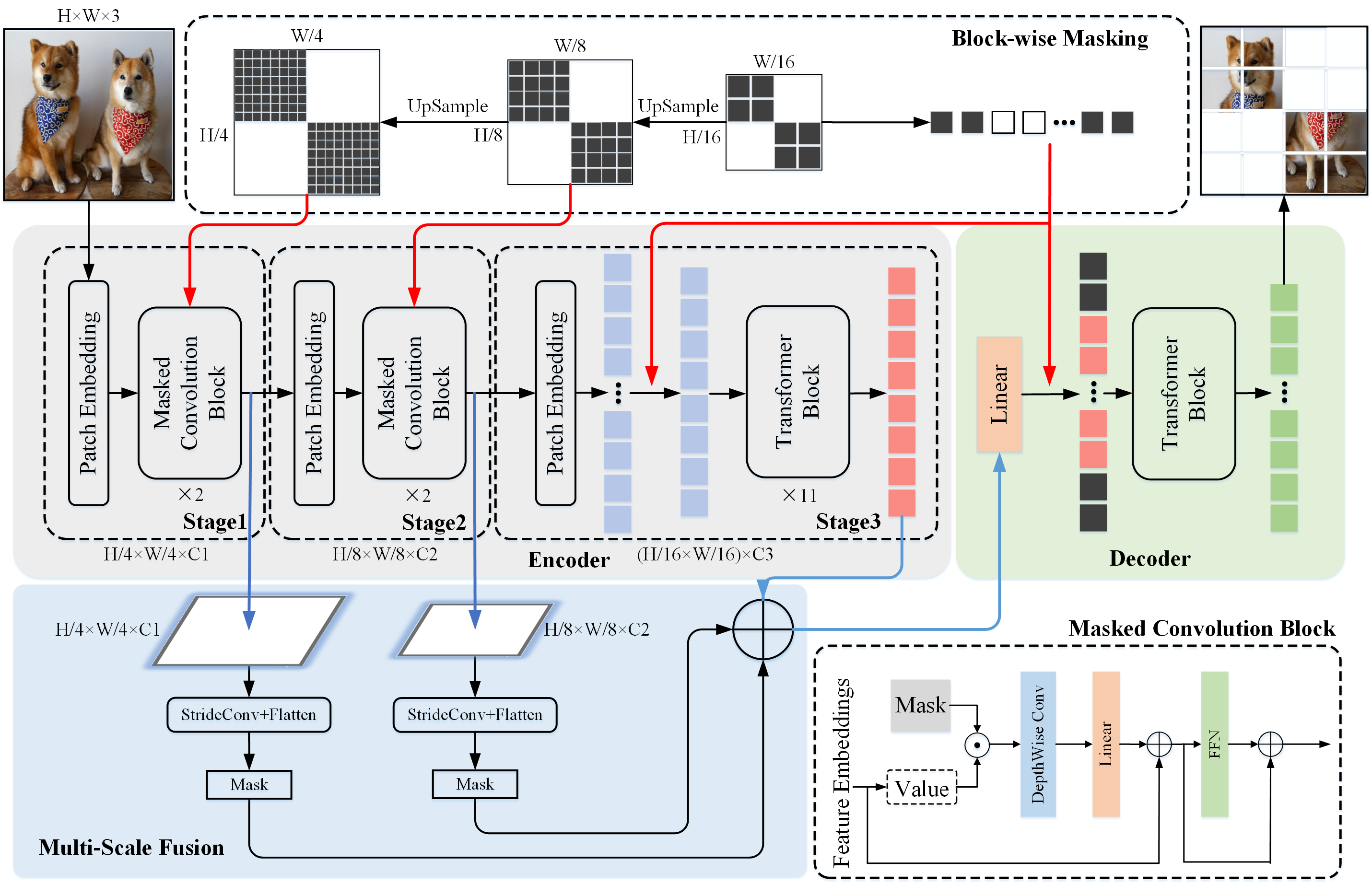
ConvMAE
This is a PaddlePaddle/GPU re-implementation of the paper Masked Autoencoders Are Scalable Vision Learners and ConvMAE: Masked Convolution Meets Masked Autoencoders
To enjoy some new features, PaddlePaddle 2.4 is required. For more installation tutorials refer to installation.md
Prepare the data into the following directory:
dataset/
└── ILSVRC2012
├── train
└── val
#unset PADDLE_TRAINER_ENDPOINTS
#export PADDLE_NNODES=4
#export PADDLE_MASTER="10.67.228.16:12538"
#export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
#export PADDLE_JOB_ID=MAE
# If you use single node
# batch_size 64, ACCUM_ITER=8, effective batch size: 4096
# batch_size 256, ACCUM_ITER=2, effective batch size: 4096
# 4 nodes for pretrain
ACCUM_ITER=1
IMAGENET_DIR=./dataset/ILSVRC2012/
python -m paddle.distributed.launch \
--nnodes=$PADDLE_NNODES \
--master=$PADDLE_MASTER \
--devices=$CUDA_VISIBLE_DEVICES \
main_pretrain.py \
--accum_iter $ACCUM_ITER \
--batch_size 128 \
--model mae_vit_base_patch16 \
--norm_pix_loss \
--mask_ratio 0.75 \
--epochs 1600 \
--warmup_epochs 40 \
--blr 1.5e-4 --weight_decay 0.05 \
--data_path ${IMAGENET_DIR}
- Here the effective batch size is 128 (
batch_sizeper gpu) * 4 (nodes) * 8 (gpus per node) = 4096. If memory or # gpus is limited, use--accum_iterto maintain the effective batch size, which isbatch_size(per gpu) *nodes* 8 (gpus per node) *accum_iter. blris the base learning rate. The actuallris computed by the linear scaling rule:lr=blr* effective batch size / 256.- Here we use
--norm_pix_lossas the target for better representation learning. To train a baseline model (e.g., for visualization), use pixel-based construction and turn off--norm_pix_loss. - Training time is ~56h in 32 A100(40G) GPUs (1600 epochs).
To train ViT-Base or ViT-Huge, set --model mae_vit_base_patch16 or --model mae_vit_huge_patch14.
| ViT-Base | ViT-Large | ViT-Huge | |
|---|---|---|---|
| epochs | 1600 | 1600 | 1600 |
| pre-trained checkpoint | download | - | - |
#unset PADDLE_TRAINER_ENDPOINTS
#export PADDLE_NNODES=4
#export PADDLE_MASTER="10.67.123.16:12538"
#export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
#export PADDLE_JOB_ID=MAE
# batch_size 32, ACCUM_ITER=4, effective batch size: 1024
# batch_size 128, ACCUM_ITER=1, effective batch size: 1024
# 4 nodes finetune setting
ACCUM_ITER=1
PRETRAIN_CHKPT='output_dir/checkpoint-1599.pd'
IMAGENET_DIR=./dataset/ILSVRC2012/
python -m paddle.distributed.launch \
--nnodes=$PADDLE_NNODES \
--master=$PADDLE_MASTER \
--devices=$CUDA_VISIBLE_DEVICES \
main_finetune.py \
--accum_iter $ACCUM_ITER \
--batch_size 128 \
--model maevit_base_patch16 \
--finetune ${PRETRAIN_CHKPT} \
--epochs 100 \
--blr 5e-4 --layer_decay 0.65 \
--weight_decay 0.05 --drop_path 0.1 --reprob 0.25 --mixup 0.8 --cutmix 1.0 \
--dist_eval --data_path ${IMAGENET_DIR}
| ViT-Base | ViT-Large | ViT-Huge | |
|---|---|---|---|
| official (PyTorch/GPU) | 83.664 | 85.952 | 86.928 |
| official rerun (PyTorch/GPU) | 83.36 | - | - |
| this repo (Paddle/GPU) | 83.34 | - | - |
| checkpoint | download | - | - |
#unset PADDLE_TRAINER_ENDPOINTS
#export PADDLE_NNODES=4
#export PADDLE_MASTER="10.67.123.16:12538"
#export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
#export PADDLE_JOB_ID=MAE
# batch_size 512, ACCUM_ITER=4, effective batch size: 16384
# 4 nodes finetune setting
ACCUM_ITER=1
PRETRAIN_CHKPT='output_dir/checkpoint-1599.pd'
IMAGENET_DIR=./dataset/ILSVRC2012/
python -m paddle.distributed.launch \
--nnodes=$PADDLE_NNODES \
--master=$PADDLE_MASTER \
--devices=$CUDA_VISIBLE_DEVICES \
main_linprobe.py \
--accum_iter $ACCUM_ITER \
--batch_size 512 \
--model maevit_base_patch16 \
--cls_token \
--finetune ${PRETRAIN_CHKPT} \
--epochs 90 \
--blr 0.1 \
--weight_decay 0.0 \
--dist_eval --data_path ${IMAGENET_DIR}
| ViT-Base | ViT-Large | ViT-Huge | |
|---|---|---|---|
| official (PyTorch/GPU) | 67.8 | 76.0 | 77.2 |
| official rerun (PyTorch/GPU) | 68.05 | - | - |
| this repo (Paddle/GPU) | 68.08 | - | - |
| checkpoint | download | - | - |
To pretrain ConvMAE-Base with multi-node distributed training, run the following on 3 nodes with 8 GPUs each:
unset PADDLE_TRAINER_ENDPOINTS
export PADDLE_NNODES=3
export PADDLE_MASTER="10.67.228.16:12538"
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export PADDLE_JOB_ID=ConvMAE
# 3 nodes for pretrain
ACCUM_ITER=1
IMAGENET_DIR=./dataset/ILSVRC2012/
python -m paddle.distributed.launch \
--nnodes=$PADDLE_NNODES \
--master=$PADDLE_MASTER \
--devices=$CUDA_VISIBLE_DEVICES \
main_pretrain.py \
--accum_iter $ACCUM_ITER \
--batch_size 128 \
--model convmae_convvit_base_patch16 \
--norm_pix_loss \
--mask_ratio 0.75 \
--epochs 1600 \
--warmup_epochs 40 \
--blr 1.5e-4 --weight_decay 0.05 \
--data_path ${IMAGENET_DIR}
To finetune with multi-node distributed training, run the following on 4 nodes with 8 GPUs each:
#unset PADDLE_TRAINER_ENDPOINTS
#export PADDLE_NNODES=4
#export PADDLE_MASTER="10.67.228.16:12538"
#export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
#export PADDLE_JOB_ID=ConvMAE
# 4 nodes finetune setting
ACCUM_ITER=1
PRETRAIN_CHKPT='output_dir/checkpoint-1599.pd'
IMAGENET_DIR=./dataset/ILSVRC2012/
python -m paddle.distributed.launch \
--nnodes=$PADDLE_NNODES \
--master=$PADDLE_MASTER \
--devices=$CUDA_VISIBLE_DEVICES \
main_finetune.py \
--accum_iter $ACCUM_ITER \
--batch_size 32 \
--model convvit_base_patch16 \
--finetune ${PRETRAIN_CHKPT} \
--epochs 100 \
--blr 5e-4 --layer_decay 0.65 \
--weight_decay 0.05 --drop_path 0.1 --reprob 0.25 --mixup 0.8 --cutmix 1.0 \
--dist_eval --data_path ${IMAGENET_DIR}
To finetune with multi-node distributed training, run the following on 4 nodes with 8 GPUs each:
#unset PADDLE_TRAINER_ENDPOINTS
#export PADDLE_NNODES=4
#export PADDLE_MASTER="10.67.228.16:12538"
#export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
#export PADDLE_JOB_ID=ConvMAE
IMAGENET_DIR=./dataset/ILSVRC2012/
# 4 nodes finetune setting
ACCUM_ITER=1
PRETRAIN_CHKPT='./output_dir/checkpoint-1599.pd'
python -m paddle.distributed.launch \
--nnodes=$PADDLE_NNODES \
--master=$PADDLE_MASTER \
--devices=$CUDA_VISIBLE_DEVICES \
main_linprobe.py \
--accum_iter $ACCUM_ITER \
--batch_size 128 \
--model convvit_base_patch16 \
--global_pool \
--finetune ${PRETRAIN_CHKPT} \
--epochs 90 \
--blr 0.1 \
--weight_decay 0.0 \
--dist_eval --data_path ${IMAGENET_DIR}
| Model | Phase | Dataset | Epochs | GPUs | Img/sec | Top1 acc@1(%) | Official | Checkpoint | Log |
|---|---|---|---|---|---|---|---|---|---|
| ConvMAE-Base | pretrain | ImageNet2012 | 1600 | A100*N3C24 | 4984 | - | - | download | download |
| ConvViT-Base | finetune | ImageNet2012 | 100 | A100*N4C32 | 3927 | 85.0 | 85.0 | download | download |
| ConvViT-Base | linprobe | ImageNet2012 | 90 | A100*N4C32 | 16732 | 71.4 | 70.9 | download | download |
@Article{MaskedAutoencoders2021,
author = {Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll{\'a}r and Ross Girshick},
journal = {arXiv:2111.06377},
title = {Masked Autoencoders Are Scalable Vision Learners},
year = {2021},
}
@article{gao2022convmae,
title={ConvMAE: Masked Convolution Meets Masked Autoencoders},
author={Gao, Peng and Ma, Teli and Li, Hongsheng and Dai, Jifeng and Qiao, Yu},
journal={arXiv preprint arXiv:2205.03892},
year={2022}
}