PaddlePaddle reimplementation of Facebook's repository for ToMe that was released with the paper Token Merging: Your ViT but Faster.
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, Judy Hoffman.
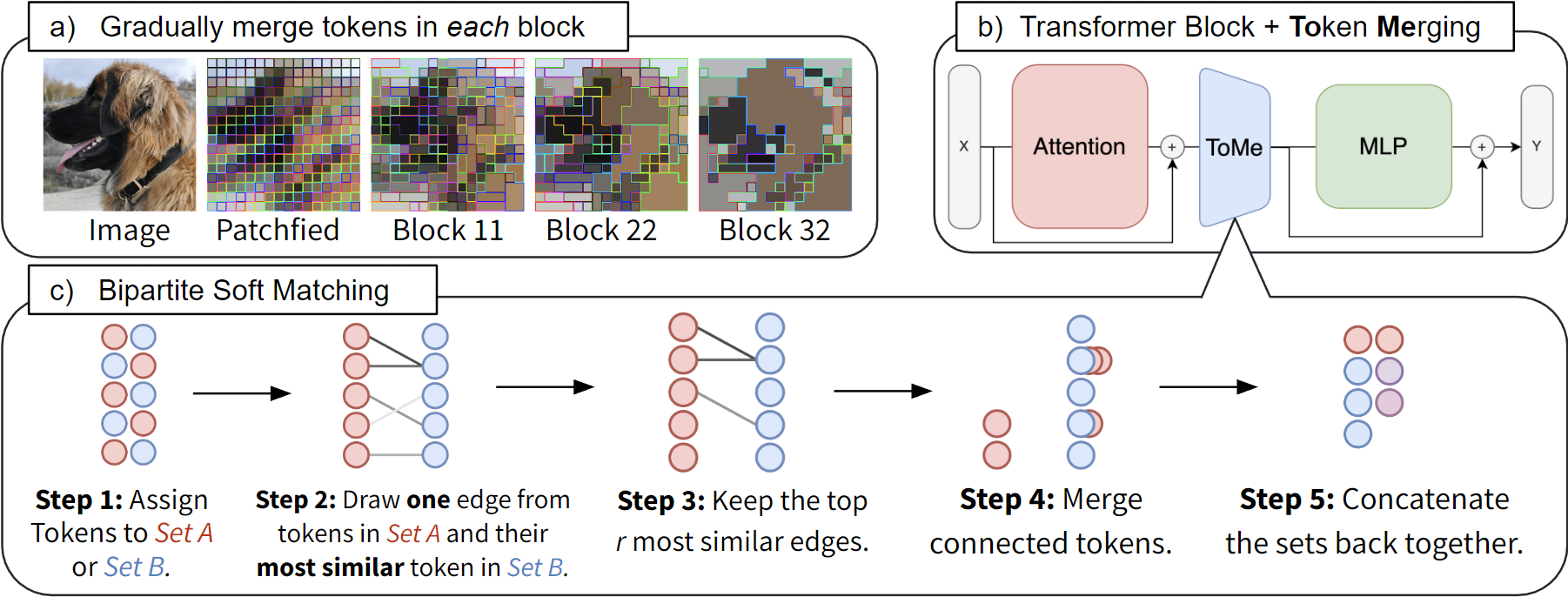
Token Merging (ToMe) allows you to take an existing Vision Transformer architecture and efficiently merge tokens inside of the network for 2-3x faster evaluation (see benchmark script). ToMe is tuned to seamlessly fit inside existing vision transformers, so you can use it without having to do additional training (see eval script). And if you do use ToMe during training, you can reduce the accuracy drop even further while also speeding up training considerably.

ToMe merges tokens based on their similarity, implicitly grouping parts of objects together. This is in contrast to token pruning, which only removes background tokens. ToMe can get away with reducing more tokens because we can merge redundant foreground tokens in addition to background ones. Visualization of merged tokens on ImageNet-1k val using a trained ViT-H/14 MAE model with ToMe. See this example for how to produce these visualizations. For more, see the paper appendix.
We provide a simple and fast running notebook, see validation_tome_vit.ipynb
We provide a simple patch method for easy use:
from plsc.models import vision_transformer
from plsc.models.utils import tome
# Create model and load a pretrained model.
model = vision_transformer.ViT_base_patch16_224()
model.load_pretrained('models/imagenet2012-ViT-B_16-224')
# Patch the model with ToMe.
tome.apply_patch(model)
# Set the number of tokens reduced per layer. See paper for details.
model.r = 16@inproceedings{bolya2022tome,
title={Token Merging: Your {ViT} but Faster},
author={Bolya, Daniel and Fu, Cheng-Yang and Dai, Xiaoliang and Zhang, Peizhao and Feichtenhofer, Christoph and Hoffman, Judy},
booktitle={International Conference on Learning Representations},
year={2023}
}